Fig. 1.
Definition of body sections. Human body is divided into 12 continuous parts. Each parts may cover different ranges due to the variability of anatomies (Color figure online).
In slice-based bodypart recognition, since different body sections have diverse appearance characteristics and even same section may have large variability, it is almost impossible to “design” features that work commonly well for different body parts. Thus, deep learning technology, which can learn features and classifiers simultaneously, becomes a promising solution. However, slice-based bodypart recognition has its unique challenge which might not be solved by standard deep learning. As shown in Fig. 1, although image 7 and 8 belong to aorta arch and cardiac sections, respectively, their global appearance characteristics are quite similar. For these two slices, the only clues to differentiate them come from the local mediastinum region (indicated by the yellow boxes). While the standard deep learning framework is able to learn features, it cannot learn the local patches that are most discriminative for bodypart recognition. Hence, the classification power of the learned deep network may be limited. In fact, in face recognition community, Taigman et al. [12] also shows that only after the face (the local region of interest) is properly localized, can deep learning show its power in face recognition. However, while face is a well defined object and can be detected by mature algorithms, the discriminative local regions for bodypart recognition are not easy to define, not to mention that the effort to build these local detectors might be quite large.
In summary, in order to tackle the challenge of the slice-based bodypart recognition, two key questions need to be answered. First, which local regions are discriminative for bodypart recognition? Second, how to learn the local bodypart identifiers on them without time-consuming manual annotations? We answer these questions using a multi-stage deep learning scheme. In the pre-train stage, a convolutional neural network (CNN) is learned in a multi-instance learning fashion to “discover” the most discriminative local patches. Specifically, each slice is divided into multiple local patches. The deep network thus receives a set of labeled slices (bags), each containing multiple local patches (instances). The loss function of the CNN is adapted in a way that as long as one local patch (instance) is correctly labeled, the corresponding slice (bag) is considered as correct. In this way, the pre-trained CNN will be more sensitive to the discriminative local patches than others. Based on the responses of the pre-trained CNNs, discriminative and non-informative local patches are selected to further boost the pre-trained CNN. This is the second stage of our training scheme, namely “boosting stage”. At run-time, a sliding window approach is employed to apply the boosted CNN to the subject image. As the CNN only has peaky responses on discriminative local patches, it essentially identifies bodypart by focusing on the most distinctive local information. Compared to global image context-based approaches, this local approach is expected to be more accurate and robust.
The major contributions of this work include: 1. We propose a multi-stage deep learning strategy to identify anatomy body parts by using discriminative local information; 2. Our method does not require annotations of the discriminative local patches. Instead, it automatically discovers these local patches through multi-instance deep learning. Thus our solution becomes highly scalable. 3. Our method is validated on a large scale of CT slices and shows superior performance than state-of-the-art methods.
2 Related Work
There are several bodypart recognition systems introduced in this decade. Park et al. [10] proposed an algorithm using energy information from Wavelet Transform to determine the body parts within a certain imaging modality. They used look-up tables to classify the imaging modality and body parts. Hong et al. [5] designed a framework to identify different body parts from a full-body input image. The method begins from establishing global reference frame and the head location. After determining the bounding box of the head, other body parts, i.e., neck, thorax cage, abdomen and pelvis, are localized one by one via different algorithms. These approaches use ad-hoc designed features and algorithms to identify major body parts with globally variant appearances. Some other studies use organ or landmark detection techniques [2, 3, 15]. These methods require large efforts to manually annotate organs or landmarks in the training stage.
The slice-based bodypart recognition is essentially an image classification problem, which has been extensively studied in computer vision and machine learning communities. Generally speaking, image classification methods can be categorized into two groups, global information-based and local information-based. Global information-based approaches extract features from the whole image. Conventional approaches rely on carefully hand-crafted features, e.g., GIST, SIFT, HOG and their variants. These features are extracted on dense grids or a few interested points and organized as bag of words to provide statistical summary of the spatial scene layouts without any object segmentation [7]. Such global representations followed by classical classifiers have been widely used in scene recognition or image classification [14]. Recently, deep learning based algorithms [1, 6] have shown their superior in these tasks due to the ability of learning expressive nonlinear features and classifier simultaneously.
