where X is an m-by-n (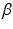 is a column vector of length n, and
is a column vector of length n, and 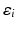 s (
s (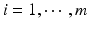 ) are identical and independently distributed (i.i.d.) variables following a Gaussian distribution
) are identical and independently distributed (i.i.d.) variables following a Gaussian distribution 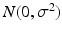 . In research applications, Y may be an fMRI time serials at a voxel location and X may be the design matrix of functional tasks, or in a tensor-based morphometry (TBM) study Y may be subjects’ Jacobian determinant at a voxel location and X may be a factor matrix of age, gender or disease states, etc. Please note:
. In research applications, Y may be an fMRI time serials at a voxel location and X may be the design matrix of functional tasks, or in a tensor-based morphometry (TBM) study Y may be subjects’ Jacobian determinant at a voxel location and X may be a factor matrix of age, gender or disease states, etc. Please note:
We assume that X is full column-rank so that the inverse of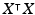 exists.
exists.
We assume that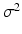 .
.
The maximum-likelihood and unbiased estimate of 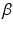 is
is
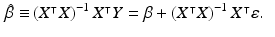 The residuals and the unbiased estimate of
The residuals and the unbiased estimate of 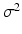 are
are
![$$\begin{aligned} {\left\{ \begin{array}{ll} \hat{\varepsilon } &{} \equiv Y-X\hat{\beta }=\left[ I-X\left( X^{\intercal }X\right) ^{-1}X^{\intercal }\right] \varepsilon ,\\ \hat{\sigma }^{2} &{} \equiv \frac{\hat{\varepsilon }^{\intercal }\hat{\varepsilon }}{df},\text { where }df=m-n. \end{array}\right. } \end{aligned}$$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_Equ4.gif) Let us focus on the probabilistic and geometric properties of
Let us focus on the probabilistic and geometric properties of 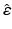 .
.
is are.1.
It follows a 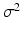 -variance isotropic multi-variate Gaussian distribution embedded in the null space of X’s columns. More specifically, there exists an m-by-df matrix Z which satisfies
-variance isotropic multi-variate Gaussian distribution embedded in the null space of X’s columns. More specifically, there exists an m-by-df matrix Z which satisfies 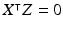 and
and 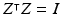 , such that
, such that 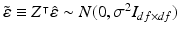 and
and 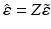 .
.
-variance isotropic multi-variate Gaussian distribution embedded in the null space of X’s columns. More specifically, there exists an m-by-df matrix Z which satisfies and , such that and .2.
It is independent of 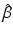 .
.
.3.
Its normalized vector 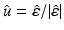 uniformly distributes on a unit hyper-sphere in the null space of X’s columns, independent of
uniformly distributes on a unit hyper-sphere in the null space of X’s columns, independent of 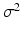 and
and 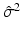 .
.
uniformly distributes on a unit hyper-sphere in the null space of X’s columns, independent of and .Property 1 is the most insightful and it easily derives properties 2 and 3. We outline its proof as follows:
1.
Because X is a full column-rank m-by-n matrix, its column null space has 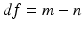 dimensions.
dimensions.
dimensions.2.
Define Z as an m-by-df matrix whose columns are a set orthonormal bases of the null space of X’s columns. By definition, Z satisfies 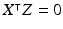 and
and 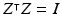 .
.
and .3.
Define 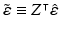 , then this df-element random vector follows a Gaussian distribution
, then this df-element random vector follows a Gaussian distribution 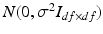 , because:
, because:
, then this df-element random vector follows a Gaussian distribution , because:
![$$\tilde{\varepsilon }\equiv Z^{\intercal }\hat{\varepsilon }=Z^{\intercal }\left[ I-X\left( X^{\intercal }X\right) ^{-1}X^{\intercal }\right] \varepsilon =Z^{\intercal }\varepsilon $$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq27.gif) , as a linear combination of
, as a linear combination of 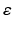 , follows a multi-variate Gaussian distribution;
, follows a multi-variate Gaussian distribution;
The expected value of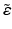 is
is 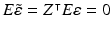 ;
;
The variance of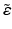 is
is ![$$E\tilde{\varepsilon }\tilde{\varepsilon }^{\intercal }=E\left[ Z^{\intercal }\varepsilon \varepsilon ^{\intercal }Z\right] =Z^{\intercal }E\left[ \varepsilon \varepsilon ^{\intercal }\right] Z=I\sigma ^{2}$$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq32.gif) .
.
4.
