In the Eq. (1) 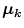 indicates the localization of the center or focal point for each
indicates the localization of the center or focal point for each 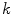 category;
category; 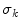 controls the volume of color space that is included in each
controls the volume of color space that is included in each 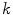 category and the function value
category and the function value 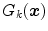 determines the membership of the color stimuli
determines the membership of the color stimuli 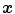 to a
to a 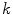 category. The
category. The 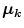 and
and 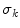 values are computed through a minimization of a functional described in [14] for each category, using the color points of the boundaries and the foci of the regions obtained in [4]. Once the parameters are known, one can assign a color category for any arbitrary color stimuli
values are computed through a minimization of a functional described in [14] for each category, using the color points of the boundaries and the foci of the regions obtained in [4]. Once the parameters are known, one can assign a color category for any arbitrary color stimuli 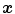 as follows:
as follows:
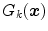 for
for 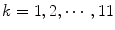 .
.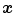 the color category or index that maximizes
the color category or index that maximizes 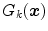 .
.The Lammens color categorization model is constructed not only in NPP color space, but also in the 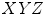 and
and 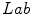 spaces. This proposal does not consider intensity and saturation modifiers and despite of its novelty, it has not been extensively applied yet.
spaces. This proposal does not consider intensity and saturation modifiers and despite of its novelty, it has not been extensively applied yet.
 64 pixel color patches were arranged into a 9
64 pixel color patches were arranged into a 9 6 matrix and were displayed to the subjects. The light gray was the display background. In the second experiment only one 200
6 matrix and were displayed to the subjects. The light gray was the display background. In the second experiment only one 200 200 pixel color patch was observed.
200 pixel color patch was observed.From these experiments, in [17] arrived at the following conclusions:
-
None of the subjects listed more than 14 color names during Color Listing Experiment. The eleven basic colors specified by Berlin and Kay were found in the color list. Beige, violet and cyan were also included by some of the subjects with less frequency. Modifiers for hue, saturation and luminance were not used for this color listing experiment. This stage in color naming was described as fundamental level: the color names are expressed using only generic hue or generic achromatic terms.
-
The subjects used almost similar vocabulary to describe image color composition in the Color Composition Experiment. Modifiers for hue, saturation and luminance were used to distinguish different types of the same hue. Although the images had rich color histograms, no more than 10 names were included in the color list. In this case, color naming can be classified in the coarse level, in which the color names are expressed using luminance and generic hue or luminance and generic achromatic term. Another level presented in the Color Composition Experiment was the medium level: color names are described adding the saturation modifiers to the coarse description.
-
The results obtained in the two color naming experiments were almost identical. The difference is explained by the use of different luminance modifiers. The same color is described by a different luminance modifier when it is displayed in a small and in a large window, i.e., the size of the color patches influences in the color naming decision by a subject. For this experiment the author classified the color vocabulary as minute level, in which the complete color information is given.
-
In general, well-defined color regions are easier to describe than dark regions, which, in general, exist due to shadows or due to illumination problems.
-
All experimentation confirmed that not all color terms included in the ISCC-NBS dictionary are well understood by the general public. For that reason Mojsilovic decided to use all prototype colors specified in ISCC-NBS dictionary [17], except those that were not perceived by the participants of the experiments. On the other hand, in order to reflect the participant decisions, some of the color names were changed. With all these considerations, a new color vocabulary was created in [17] for describing the color naming process.
A very interesting issue of the research is that they designed a metric in order to know the similarity of any arbitrary color point 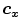 with respect to a color prototype
with respect to a color prototype 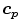 . The new metric, which is based on the findings from the experiment, is given by the following equation:
. The new metric, which is based on the findings from the experiment, is given by the following equation:
![$$\begin{aligned} D(\varvec{c_p},\varvec{c_x})=D_{Lab}(\varvec{c_p},\varvec{c_x})[1+k(D_{Lab}(\varvec{c_p},\varvec{c_x}))\triangle d(\varvec{c_p},\varvec{c_x})], \end{aligned}$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_Equ2.gif)
where 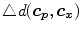 is a distance function in the
is a distance function in the 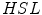 color space proposed in [17] and
color space proposed in [17] and 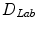 is a distance in the
is a distance in the 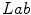 color space
color space
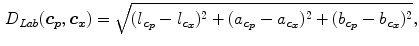
where 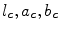 represent the components
represent the components  of the color
of the color 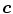 in the
in the 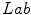 color space.
color space.
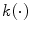 is a function which is introduced with the aim to avoid modifying distances between very close points in
is a function which is introduced with the aim to avoid modifying distances between very close points in 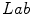 space and to control the amount of increase for large distance
space and to control the amount of increase for large distance 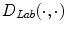 , the factor
, the factor 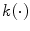 is defined as:
is defined as: 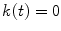 , if
, if 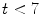 ,
, 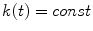 , if
, if 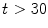 [17]. Observe that the Eq. (2) is a combination of distances of two spaces:
[17]. Observe that the Eq. (2) is a combination of distances of two spaces: 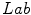 and
and 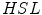 .
