(or I), a (M + 1) × (N + 1) neighborhood 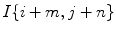 with
with 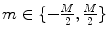 and
and 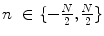 calling sweeping window is being processed. Then, textural features are extracted from this sweeping window and assigned to the central pixel. Finally, according to the extracted features, pixels are classified into predetermined classes by the means of a classifier. It is worth mentioning that since IVUS images are circular cross section of the blood vessel, input images are converted into polar coordinates before applying texture analysis methods so that rectangular sweeping windows used for feature extraction are utilizable (Fig. 26.2).
calling sweeping window is being processed. Then, textural features are extracted from this sweeping window and assigned to the central pixel. Finally, according to the extracted features, pixels are classified into predetermined classes by the means of a classifier. It is worth mentioning that since IVUS images are circular cross section of the blood vessel, input images are converted into polar coordinates before applying texture analysis methods so that rectangular sweeping windows used for feature extraction are utilizable (Fig. 26.2).

Fig. 26.1
Different tissue types in plaque area of IVUS images: (a) dense calcium, (b) necrotic core, and (c) fibro-lipid
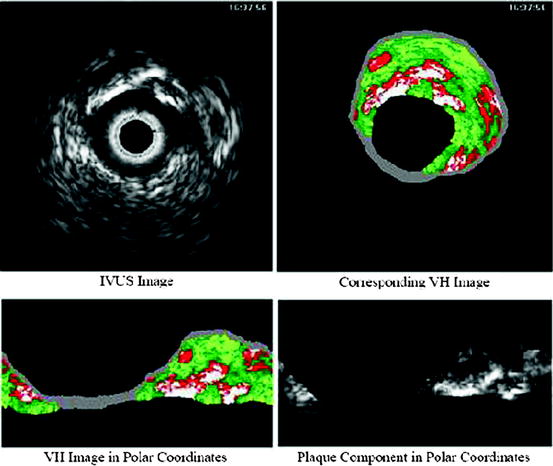
Fig. 26.2
Cartesian–Polar conversion of IVUS images for feature extraction
Figure 26.3 shows the outline of the project and the steps of Tissue Characterization stage. However, each of the proposed algorithms later explained in this chapter may follow some or all of these steps. It is worth defining the materials of these steps before stating the proposed algorithms.
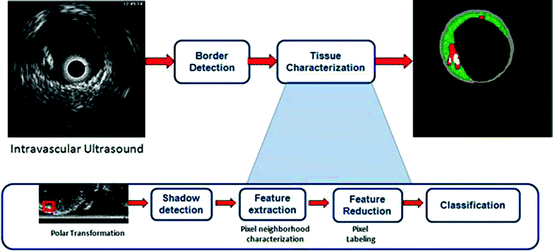
Fig. 26.3
Outline of the project and steps of Tissue Characterization stage
Note: In this chapter, the plaque area is taken directly from the VH examples, in order for us to be able to validate the classification algorithms proposed here.
2 Materials and General Background
2.1 Feature Extraction Methods
Co-occurrence matrix and statistical properties:
A co-occurrence matrix, C, is used to describe the patterns of neighboring pixels in an image at a given distance d, and a given direction 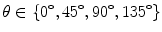 corresponding to horizontal, diagonal, vertical, and anti-diagonal directions (Fig. 26.4). This matrix is somehow a second-order histogram of the image and gives information about the relative positions of the various gray levels within the image [1].
corresponding to horizontal, diagonal, vertical, and anti-diagonal directions (Fig. 26.4). This matrix is somehow a second-order histogram of the image and gives information about the relative positions of the various gray levels within the image [1].
corresponding to horizontal, diagonal, vertical, and anti-diagonal directions (Fig. 26.4). This matrix is somehow a second-order histogram of the image and gives information about the relative positions of the various gray levels within the image [1].Fig. 26.4
The four directions used to form the co-occurrence matrix
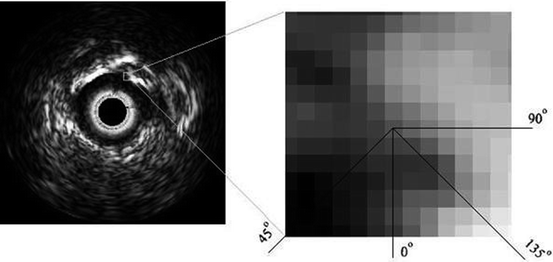
Let us consider the neighborhood centered on the pixel (i, j) from image I. Its co-occurrence matrix is defined in a certain direction as 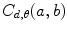 ,where
,where ![$$ a,b\in [1,\ldots,P], $$](/wp-content/uploads/2016/08/A271459_1_En_26_Chapter_IEq00267.gif) where P refers to maximum gray level in image I and d is the gray level distance in the direction
where P refers to maximum gray level in image I and d is the gray level distance in the direction 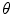 . Figure 26.5 gives a graphical description of this process for
. Figure 26.5 gives a graphical description of this process for 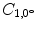 .
.
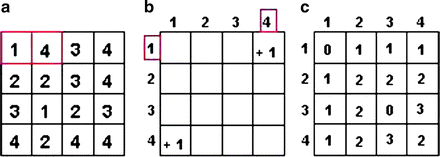
,where where P refers to maximum gray level in image I and d is the gray level distance in the direction . Figure 26.5 gives a graphical description of this process for .Fig. 26.5
Construction of the co-occurrence matrix in horizontal direction: (a) the original image, (b) horizontal neighboring of gray levels 1 and 4 with distance 1 occurred once in the image, and (c) the final result of the horizontal co-occurrence matrix
Various textural features can then be derived from co-occurrence matrix. For defining these textural features it is necessary to calculate the following statistical parameters in the first step:
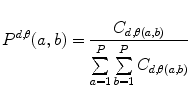
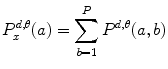
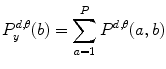
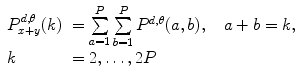
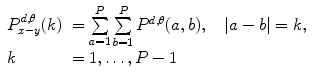
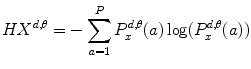
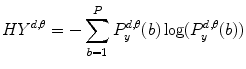
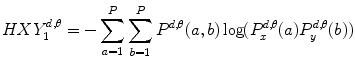
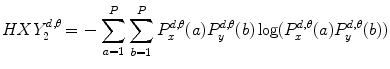
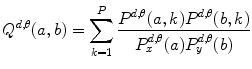
(26.1)
(26.2)
(26.3)
(26.4)
(26.5)
(26.6)
(26.7)
(26.8)
(26.9)
(26.10)
Based on these statistical parameters, the 14 Haralick texture features are defined as follows:
1.
