Natural language processing (NLP) is a subfield of computer science and linguistics that can be applied to extract meaningful information from radiology reports. Symbolic NLP is rule based and well suited to problems that can be explicitly defined by a set of rules. Statistical NLP is better situated to problems that cannot be well defined and requires annotated or labeled examples from which machine learning algorithms can infer the rules. Both symbolic and statistical NLP have found success in a variety of radiology use cases. More recently, deep learning approaches, including transformers, have gained traction and demonstrated good performance.
Key points
- •
Natural language processing describes computer programming that aims to process or generate natural language data, and it is largely divided into symbolic (eg, rule-based) and statistical (eg, machine learning) approaches .
- •
Common tasks useful in radiology report NLP include document classification, sentence classification, named entity recognition, relation extraction, automatic summarization, question answering, and image captioning.
- •
Even the relatively restricted domain of radiology report text is complex and consists of phenomena that must be accounted for in task design, such as negation , uncertainty, and coreference.
- •
Simple string matching and regular expressions are useful techniques to gain initial familiarity with a dataset in advance of performing NLP and can provide quick baseline performance measures.
- •
Word embeddings are vector representations of tokens designed to capture notions of similarity and difference between them. Recurrent neural networks and attention-based networks, such as transformers , are common architectures that tend to perform well on NLP tasks.
Introduction
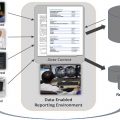
Natural language processing (NLP ) is a subfield of computer science and linguistics. NLP involves the creation and study of computer programs that interact with human language data, including written, typed, or spoken language. Specific NLP applications might extract relevant pieces of information from language data, generate language data automatically, or change the form of language data (eg, translation, text-to-speech software). , NLP drives real-world applications such as automatic translation systems, speech recognition or dictation software, search engines, conversational chatbots, question-answering systems, and digital assistants. NLP is considered a type of artificial intelligence (AI), which focuses on teaching computers to mimic human behavior. Machine learning (ML), which teaches computers to mimic human behavior without being explicitly programmed, and deep learning (DL), a subset of ML that uses deep neural networks, both overlap with NLP: NLP can be performed using neural networks; however, not all NLP uses ML or DL ( Fig. 1 ).

Radiology reports are the final product of the radiology workflow and contain all the relevant information as parsed and interpreted by the radiologist. The format of the radiology report can vary greatly between individual radiologists, subspecialty groups, or larger practices. The lack of a consistent structure or format necessitates the application of NLP to solve problems that require extraction of information concepts or even discrete data from radiology reports. Radiology use cases of NLP have the potential to improve routine patient care, clinician efficiency, and by extension, even job satisfaction. In addition, NLP also enables novel uses of routinely generated radiology data—for research studies, quality improvement initiatives, and medical education. This article discusses the major paradigms of NLP, common NLP tasks, and how these tasks map into the world of radiology. We discuss the differences between ML and non-ML approaches to NLP, as well as common linguistic phenomena that make NLP projects both interesting and uniquely difficult. Last, we discuss use cases of NLP for radiology reports and an end-to-end example of a radiology NLP project.
Natural language processing paradigms
Like other domains of data science and AI, NLP can be divided into symbolic and statistical paradigms. These differ fundamentally in how they approach language data and are typically not combined. Symbolic systems specify an exact algorithmic protocol for the system to follow using precise, human-designed rules. For example, if trying to identify normal-appearing organs in a report one might prescribe the following rule: if there is a word representing the name of an organ, followed by the phrase “appears X,″ where X is one of the words in the set [“normal”, “unremarkable”], then the organ is normal-appearing . Most of the work in a symbolic NLP algorithm goes into writing such rules. Regular expressions, which allow flexible, elaborate text matching, are a valuable tool for implementing complex rules.