.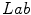 space. For validation purposes, the metric was compared with human observations arriving at
space. For validation purposes, the metric was compared with human observations arriving at 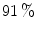 agreement.
agreement.-
10 subjects observed 422 color samples and they were asked to distribute 10 points among the 11 basic color categories taking in consideration the grade of belonging of the observed color sample to each of the basic color terms. When the subject was absolutely sure about the sample color name, 10 points were assigned to the corresponding category. The restriction for using only 11 color terms is justified by research in [5, 21].
-
For each sample, the scores were averaged and normalized to the
![$$[0,1]$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_IEq42.gif) interval. The experiment was performed twice for each subject. As a result of the color naming process, an experimental color descriptor,
interval. The experiment was performed twice for each subject. As a result of the color naming process, an experimental color descriptor, 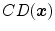 , is obtained for each sample:
, is obtained for each sample:
![$$\begin{aligned} CD(\varvec{x}) = [m_{{1}}(\varvec{x}), m_{{2}}(\varvec{x}),\cdots , m_{{11}}(\varvec{x}) ], \end{aligned}$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_Equ4.gif) (4)
(4)where
![$$m_{{k}}(\varvec{x}) \in [0,1] $$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_IEq44.gif) and
and 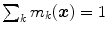 .
. 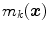 can be interpreted as the degree of membership of
can be interpreted as the degree of membership of 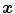 to the color category
to the color category 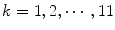 .
.
The results of the color naming experiment define the training set to find membership functions 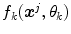 of the color fuzzy sets. In order to know the parameters,
of the color fuzzy sets. In order to know the parameters, 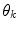 , of each membership function (model for each color category), the minimization of the following functional
, of each membership function (model for each color category), the minimization of the following functional
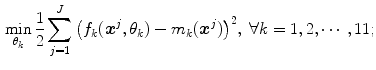
is carried out, see [2]. The previous functional, Eq. (5), represents the mean squared error between the membership values of the model 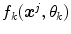 and the
and the 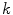 -th component
-th component 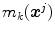 of the color descriptor obtained in the color naming experiment, Eq. (4);
of the color descriptor obtained in the color naming experiment, Eq. (4); 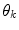 is the set of parameters of the model,
is the set of parameters of the model, 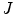 is the number of samples in the training set and
is the number of samples in the training set and 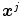 is the
is the 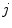 -th color sample of the training set. According to [2] the model
-th color sample of the training set. According to [2] the model 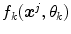 depends on the type of the color category (chromatic or achromatic).
depends on the type of the color category (chromatic or achromatic).
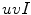 , whose first two components represent the color components and the third one the intensity. They carried out the experimental work in the
, whose first two components represent the color components and the third one the intensity. They carried out the experimental work in the 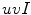 space and for comparison purposes they also employed the
space and for comparison purposes they also employed the 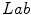 space. From the color naming data and data fitting process through an optimization algorithm they concluded that the Gaussian function is a good model, as a membership function, for achromatic categories. However, they found that the combination of sigmoid and Gaussian functions is an appropriate model for chromatic categories. They also concluded that the results obtained in the
space. From the color naming data and data fitting process through an optimization algorithm they concluded that the Gaussian function is a good model, as a membership function, for achromatic categories. However, they found that the combination of sigmoid and Gaussian functions is an appropriate model for chromatic categories. They also concluded that the results obtained in the 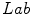 space were no better than those obtained in
space were no better than those obtained in 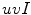 space.
space.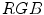 ,
, 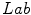 ,
, 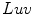 and
and 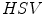 color spaces and concluded that the
color spaces and concluded that the 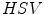 space had the best performance to detect similarity and difference between colors.
space had the best performance to detect similarity and difference between colors.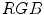 ,
, 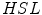 and
and 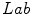 . Two ways to assign color names to individual pixel are considered [24]:
. Two ways to assign color names to individual pixel are considered [24]:
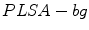 model: It is based only on the pixel value. The model is expressed as follows:
model: It is based only on the pixel value. The model is expressed as follows:
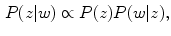
where 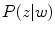 represents the probability of a color name
represents the probability of a color name 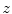 (color category) given a pixel
(color category) given a pixel 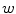 . The prior probability over the color names is taken to be uniform [24].
. The prior probability over the color names is taken to be uniform [24].
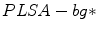 model: It takes into account the pixel
model: It takes into account the pixel 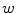 and some region
and some region 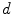 , around it. The Equation for the model is the following:
, around it. The Equation for the model is the following:
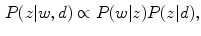
where 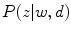 represents the probability of a color name
represents the probability of a color name 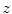 (color category) given a pixel
(color category) given a pixel 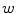 in a region
in a region 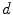 . The
. The 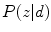 is estimated using an EM algorithm [11].
is estimated using an EM algorithm [11].