Angular second moment (ASM): this feature is a measure of smoothness of the image. The less smooth the image is, the lower is the ASM.
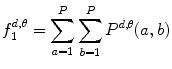
(26.11)
2.
Contrast: This feature is a measure of local gray-level variations.
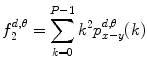
(26.12)
3.
Correlation:
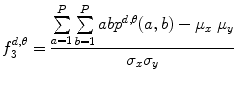
(26.13)
4.
Variance:
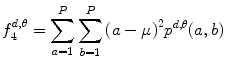
(26.14)
5.
Inverse difference moment:
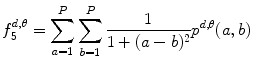
(26.15)
6.
Sum average:
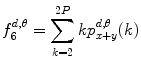
(26.16)
7.
Sum variance:
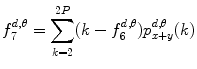
(26.17)
8.
Sum entropy:
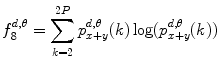
(26.18)
9.
Difference variance:
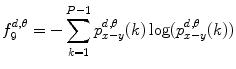
(26.19)
10.
Difference variance:
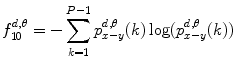
(26.20)
11.
Entropy: This feature is a measure of randomness of the image and takes low values for smooth images.
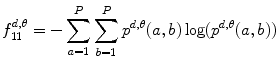
(26.21)
12.
Information measure:
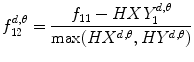
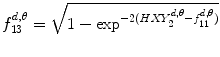
(26.22)
(26.23)
13.
Maximal correlation coefficient:
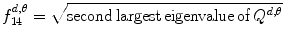
(26.24)
Local binary pattern (LBP):
LBP is a structure-related measure in which a binary number is allocated to the circularly symmetric neighborhoods of the center pixel of the window being processed and the histogram of the resulting binary patterns can be used as a discriminative feature for texture analysis [2, 3]. Actually, in this method N neighbors of the center pixel (i, j) on a circle of radius R with coordinates 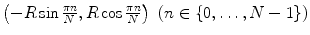 are processed. Typical neighbor sets
are processed. Typical neighbor sets 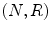 are (8, 1), (16, 2), and (24, 3), as shown in Fig. 26.6.
are (8, 1), (16, 2), and (24, 3), as shown in Fig. 26.6.

are processed. Typical neighbor sets are (8, 1), (16, 2), and (24, 3), as shown in Fig. 26.6.
Fig. 26.7
Illustration of LBP, Left: the basic steps in computing the LBP code for a given pixel position: (a) the operator is centered on the given pixel and equidistant samples are taken on the circle of radius around the center; (b) the obtained samples are turned into 0’s and 1’s by applying a sign function with the center pixel value as threshold; (c) rotation invariance is achieved by bitwise shifting the binary pattern clockwise until the lowest binary number is found. Right: some of the microstructures that LBP are measuring [5]
As these coordinates do not match the coordinates of the processing window, their corresponding gray levels are estimated by interpolation. Let 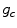 correspond to the gray value of the center pixel and
correspond to the gray value of the center pixel and 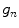 correspond to the gray values of the N neighbor pixels. A binary digit is then allocated to each neighbor based on the following function:
correspond to the gray values of the N neighbor pixels. A binary digit is then allocated to each neighbor based on the following function:
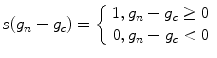
correspond to the gray value of the center pixel and correspond to the gray values of the N neighbor pixels. A binary digit is then allocated to each neighbor based on the following function:(26.25)
Then, by rotating the neighbor set clockwise the least significant resulting binary string is assigned to the processing as its binary pattern  . This way the local binary pattern is rotation invariant. The basic steps for calculating
. This way the local binary pattern is rotation invariant. The basic steps for calculating 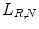 and some microstructures that binary patterns can detect in images are illustrated in Fig. 26.7.
and some microstructures that binary patterns can detect in images are illustrated in Fig. 26.7.