Symbolic, or rule-based, systems can be useful for multiple reasons. First, they are relatively interpretable: the user knows exactly why a system produced a particular answer, including why it might make a particular incorrect decision. Symbolic systems are therefore also modifiable—it is relatively straightforward for the algorithm designer to add additional rules or exceptions, enabling simple incorporation of new knowledge or the correction of errors. Debugging or updating a symbolic system just requires carefully reading and editing the rules. In addition, symbolic approaches do not require labeling large amounts of training data to train a model, in the way that ML models do. However, given the complexity and variability of language, symbolic approaches tend to be difficult to scale to complex problems. Owing to their reliance on precisely specified rules, symbolic systems tend to be “brittle,” that is, they break if the data are even slightly different from what was expected. Simple but common linguistic phenomena such as typographical errors, synonyms, indirect references (eg, pronouns), and variation in grammatical forms make specifying all possible instances of a rule extremely difficult. Furthermore, certain linguistic tasks are less amenable to rule-based approaches. Imagine, for example, specifying all the rules required to answer whether a sentence expresses a positive or negative emotional sentiment, or to answer arbitrary questions about a radiology report. By contrast, the statistical paradigm, which includes ML techniques, eschews specific linguistic knowledge and hand-crafted rules in favor of an “end-to-end” approach that relies on a set of expert-annotated examples of the desired task. The system takes these examples, known as the training set , and uses an algorithm to convert that information into a general procedure for labeling unseen examples; this is considered the training process. To evaluate the performance of the system, a separate test set , which does not contain the same examples as the training set, is used to evaluate the resulting model’s performance. Neural networks trained using gradient descent are one example of a statistical NLP approach. For instance, one could train an algorithm to decide whether a radiology report contains findings that require immediate clinical action. Under a supervised learning paradigm, the radiology reports could be annotated at the document level, where “1” indicates a finding requiring action and “0” does not, and then the system uses these data to create an algorithm for annotating the unseen reports accordingly.
There are many benefits to statistical NLP approaches. A statistical solution does not require painstakingly crafting hundreds of linguistic rules. In fact, it does not even require the developer to know why an answer might be correct; all that is required is training data annotated with correct answers. Many of these algorithms, including deep neural networks, are able to handle “complex” or “fuzzy” logic, which does not easily map to a narrow set of symbolic rules, and are often more robust to small changes than symbolic approaches. Some complex problems, including open domain question answering, seem to be tractable only under a statistical paradigm. Disadvantages include the following: although less work is required to specify rules, that work is channeled into creation of high-quality annotations and large training data sets. DL systems, in particular, require large amounts of annotated training examples to effectively learn from. Statistical NLP solutions also tend to be less interpretable—it may be impossible to know exactly why a system got an answer wrong—and difficult to modify in predictable ways. It is difficult to edit a single behavior of an ML algorithm in isolation without retraining it entirely, and even then there are no foolproof ways to ensure that the system changes in the desired direction.
Despite advances in ML in recent decades, there are still scenarios when a symbolic approach is preferable. To decide between a symbolic and statistical algorithm, one should consider the characteristics of the specific task at hand. If it would be easy to specify all the rules required to perform a task in a foolproof or near-foolproof way, a symbolic approach is generally faster and more reliable. Similarly, if it is important to be able to edit or augment your system in predictable ways (beyond just “acquiring more data”), or to know exactly why the system got something wrong, a symbolic approach is likely required. However, for more complex or fuzzy tasks, which may be difficult to specify due to the complexity of natural language, an ML or statistical approach is likely to perform better.
Types of natural language processing tasks
NLP tasks range from the relatively simple (splitting a document into sentences) to the extremely complex (answering arbitrary natural language questions about a particular document). Some are better performed by certain types of algorithms; it is advisable to be guided by the recent general NLP literature to determine which systems best map to which tasks ( Table 1 ). Here, we focus on those tasks that are likely to be of interest to radiologists and data scientists working with radiology reports.
| Term | Definition |
|---|---|
| Document | Single discrete body of text, eg, a radiology report |
| Corpus | A related set of documents, eg, all radiology reports generated between 2010 and 2020 at our hospital |
| Token | Small unit of text with meaning, eg, word, character, punctuation mark, or similar |
| Type | Class of tokens containing the same sequence of characters |
Tokenization is the process of splitting a document up into its corresponding tokens, which can be performed either using handwritten rules or with a trained ML model. In languages that have spaces between words, such as English, simple algorithms using spaces and other punctuation marks to tokenize documents tend to work relatively well. In languages that do not use spaces to separate written words, tokenization may be a more difficult problem. Most freely available NLP software packages contain ready-made tokenization algorithms.
Information extraction (IE) refers to any NLP task that attempts to extract information from a text, instead of generating or translating text. Most IE systems are designed to take messy, textual data and use it to answer a specific question. There are many subtasks of information extraction, including document, sentence, or token classification; named-entity recognition (NER); relation extraction; coreference resolution; and free-text question answering.