Z also satisfies 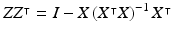 because:
because:
because:
Both![$$ZZ^{\intercal }\left[ \begin{array}{cc} X&Z\end{array}\right] $$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq34.gif) and
and ![$$\left[ I-X\left( X^{\intercal }X\right) ^{-1}X^{\intercal }\right] \left[ \begin{array}{cc} X&Z\end{array}\right] $$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq35.gif) equal
equal ![$$\left[ \begin{array}{cc} 0&Z\end{array}\right] $$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq36.gif) ;
;
![$$\left[ \begin{array}{cc} X&Z\end{array}\right] $$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq37.gif) is a full-rank m-by-m matrix so its inverse exists;
is a full-rank m-by-m matrix so its inverse exists;
Both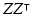 and
and ![$$\left[ I-X\left( X^{\intercal }X\right) ^{-1}X^{\intercal }\right] $$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq39.gif) equal
equal ![$$\left[ \begin{array}{cc} 0&Z\end{array}\right] \left[ \begin{array}{cc} X&Z\end{array}\right] ^{-1}$$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_IEq40.gif) .
.
5.
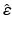 equals
equals 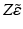 because
because
![$$\begin{aligned} \hat{\varepsilon }&=\left[ I-X\left( X^{\intercal }X\right) ^{-1}X^{\intercal }\right] \varepsilon =ZZ^{\intercal }\varepsilon =Z\tilde{\varepsilon }. \end{aligned}$$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_Equ5.gif)
equals because2.2 Weighted FDR in Volume
Let 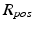 denote the detected region,
denote the detected region, 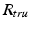 the underlying truth, and
the underlying truth, and 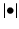 the volume of a region. The volume-based FDR is defined as follows
the volume of a region. The volume-based FDR is defined as follows
![$$\begin{aligned} FDR\equiv E\left[ \frac{\left| R_{pos}\setminus R_{tru}\right| }{\left| R_{pos}\right| }\right] \text { where }\frac{\left| R_{pos}\setminus R_{tru}\right| }{\left| R_{pos}\right| }\equiv 0\text { if }\left| R_{pos}\right| =0. \end{aligned}$$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_Equ1.gif)
Genovese, Lazar, and Nichols [9] defined the volumetric measure in the image space, and consequently it can be translated as the number of voxels in voxel-based analysis. Benjamini and Hochberg’s step-up procedure [2] was applied to control the FDR. The step-up procedure finds
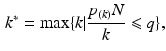 where q is the user specified FDR level,
where q is the user specified FDR level, 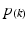 is the k-th smallest voxel p-value, and N is the number of voxels. This step-up procedure is able to handle positive dependence among tests, as Benjamini and Yekutieli discussed in [4]. For more general dependence among tests, please refer to [4].
is the k-th smallest voxel p-value, and N is the number of voxels. This step-up procedure is able to handle positive dependence among tests, as Benjamini and Yekutieli discussed in [4]. For more general dependence among tests, please refer to [4].
denote the detected region, the underlying truth, and the volume of a region. The volume-based FDR is defined as follows(1)
is the k-th smallest voxel p-value, and N is the number of voxels. This step-up procedure is able to handle positive dependence among tests, as Benjamini and Yekutieli discussed in [4]. For more general dependence among tests, please refer to [4].Benjamini and Hochberg (1997) [3] upgraded it to a weighted version whose FDR and control procedure are
![$$\begin{aligned} FDR\equiv E\left[ \frac{\sum _{i\in R_{pos\setminus R_{tru}}}w_{i}}{\sum _{i\in R_{pos}}w_{i}}\right] ,\text { }k^{*}=\max \{k|\frac{p_{(k)}\sum _{i=1}^{N}w_{(i)}}{\sum _{i=1}^{k}w_{(i)}}\leqslant q\}, \end{aligned}$$](/wp-content/uploads/2016/09/A339424_1_En_10_Chapter_Equ2.gif)
where 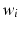 is the weight associated with a voxel.
is the weight associated with a voxel.
(2)
is the weight associated with a voxel.Related posts:
 Stable Overlapping Replicator Dynamics for Multimodal Brain Subnetwork Identification
Stable Overlapping Replicator Dynamics for Multimodal Brain Subnetwork Identification
 PET Reconstruction with Sparse Image Representation and Anatomical Priors
PET Reconstruction with Sparse Image Representation and Anatomical Priors
 Method to Discover Genetically Driven Image Biomarkers
Method to Discover Genetically Driven Image Biomarkers
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