. This way the local binary pattern is rotation invariant. The basic steps for calculating and some microstructures that binary patterns can detect in images are illustrated in Fig. 26.7.Based on the binary pattern 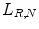 and the gray values of neighbor pixels
and the gray values of neighbor pixels 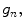 three texture features are defined as follows (Figs. 26.8, 26.9, and 26.10):
three texture features are defined as follows (Figs. 26.8, 26.9, and 26.10):
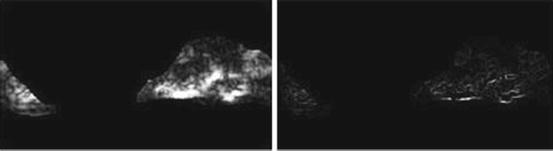
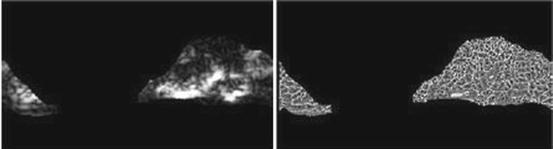
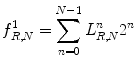
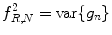
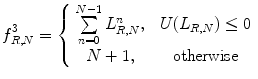
and the gray values of neighbor pixels three texture features are defined as follows (Figs. 26.8, 26.9, and 26.10):Fig. 26.8
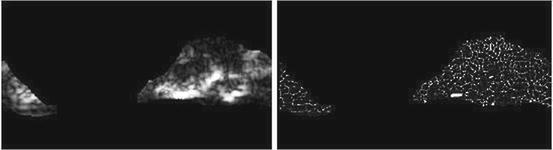
Illustration of 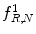 feature for P = 8, R = 1: plaque area in polar coordinates (left) and
feature for P = 8, R = 1: plaque area in polar coordinates (left) and 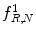 (right)
(right)
feature for P = 8, R = 1: plaque area in polar coordinates (left) and (right)Fig. 26.9
Illustration of 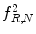 feature for P = 8; R = 1: plaque area in polar coordinates (left) and
feature for P = 8; R = 1: plaque area in polar coordinates (left) and 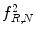 (right)
(right)
feature for P = 8; R = 1: plaque area in polar coordinates (left) and (right)Fig. 26.10
Illustration of 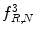 feature for P = 8; R = 1: plaque area in polar coordinates (left) and
feature for P = 8; R = 1: plaque area in polar coordinates (left) and 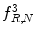 (right)
(right)
feature for P = 8; R = 1: plaque area in polar coordinates (left) and (right)(26.26)
(26.27)
(26.28)
Function U is a transition counter that counts the transition between 0 and 1 and vice versa in the binary pattern.
Run-length matrix:
One of the methods that has been extensively used in segmentation and texture analysis is run-length transform [1]. A gray-level run is a set of consecutive pixels having the same gray-level value. The length of the run is the number of pixels in the run. Run-length features encode textural information related to the number of times each gray-level appears in the image by itself, the number of times it appears in pairs, and so on. Let us consider the neighborhood centered on the pixel (i, j) from image I. Its run-length matrix is defined in a certain direction as 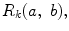 where
where ![$$ a\in \left[ {1,\ldots,P} \right], $$](/wp-content/uploads/2016/08/A271459_1_En_26_Chapter_IEq002625.gif) where P is maximum gray level and b is the run length, i.e., the number of consecutive pixels along a direction having the same gray-level value. In this approach each neighborhood is characterized with two run-length matrices:
where P is maximum gray level and b is the run length, i.e., the number of consecutive pixels along a direction having the same gray-level value. In this approach each neighborhood is characterized with two run-length matrices: 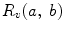 and
and 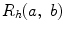 corresponding to vertical and horizontal directions, respectively. Figure 26.11 shows the formation of run-length matrix.
corresponding to vertical and horizontal directions, respectively. Figure 26.11 shows the formation of run-length matrix.
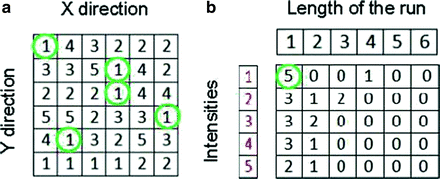
where where P is maximum gray level and b is the run length, i.e., the number of consecutive pixels along a direction having the same gray-level value. In this approach each neighborhood is characterized with two run-length matrices: and corresponding to vertical and horizontal directions, respectively. Figure 26.11 shows the formation of run-length matrix.Fig. 26.11
Run-length matrix (in horizontal direction) formation: (a) original intensity matrix and (b) run-length matrix
Let R be the maximum run-length, N r be the total number of runs, and 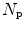 be the number of pixels in the processing window. Run-length features are then defined as follows:
be the number of pixels in the processing window. Run-length features are then defined as follows:
be the number of pixels in the processing window. Run-length features are then defined as follows:1.
Galloway (traditional) run-length features: the five original features of run-length statistics derived by Galloway [6] are as follows:
Short run emphasis (SRE) (Fig. 26.12):
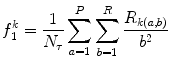
(26.29)
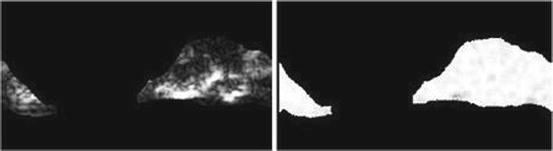
Fig. 26.12
Illustration of feature SRE: plaque area in polar coordinates (left) and SRE (right)
Long run emphasis (LRE) (Fig. 26.13):
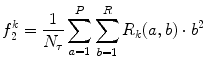
(26.30)
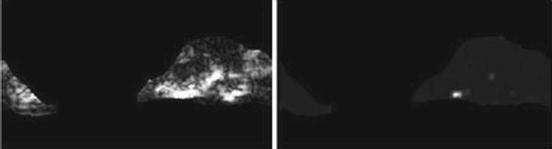
Fig. 26.13
Illustration of feature LRE: plaque area in polar coordinates (left) and LRE (right)
Gray-level nonuniformity (GLN) (Fig. 26.14):
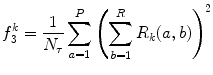
(26.31)
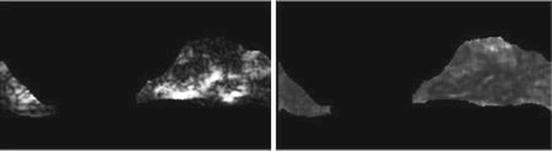
Fig. 26.14
Illustration of feature GLN: plaque area in polar coordinates (left) and GLN (right)
Run-length nonuniformity (RLN) (Fig. 26.15):
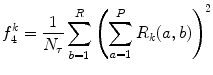
(26.32)
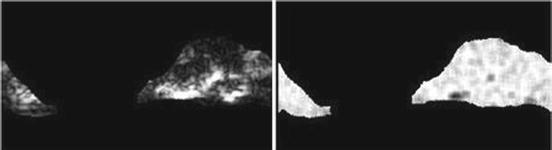
Fig. 26.15
Illustration of feature RLN: plaque area in polar coordinates (left) and RLN (right)
Run percentage (Fig. 26.16):
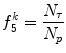
(26.33)
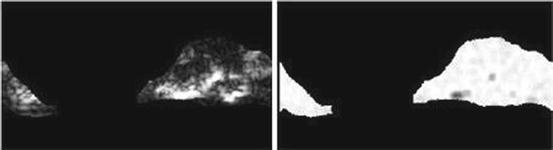
Fig. 26.16
Illustration of feature run percentage: plaque area in polar coordinates (left) and run percentage (right)
2.