The experimental work considers data in three color spaces: 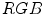 ,
, 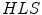 and
and 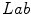 . According to the investigation, the
. According to the investigation, the 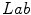 space slightly outperformed the others. Besides the PLSA method, the authors employed the Support Vector Machine algorithm [6].
space slightly outperformed the others. Besides the PLSA method, the authors employed the Support Vector Machine algorithm [6].
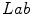 color space.
color space.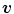 , with components
, with components 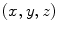 , in a given color space,
, in a given color space, 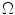 , a discrete probability distribution
, a discrete probability distribution ![$$\varvec{l}(\varvec{v}) = [l_{1}(\varvec{v}), \cdots , l_{K}(\varvec{v})]^T$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_IEq92.gif) where the component
where the component 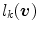 is interpreted as the probability of
is interpreted as the probability of 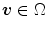 to belong to the color category
to belong to the color category 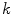 ,
, 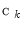 , given the color
, given the color 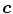 at
at 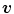 , denoted here as
, denoted here as 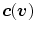 . Note that, the components of
. Note that, the components of 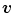 correspond to the color
correspond to the color 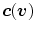 , i.e.,
, i.e., 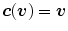 . Then,
. Then, 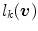 is defined as follows:
is defined as follows:
and represents the posterior probability of a voxel to belong to a color category. In [1] each category  is modeled as a linear combination of 3D quadratic splines
is modeled as a linear combination of 3D quadratic splines
where  are located in a node lattice in
are located in a node lattice in 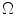 ,
, 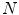 is the number of nodes in the lattice;
is the number of nodes in the lattice; 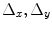 and
and 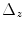 define the resolution of the node lattice;
define the resolution of the node lattice; 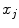 ,
, 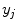 , and
, and 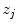 denote the coordinates of the
denote the coordinates of the 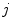 -th node,
-th node, 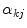 is the contribution of each spline function
is the contribution of each spline function 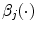 to each category
to each category 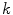 and
and 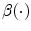 is the quadratic basis function defined in the following equation:
is the quadratic basis function defined in the following equation:
![$$\begin{aligned} \beta (x) =\left\{ \begin{array}{ll} \frac{1}{2}(-2x^{2}+1.5), &{} |x| \in \Big [ 0,\frac{1}{2}\Big ]; \;\\ \\ \frac{1}{2}(x^{2}-3|x|+2.25), &{} |x| \in \Big [\frac{1}{2},1.5 \Big ]; \\ \\ 0, &{} |x|\ge 1.5. \end{array} \right. \end{aligned}$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_Equ10.gif)
In order to determine 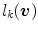 in (9) one needs to compute the parameters
in (9) one needs to compute the parameters 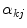 . Hence, the authors propose to minimize the following functional:
. Hence, the authors propose to minimize the following functional:
![$$\begin{aligned} \min _{\varvec{\alpha }_k} \sum _{\varvec{v} \in \fancyscript{D} } \Big [ l_k(\varvec{v})-\sum _{j=1}^N{\alpha _{kj}\beta _j(\varvec{v})}\Big ]^{2}+\tau \sum _{\langle m,n \rangle } {(\alpha _{km}-\alpha _{kn})^2}, \; \forall k \in \fancyscript{K}, \end{aligned}$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_Equ11.gif)
where ![$$\varvec{\alpha }_{k} = [ \alpha _{ki} ]_{i = 1,\cdots ,N}^T$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_IEq120.gif) ,
, 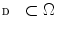 represents a voxel set for which
represents a voxel set for which 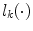 is known and
is known and 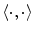 denotes a pair of neighboring splines. In this case,
denotes a pair of neighboring splines. In this case, 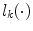 is obtained, for all voxels in
is obtained, for all voxels in 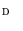 , through a color naming experiment based on isolated color patches. The second term in (11) controls the smoothness between spline coefficients,
, through a color naming experiment based on isolated color patches. The second term in (11) controls the smoothness between spline coefficients, 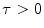 is a parameter that controls the smoothness level.
is a parameter that controls the smoothness level.
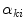 and setting the derivatives equal to zero, i.e.,
and setting the derivatives equal to zero, i.e.,
![$$\begin{aligned} -\sum _{ \varvec{v} \in \fancyscript{D} } \Big [ l_k(\varvec{v})-\sum _{j=1}^N \alpha _{kj}\beta _j(\varvec{v})\Big ] \beta _i(\varvec{v})+\tau \sum _{m \in \fancyscript{N}_i}(\alpha _{ki}-\alpha _{km}) = 0, \end{aligned}$$](/wp-content/uploads/2016/03/A308467_1_En_10_Chapter_Equ12.gif)
Related posts:
 to: On the von Kries Model: Estimation, Dependence on Light and Device, and Applications
to: On the von Kries Model: Estimation, Dependence on Light and Device, and Applications
 Saliency Evaluation for Video Game Design
Saliency Evaluation for Video Game Design
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