Although the global information-based approaches achieved good performances in some image classification problems, it is not sufficient or appropriate to recognize images whose characteristics are exhibited by local objects, e.g., jumbled image recognition [9] and multi-label image classification [13]. Local information-based approaches can achieve better performance here. For example, Szegedy et al. [11] utilized CNN for local object detection and recognition and achieved state-of-the-art performance on Pascal VOC database. However, in the training stage, they require manually annotated object bounding boxes, which is often time consuming. In another pioneer work, Felzenszwalb et al. [4] proposed a part-based deformable model using local information of object parts for object recognition and detection. The object’s part locations are modeled as latent variables during training of a star-structured part-based model. In a more recent work, Wei et al. [13] applied objectness detection techniques followed by a CNN to provide multiple labels for an image. Based on the characteristics of slices from different body sections (see Fig. 1), a local information-based approach should be used in our study. Different from existing works, we aim to design an algorithm that is able to discover the most discriminative local regions without annotations or explicit object detection. Hence, the solution will become highly scalable.
3 Methodology
3.1 Problem Statement
Definitions: Slice-based bodypart recognition is a typical multi-class image classification problem that can be addressed by convolutional neural network (CNN). Denote 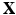 as the input slice/image,
as the input slice/image, 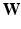 as the CNN coefficients, and K as the number of body sections (classes). Standard CNN outputs a K dimension vector. Its kth component,
as the CNN coefficients, and K as the number of body sections (classes). Standard CNN outputs a K dimension vector. Its kth component, 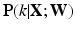 , indicates the probability of
, indicates the probability of 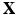 belonging to class k given
belonging to class k given 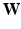 .
.
as the input slice/image, as the CNN coefficients, and K as the number of body sections (classes). Standard CNN outputs a K dimension vector. Its kth component, , indicates the probability of belonging to class k given .Given a training set 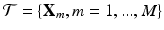 , with corresponding discrete labels
, with corresponding discrete labels 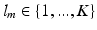 , the training algorithm of CNN aims to minimize the loss function:
, the training algorithm of CNN aims to minimize the loss function:
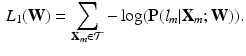
Here, 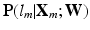 indicates the probability of
indicates the probability of  being correctly classified as
being correctly classified as  .
.
, with corresponding discrete labels , the training algorithm of CNN aims to minimize the loss function:(1)
indicates the probability of being correctly classified as .Fig. 2.
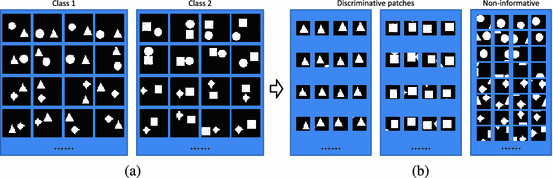
A synthetic toy example. (a) Synthetic images of two classes. (b) The discriminative and non-informative local patches selected by the pre-trained CNN model.
CNN has shown impressive performance in image classification [6, 13] due to its capability of modeling complex nonlinear functions and leveraging the context information of neighboring pixels. In these applications, standard CNN often takes the entire image as input, which is essentially a global learning scheme. In slice-based bodypart recognition, however, the distinctive information often comes from local patches (as shown in Fig. 1) and these local patches are distributed at different locations of the slices. The intrinsic conflicts between “global” and “local” may limit CNN’s performance in our application. (One may argue that CNN can still learn local features through its convolutional layers. However, this situation only holds while local features always appear at the similar location of the image, which is not the case of bodypart recognition.) A toy example is presented to illustrate this problem. As shown in Fig. 2(a), two classes of binary images are synthesized by randomly positioning and combining 4 types of geometry elements, square, circle, triangle and diamond. While circle and diamond appear in both classes, triangle and square are exclusively owned by Class1 and Class2, respectively (ref Sect. 4.1 for more details). Using standard CNN that takes the whole image as input, the classification accuracy is 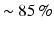 (row “SCNN” of Table 1(a)), which implies it does not discover and learn the discriminative local patches: “triangle” and “square”. Apparently, this problem will become trivial if we have the prior knowledge of the discriminative local patches and build local classifiers on them. However, in bodypart recognition, it is difficult to figure out the most discriminative local patches for different body sections. In addition, even with adhoc knowledge, it will take large efforts to annotate local patches and train local classifiers, which makes the solution non-scalable when body-sections are re-defined or the imaging modalities are changed.
(row “SCNN” of Table 1(a)), which implies it does not discover and learn the discriminative local patches: “triangle” and “square”. Apparently, this problem will become trivial if we have the prior knowledge of the discriminative local patches and build local classifiers on them. However, in bodypart recognition, it is difficult to figure out the most discriminative local patches for different body sections. In addition, even with adhoc knowledge, it will take large efforts to annotate local patches and train local classifiers, which makes the solution non-scalable when body-sections are re-defined or the imaging modalities are changed.