Chu run-length features: the following features proposed by Chu et al. extract gray-level information in run-length matrix:
Low gray-level run emphasis (LGRE) (Fig. 26.17):
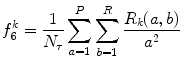
(26.34)
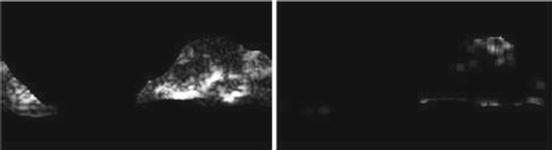
Fig. 26.17
Illustration of feature LGRE: plaque area in polar coordinates (left) and LGRE (right)
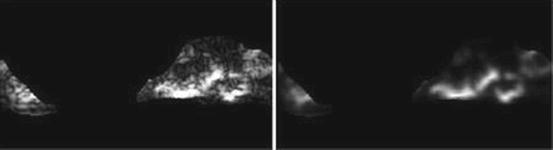
Fig. 26.18
Illustration of feature HGRE: plaque area in polar coordinates (left) and HGRE (right)
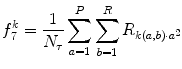
3.
Dasarathy and holder features: these features follow the idea of joint statistical measure of gray level and run length:
Short run low gray-level emphasis (SRLGE) (Fig. 26.19):
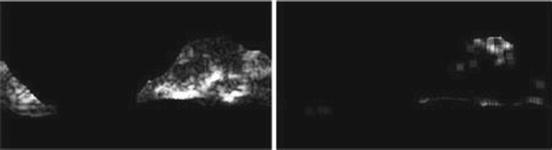
Fig. 26.19
Illustration of feature SRLGE: plaque area in polar coordinates (left) and SRLGE (right)
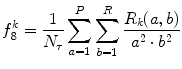
(26.36)
Short run high gray-level emphasis (SRHGE) (Fig. 26.20):
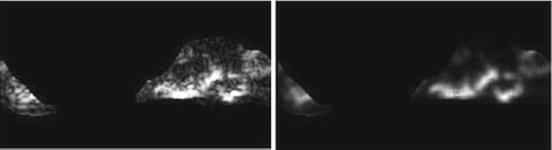
Fig. 26.20
Illustration of feature SRHGE: plaque area in polar coordinates (left) and SRHGE (right)
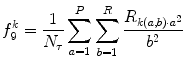
(26.37)
Long run low gray-level emphasis (LRLGE) (Fig. 26.21):
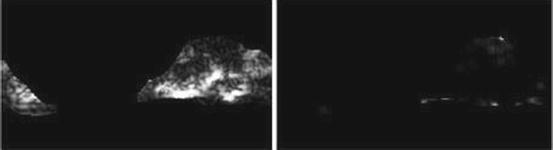
Fig. 26.21
Illustration of feature LRLGE: plaque area in polar coordinates (left) and LRLGE (right)
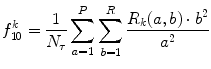
(26.38)
Long run high gray-level emphasis (LRHGE) (Fig. 26.22):
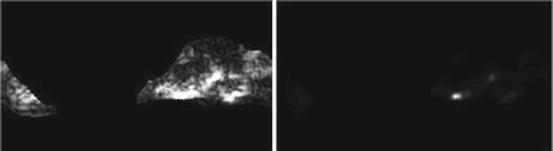
Fig. 26.22
Illustration of feature LRLGE: plaque area in polar coordinates (left) and LRHGE (right)
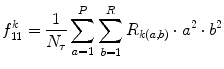
(26.39)
Above-mentioned methods have been previously used by several groups for IVUS plaque characterization. In next sections the proposed methods are introduced and discussed.
2.2 Feature Reduction
Linear discriminant analysis (LDA):
LDA are methods which are used in statistics and machine learning to find the linear combination of features which best separate two or more classes of objects or events. The resulting combination may be used as a linear classifier or, more commonly, for dimensionality reduction before later classification. Suppose that the feature vectors come from C different classes (each class with mean 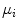 and covariance
and covariance 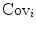 ), then the between class and within class scatter matrices are defined as follows:
), then the between class and within class scatter matrices are defined as follows:
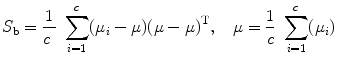
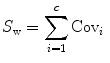
and covariance ), then the between class and within class scatter matrices are defined as follows:(26.40)
(26.41)
It is proved that eigenvectors of 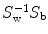 are the directions that best separate these classes from each other [7]. Projecting feature vectors to the L (L < # of features) largest eigenvectors results in a new reduced feature vector that better suited to classification methods. Figure 26.23 shows a Fisher direction for a three class problem.
are the directions that best separate these classes from each other [7]. Projecting feature vectors to the L (L < # of features) largest eigenvectors results in a new reduced feature vector that better suited to classification methods. Figure 26.23 shows a Fisher direction for a three class problem.
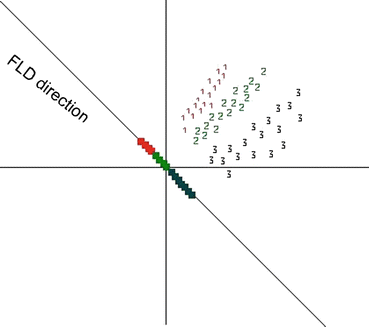
are the directions that best separate these classes from each other [7]. Projecting feature vectors to the L (L < # of features) largest eigenvectors results in a new reduced feature vector that better suited to classification methods. Figure 26.23 shows a Fisher direction for a three class problem.Fig. 26.23
Distribution of three classes and the Fisher direction that best separates these classes from each other
2.3 Classification
2.3.1 SVM Classifier
Support vector machines (SVM) are the classifiers based on the concept of decision planes that define decision boundaries. A decision plane is one that separates between a set of objects having different class memberships. A schematic example is shown in the illustration below. In this example, the objects belong either to class Black or White. The separating line defines a boundary on the right side of which all objects are Black and to the left of which all objects are White. The above is a classic example of a linear classifier, i.e., a classifier that separates a set of objects into their respective groups (Black and White in this case) with a line. Most classification tasks, however, are not that simple, and often more complex structures are needed in order to make an optimal separation, i.e., correctly classify new objects (test cases) on the basis of the examples that are available (train cases). Classification tasks based on drawing separating lines to distinguish between objects of different class memberships are known as hyperplane classifiers. Support vector machines are particularly suited to handle such tasks. Support vector machine (SVM) is primarily a classifier method that performs classification tasks by constructing hyperplanes in a multidimensional space that separates cases of different class labels. To construct an optimal hyperplane, SVM employs an iterative training algorithm which is used to minimize an error function. According to the form of the error function, SVM models can be classified into different distinct groups. The C-SVM type is used in all proposed algorithms. In a two-class case, if the training dataset consists of feature vectors 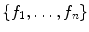 with class labels
with class labels 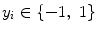 , then the SVM training problem is equivalent to finding W and b such that training involves the minimization of the error function [8] and [9]:
, then the SVM training problem is equivalent to finding W and b such that training involves the minimization of the error function [8] and [9]:
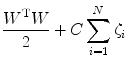
subject to the constraints:
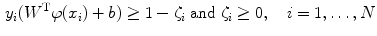
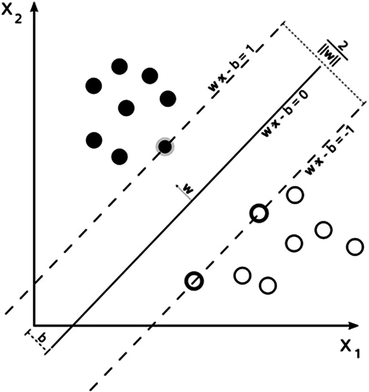
where 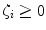 are the so-called slack variables that allow for misclassification of noisy data points, and parameter C > 0 controls the trade-off between the slack variable penalty and the margin [8]. In fact, W and b are chosen in a way that maximize the margin, or distance between the parallel hyperplanes that are as far apart as possible while still separating the data (Fig. 26.24). The function
are the so-called slack variables that allow for misclassification of noisy data points, and parameter C > 0 controls the trade-off between the slack variable penalty and the margin [8]. In fact, W and b are chosen in a way that maximize the margin, or distance between the parallel hyperplanes that are as far apart as possible while still separating the data (Fig. 26.24). The function 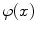 maps the data to a higher dimensional space. This new space is defined by its kernel function:
maps the data to a higher dimensional space. This new space is defined by its kernel function:
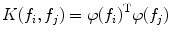
with class labels , then the SVM training problem is equivalent to finding W and b such that training involves the minimization of the error function [8] and [9]:(26.42)
(26.43)
are the so-called slack variables that allow for misclassification of noisy data points, and parameter C > 0 controls the trade-off between the slack variable penalty and the margin [8]. In fact, W and b are chosen in a way that maximize the margin, or distance between the parallel hyperplanes that are as far apart as possible while still separating the data (Fig. 26.24). The function maps the data to a higher dimensional space. This new space is defined by its kernel function:(26.44)
The above problem can be formulated as a quadratic optimization process. The details of the solution and its implementation can be found in [10]. The Gaussian Radial Basis Function (RBF) kernel was used:
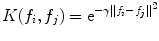
(26.45)
This was firstly due to the fact that RBF kernel has only one parameter 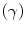 to adjust. Also, SVM classifiers based on RBF kernel were found more accurate than linear, sigmoid, and polynomial kernels in case of our problem. The publicly available C++ implementation of the SVM algorithms known as LIBSVM [10] was used. The entire dataset was normalized prior to training by setting the maximum value of each feature to 1 and the minimum to 0. For each set of parameters, fivefold cross validation was performed: the SVM was trained using 80% of the data samples, classified the remaining 20%, and repeated the procedure for all five portions of the data (Fig. 26.25).
to adjust. Also, SVM classifiers based on RBF kernel were found more accurate than linear, sigmoid, and polynomial kernels in case of our problem. The publicly available C++ implementation of the SVM algorithms known as LIBSVM [10] was used. The entire dataset was normalized prior to training by setting the maximum value of each feature to 1 and the minimum to 0. For each set of parameters, fivefold cross validation was performed: the SVM was trained using 80% of the data samples, classified the remaining 20%, and repeated the procedure for all five portions of the data (Fig. 26.25).