(row “SCNN” of Table 1(a)), which implies it does not discover and learn the discriminative local patches: “triangle” and “square”. Apparently, this problem will become trivial if we have the prior knowledge of the discriminative local patches and build local classifiers on them. However, in bodypart recognition, it is difficult to figure out the most discriminative local patches for different body sections. In addition, even with adhoc knowledge, it will take large efforts to annotate local patches and train local classifiers, which makes the solution non-scalable when body-sections are re-defined or the imaging modalities are changed.In order to leverage the local information, more important, to “discover” the discriminative local patches for body-part identification, we propose a two-stage CNN learning framework that consists of pre-train and boosting stages, which will be detailed next.
3.2 Learning Stage I: Multi-instance CNN Pre-train
To exploit the local information, CNN needs to take some discriminative local patches of the slice as its input. The key problem here is how to discover these local patches through learning. This is the major task of the first stage of our CNN learning framework. A multi-instance learning strategy is employed to achieve this goal.
Given a training set 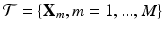 with corresponding labels
with corresponding labels 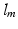 . Each training slice,
. Each training slice, 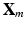 , is divided into a set of local patches defined as
, is divided into a set of local patches defined as 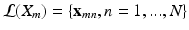 . These local patches become the basic training samples of the CNN and their labels are inherited from the original slices, i.e., all
. These local patches become the basic training samples of the CNN and their labels are inherited from the original slices, i.e., all 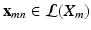 share the same label
share the same label 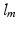 . While the structure of CNN is still the same as the standard one, the loss function is adapted as Eq. 2, where
. While the structure of CNN is still the same as the standard one, the loss function is adapted as Eq. 2, where 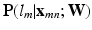 is the probability that the local patch
is the probability that the local patch 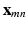 is correctly classified as
is correctly classified as 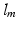 .
.
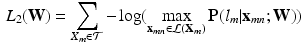
Compared to Eq. (1), the new loss function adopts the multi-instance learning criterion. Here, each original training slice 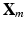 is treated as a bag consisting of multiple instances (local patches),
is treated as a bag consisting of multiple instances (local patches), 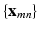 . Within each bag (slice), only the instance with the highest probability to be correctly classified, i.e., the most discriminative local patch, is counted in the loss function. As shown in Fig. 3, assume
. Within each bag (slice), only the instance with the highest probability to be correctly classified, i.e., the most discriminative local patch, is counted in the loss function. As shown in Fig. 3, assume 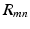 is the output vector of the CNN on local patch
is the output vector of the CNN on local patch 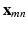 , for each training image
, for each training image 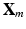 , only the local patch that has the highest response at the
, only the local patch that has the highest response at the 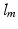 th component of
th component of 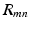 (indicated by the yellow and purple boxes for two training images, respectively), contributes to the backward propagation and drive the network coefficients
(indicated by the yellow and purple boxes for two training images, respectively), contributes to the backward propagation and drive the network coefficients 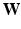 during the training. Hence, the learned CNN is expected to have high responses on discriminative local patches.
during the training. Hence, the learned CNN is expected to have high responses on discriminative local patches.
with corresponding labels . Each training slice, , is divided into a set of local patches defined as . These local patches become the basic training samples of the CNN and their labels are inherited from the original slices, i.e., all share the same label . While the structure of CNN is still the same as the standard one, the loss function is adapted as Eq. 2, where is the probability that the local patch is correctly classified as .(2)
is treated as a bag consisting of multiple instances (local patches), . Within each bag (slice), only the instance with the highest probability to be correctly classified, i.e., the most discriminative local patch, is counted in the loss function. As shown in Fig. 3, assume is the output vector of the CNN on local patch , for each training image , only the local patch that has the highest response at the th component of (indicated by the yellow and purple boxes for two training images, respectively), contributes to the backward propagation and drive the network coefficients during the training. Hence, the learned CNN is expected to have high responses on discriminative local patches.Related posts:
 Stable Overlapping Replicator Dynamics for Multimodal Brain Subnetwork Identification
Stable Overlapping Replicator Dynamics for Multimodal Brain Subnetwork Identification
 PET Reconstruction with Sparse Image Representation and Anatomical Priors
PET Reconstruction with Sparse Image Representation and Anatomical Priors
 Method to Discover Genetically Driven Image Biomarkers
Method to Discover Genetically Driven Image Biomarkers
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