to adjust. Also, SVM classifiers based on RBF kernel were found more accurate than linear, sigmoid, and polynomial kernels in case of our problem. The publicly available C++ implementation of the SVM algorithms known as LIBSVM [10] was used. The entire dataset was normalized prior to training by setting the maximum value of each feature to 1 and the minimum to 0. For each set of parameters, fivefold cross validation was performed: the SVM was trained using 80% of the data samples, classified the remaining 20%, and repeated the procedure for all five portions of the data (Fig. 26.25).Fig. 26.24
Maximum-margin hyperplane and margins for a SVM trained with samples from two classes. Samples on the margin are called the support distribution
2.4 Post-processing
Studying intensity variety of each plaque component in VH images of the dataset through histogram analysis reveals that useful information can be extracted via this simple analysis. Figure 26.26 illustrates the histogram of pixels for three different plaque components. As this gray-scale-derived information might be ignored among many textural features in the classification steps, another step is added to the algorithm after the classification by SVM. In this step the given label of a pixel by SVM is confirmed or altered based on some prior information derived from the histogram of the IVUS image. Some useful information is pointed out below that can be inferred from the histograms displayed in Fig. 26.26:
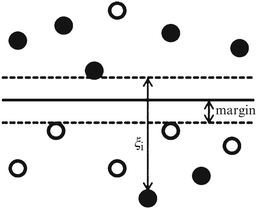
Fig. 26.25
Example of misclassification that shows slack variables
Fig. 26.26
The histogram of pixels belonging to FF, DC, and NC classes for 400 out of 500 IVUS images
The majority of samples belong to FF class; however, there are few FF pixels whose their intensities exceed the gray level 150 (ThFF = 150).
Most of the pixels with intensities above the gray level 200 [ThDC (low) = 200] belong to the DC class, whereby few pixels with value under 50 [ThDC (high) = 50] belong to this class.
Pixels belonging to the NC are concentrated more between 30 and 200 gray levels [ThNC (low) = 30] and [ThNC (high) = 200].
So, based on these additional thresholds, the system will decide on whether to change the decision of SVM classifier or not.
2.5 Dataset
The data were acquired from 10 patients, which included about 2,263 gray-scale IVUS images and their corresponding VH images. These IVUS images of size 400 × 400 pixels were acquired using an electronic probe (In-Vision Gold, Volcano Therapeutics, Inc.) with a synthetic aperture 2.9 F and a frequency of 20 MHz. A motorized pullback was performed along the entire vessel with a speed of 1.0 mm/s using a dedicated pullback device. A total number of 500 frames from 12 vessels [6 left anterior descending (LAD), 3 right coronary artery (RCA), 3 left circumflex (LCX)] of 10 patients were available for VH analysis and comparison with IBH. In the VH analysis the total average amount of fibrous/fibro-fatty, dense calcium, and necrotic core was (1,505,907 pixels) 37,647 mm2, (388,073 pixels) 9,701 mm2, and (516,711 pixels) 12,917 mm2, respectively. The relative average amounts per cross section were 63%, 16%, and 21%.
2.6 Statistical Analysis
The measures of sensitivity, specificity, and predictive accuracy for the three plaque components were calculated and reported as statistical analysis in this thesis. The standard formulae for these measures were the same commonly accepted in the medical literature [11].
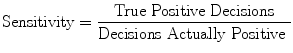
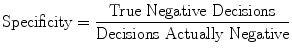
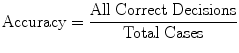
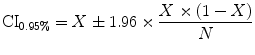
where 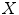 is either the sensitivity or specificity and
is either the sensitivity or specificity and 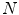 is the number of decisions used in denominator for calculating the sensitivity or specificity. In addition to the above-mentioned measures, Cohen’s Kappa index is calculated to quantify the degree of agreement between the Algorithm IV and VH classification for in vivo validation, and Algorithm IV and manual painted images for ex vivo validations. A kappa value of 0.41–0.60 indicates moderate (fair) agreement, 0.61–0.80 indicates good agreement, and 0.81–1.0 indicates excellent agreement. This metric was originally introduced by Cohen to determine the level of agreement between two observers [11]. The kappa is calculated as
is the number of decisions used in denominator for calculating the sensitivity or specificity. In addition to the above-mentioned measures, Cohen’s Kappa index is calculated to quantify the degree of agreement between the Algorithm IV and VH classification for in vivo validation, and Algorithm IV and manual painted images for ex vivo validations. A kappa value of 0.41–0.60 indicates moderate (fair) agreement, 0.61–0.80 indicates good agreement, and 0.81–1.0 indicates excellent agreement. This metric was originally introduced by Cohen to determine the level of agreement between two observers [11]. The kappa is calculated as
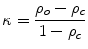
where 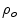 is the observed proportion of agreement and
is the observed proportion of agreement and 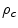 is the expected proportion of agreement resulting from chance.
is the expected proportion of agreement resulting from chance.
(26.46)
(26.47)
(26.48)
(26.49)
is either the sensitivity or specificity and is the number of decisions used in denominator for calculating the sensitivity or specificity. In addition to the above-mentioned measures, Cohen’s Kappa index is calculated to quantify the degree of agreement between the Algorithm IV and VH classification for in vivo validation, and Algorithm IV and manual painted images for ex vivo validations. A kappa value of 0.41–0.60 indicates moderate (fair) agreement, 0.61–0.80 indicates good agreement, and 0.81–1.0 indicates excellent agreement. This metric was originally introduced by Cohen to determine the level of agreement between two observers [11]. The kappa is calculated as(26.50)
is the observed proportion of agreement and is the expected proportion of agreement resulting from chance.3 Algorithm I
3.1 Textural Feature Extraction
As it was mentioned in the previous section, various textural features can be derived from run-length matrix such as the short run emphasis, the long run emphasis, the gray-level nonuniformity, the run-length nonuniformity, and the run percentage. These features have been previously used on IVUS images; however, the results were not fulfilling [12]. Hence, two new features are proposed characterizing each gray-level a (i.e., every row) of the run-length matrix. The first feature 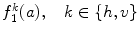 where h and v represent horizontal and vertical respectively is defined as the maximum number of occurrences multiplied by the length of the run with maximum occurrence
where h and v represent horizontal and vertical respectively is defined as the maximum number of occurrences multiplied by the length of the run with maximum occurrence 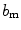 :
:
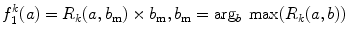
where h and v represent horizontal and vertical respectively is defined as the maximum number of occurrences multiplied by the length of the run with maximum occurrence :(26.51)
And the second feature 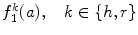 is defined as the sum of every occurrences multiplied by its corresponding run length:
is defined as the sum of every occurrences multiplied by its corresponding run length:
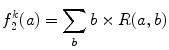
is defined as the sum of every occurrences multiplied by its corresponding run length:(26.52)
This way, each pixel (i, j) is mapped to a feature matrix, j:
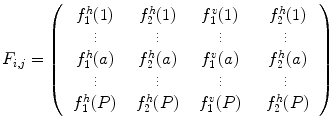
(26.53)
Let us consider now each column  of matrix
of matrix 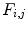 as a signal that is a function of the gray level
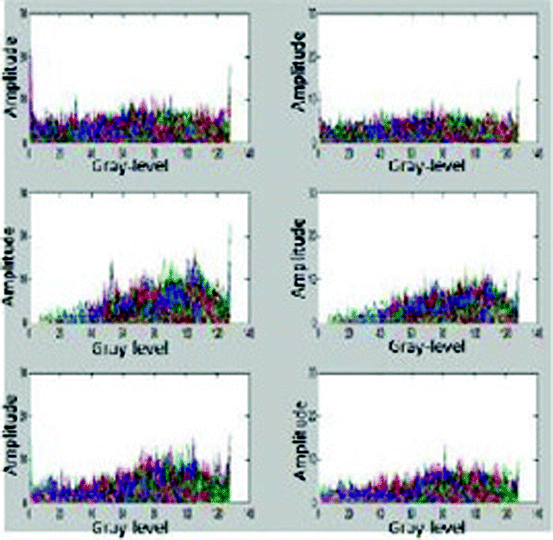
as a signal that is a function of the gray level 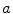 . As shown in Fig. 26.27, these signals reveal different frequency contents. This motivates us to extract discriminative features from spatial-frequency representation of the signals. Therefore, each signal is decomposed into a detail
. As shown in Fig. 26.27, these signals reveal different frequency contents. This motivates us to extract discriminative features from spatial-frequency representation of the signals. Therefore, each signal is decomposed into a detail 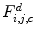 and an approximation
and an approximation 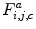 by means of
by means of 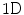 discrete wavelet transform (DWT):
discrete wavelet transform (DWT):
![$$ F_{i,j,c}^a[u]=({F_{i,j }}*l)[u] $$](/wp-content/uploads/2016/08/A271459_1_En_26_Chapter_Equ002654.gif)
![$$ F_{i,j,c}^d[u]=({F_{i,j }}*h)[u] $$](/wp-content/uploads/2016/08/A271459_1_En_26_Chapter_Equ002655.gif)
of matrix as a signal that is a function of the gray level . As shown in Fig. 26.27, these signals reveal different frequency contents. This motivates us to extract discriminative features from spatial-frequency representation of the signals. Therefore, each signal is decomposed into a detail and an approximation by means of discrete wavelet transform (DWT):Fig. 26.27
Distribution of 5,000 bundle feature vectors for each plaque type. Top to down: DC, fibro lipid, and NC. Left to right: 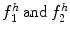
(26.54)
(26.55)
Then, each DWT component ![$$ ((F_{i,j,c}^a[u])\;\mathrm{and}\;(F_{i,j,c}^d[u])) $$](/wp-content/uploads/2016/08/A271459_1_En_26_Chapter_IEq002651.gif) is characterized by a set of statistical features, namely, its weighted mean, weighted variance, maximum of signal, and its index:
is characterized by a set of statistical features, namely, its weighted mean, weighted variance, maximum of signal, and its index:
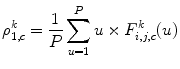
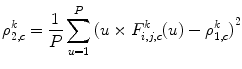
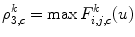
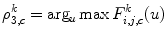
is characterized by a set of statistical features, namely, its weighted mean, weighted variance, maximum of signal, and its index:(26.56)
(26.57)
(26.58)
(26.59)
Furthermore, spectral behavior of these components is also characterized by means of autoregressive (AR) model of order 5:
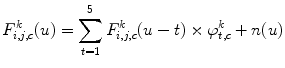
where 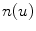 is the white noise and
is the white noise and 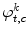 are the coefficients of the AR model. These coefficients are also used as features.
are the coefficients of the AR model. These coefficients are also used as features.
(26.60)
is the white noise and are the coefficients of the AR model. These coefficients are also used as features.Finally, the feature vector of each pixel 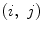 is defined as follows:
is defined as follows:
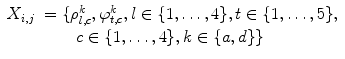
is defined as follows:(26.61)
This vector is the input of the SVM classifier. This classifier was explained in the classification subsection previously.
The block diagram of the proposed algorithm is shown in Fig. 26.28.
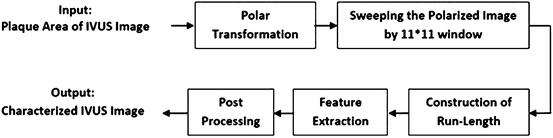
Fig. 26.28
Block diagram of the newly proposed modified run-length method
3.2 Result and Discussion of Algorithm I
The three feature extraction mentioned methods were then applied on the set of 200 frames. The characterized IVUS images were validated by their corresponding VH images and the accuracy, sensitivity, and specificity parameters were calculated for each technique. The results for this approach were compared to methods using LBP or co-occurrence-based features. The size of the neighborhood was empirically chosen to be 11 × 11 for all methods. This was done to get the optimum results for every method separately. For LBP method, five circles were then constructed in each neighborhood. Then, three features were extracted from each circle, and the number of features for every pixel in LBP method thus sums up to 15. Extracting features from five circles with different radii can be thought of as a multi-resolution textural analysis. Total number of features in the co-occurrence method was 14 which include, e.g., homogeneity, contrast, inverse difference moment, and so on. Results using different methods are presented below in Table 26.1. According to the results, Algorithm I is more capable of classifying DC and NC plaques in comparison to LBP or co-occurrence methods.
Table 26.1
The results of Algorithm I versus other techniques
DC | FF | NC | |||||
|---|---|---|---|---|---|---|---|
Method | Sensitivity (%) | Specificity (%) | Sensitivity (%) | Specificity (%) | Sensitivity (%) | Specificity (%) | Overall accuracy (%) |
LBP | 45 | 96 | 97 | 42 | 30 | 95 | 71 |
Co-occurrence | 67 | 95 | 84 | 80 | 53 | 83 | 75 |
Proposed method | 70 | 95 | 84 | 75 | 55 | 82 | 77 |
Although this approach reveals a higher overall accuracy, the co-occurrence and LBP methods perform better in characterizing the fibro-lipid regions. Figure 26.29 illustrates the images characterized by all methods with their corresponding IVUS and VH images.
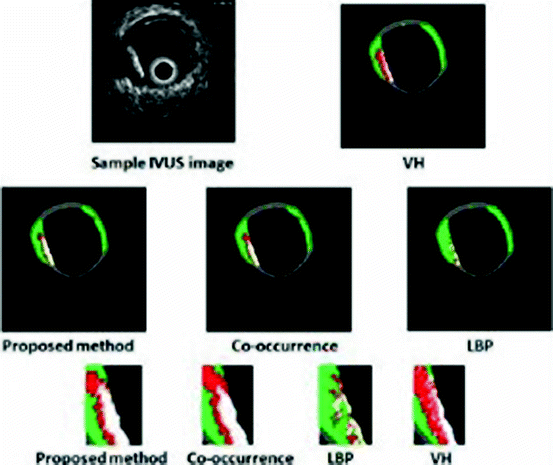
Fig. 26.29
The result of the feature extraction method in comparison with the co-occurrence and LBP methods from left to right (white is DC, green is fibro-lipid, and red is NC) (Color figure online)
In this study, the sensitivity of all methods for the detection of NC was low (55%). This fact was caused by similarities between NC and DC in gray-level IVUS images [13]. Furthermore, previous studies have shown that plaque areas adjacent to DC are frequently coded as NC tissue in VH images [14]. For a typical frame the proposed method took approximately 12 s to characterize the pixels, whereas the LBP took 2.6 min and the co-occurrence took nearly 60 min. Thus, in terms of time efficiency, the proposed method further outdoes the other two. A MATLAB implementation on an Intel Core 2 CPU2.00 GHz computer with 2.0 GB RAM was used in this work.
4 Algorithm II
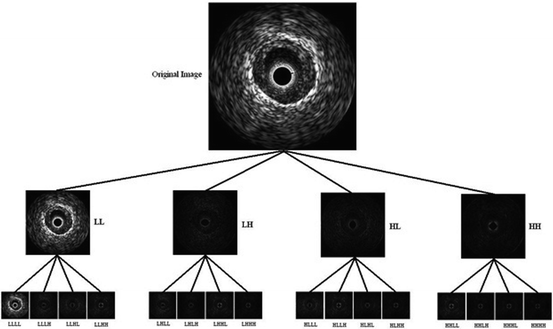
For proposing this algorithm, this fact was taken into account that since each tissue shows different echogenic characteristics, the different plaque components can be characterized by their local frequency components. The best tool for this purpose is wavelet transform (WT). WT provides the best approximation of a space-frequency representation of an image, i.e., it permits to know which spectral components exist at which position in the input image. The main drawback of the WT is that it is translation non-invariant due to the decimation applied to the image after each decomposition level. Recently, another type of wavelet transforms known as redundant wavelet transforms (RWT) has been introduced [15]. Contrary to the classical WT, there is no decimation step after filtering the input image. This provides the decomposition to be translation invariant, and since it preserves the size of images in each level of decomposition, the local spectral components can be retrieved without any interpolation step. To generalize such transform, the wavelet packet transform (WPT) [16] has been introduced to decompose the whole-frequency spectrum into multiple sub-bands of varying sizes. It has been shown to provide a more redundant representation for the analysis of complex textural information. By combining the RWT and WPT, image can be decomposed into multiple sub-band images (Fig. 26.30). This decomposition provides translation invariance in addition to the rotation invariance gained by the initial polar transform.
 Relationship Between Plaque Echogenicity and Atherosclerosis Biomarkers
Relationship Between Plaque Echogenicity and Atherosclerosis Biomarkers
 Quantitative Magnetic Resonance Analysis in the Assessment of Cardiac Diseases
Quantitative Magnetic Resonance Analysis in the Assessment of Cardiac Diseases
 Quantitative Computed Tomography Analysis in the Assessment of Coronary Artery Disease
Quantitative Computed Tomography Analysis in the Assessment of Coronary Artery Disease
 Visualization of Atherosclerotic Coronary Plaque by Using Optical Coherence Tomography
Visualization of Atherosclerotic Coronary Plaque by Using Optical Coherence Tomography
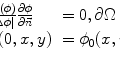 Hypothesis Validation of Far Wall Brightness in Carotid Artery Ultrasound for Feature-Based IMT Measurement Using a Combination of Level Set Segmentation and Registration
Hypothesis Validation of Far Wall Brightness in Carotid Artery Ultrasound for Feature-Based IMT Measurement Using a Combination of Level Set Segmentation and Registration
 Segmentation of Carotid Ultrasound Images
Segmentation of Carotid Ultrasound Images




Related posts:
Relationship Between Plaque Echogenicity and Atherosclerosis Biomarkers
Quantitative Magnetic Resonance Analysis in the Assessment of Cardiac Diseases
Quantitative Computed Tomography Analysis in the Assessment of Coronary Artery Disease
Visualization of Atherosclerotic Coronary Plaque by Using Optical Coherence Tomography
Hypothesis Validation of Far Wall Brightness in Carotid Artery Ultrasound for Feature-Based IMT Measurement Using a Combination of Level Set Segmentation and Registration
Segmentation of Carotid Ultrasound Images
Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