Document classification is an umbrella term for any NLP task that classifies an entire text document into one of a set of categories and is usually applied to an entire corpus. , The input is typically a document or corpus, and the output is one or more category labels. In radiology, document classification might identify reports that (1) contain abnormal findings, (2) omit expected sections or required templates, (3) contain typographical errors, or (4) mention new or unexpected findings that require follow-up.
Similarly, sentence classification takes as input a single sentence and produces an answer (binary or categorical) for the sentence. For example, one might wish to determine whether a sentence contains one or more follow-up recommendations, is part of the report impression, or mentions a specific organ. A sentence classification task requires preprocessing of the document into discrete sentences, which is called sentence segmentation or sentence tokenization . If the document is written with punctuation and spaces to clearly delineate sentence boundaries, sentence tokenization becomes straightforward and can be performed with many open source or free NLP packages. However, medical text sometimes contains lists, forms, tables, subheadings, nonprose text elements, and typographical errors, which can complicate the process.
Token classification produces a binary or categorical answer for each token in a document. For instance, one might ask which words in a radiology report represent the name of an organ, the beginning of the “impression” section, abnormal findings in the kidney, or the name of the clinician notified about a critical finding.
Named-Entity Recognition
Perhaps the most common token classification task is NER. This task focuses on identifying which tokens in a document correspond to entities in a particular class. All the aforementioned token classification tasks are also examples of NER. NER tasks can be solved with either symbolic or statistical NLP. Generally, if the “answers” to the task can be defined, for example, identifying all the organs listed in a radiology report, a symbolic approach would be suitable. Relation extraction is the task of identifying conceptual relations between words, phrases, or entities in a document.
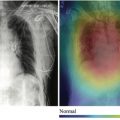
To better understand these tasks, consider the sentence “There is a 2 cm lesion in the superior pole of the left kidney,” that one might find in a radiology report. If the NER task is “which words specify the location of a radiologic finding?” there are multiple possible correct answers, depending on how the NER task is defined ( Fig. 2 ). These tasks require the NLP programmer to have domain-specific knowledge of the problem as well as knowledge of how the NER output is to be used. In addition, the output of the NER task does not specify the finding whose location is being described, unless the relation extraction task connects it back to the word “lesion.” Relation extraction may be formulated to first identify all relevant entities, and then subsequently define their relationships, or to first perform the NER task and then extract the relationships to the entities.

Another important NLP operation is coreference resolution , by which an entity is mentioned more than once, sometimes with different words. For example, in “There is a new lesion in the left kidney. It measures…,” the words “lesion” and “it” refer to the same entity. Coreferent entity mentions may be spread across multiple sentences, paragraphs, or even multiple documents. In addition, the entity may be referenced in whole, in part, or in combination with other entities. For these reasons, coreference resolution, although innate to human language, remains a relatively difficult NLP task.
Text Generation
Some NLP applications are dedicated to producing natural language data, rather than extracting information from existing natural language data. These tasks are typically highly complex even with ML approaches. Perhaps the most obvious use case for text generation in radiology is automated report generation based on image data. Alternatively, text summarization might be useful in either extracting snippets of text verbatim from a document or summarizing the document by producing new text. Text summarization could be applied to autogenerate radiology report impressions or create versions of reports for different audiences, including patients and caregivers, primary care physicians, or specialists.
Language Modeling
Language modeling predicts natural language data given surrounding context. For instance, a language model might assign a high probability that the word “cat” fills the blank in the sentence “the __ in the hat.” Recent neural network-based language models such as Bidirectional Encoder Representations from Transformers (BERT) and the Generative Pre-trained Transformer series are trained on large corpora of existing natural language data to perform language modeling. Language models can also be repurposed to produce text, by having them repeatedly output the most likely next token given all the tokens that have come before. Entire documents can be built up from scratch by repeatedly applying this rule. Although the radiologic use cases for “spontaneous text generation” may not be readily apparent, well-trained language models are capable of performing certain tasks, such as question answering or automatic summarization, without explicitly being trained on them.
Unique considerations for radiology report natural language processing
In building or evaluating NLP for radiology reports, it is worthwhile to consider the unique aspects of radiology report text that may degrade the performance of NLP developed and tested in other domains.
Structured Reporting
Structured data generally have predictable characteristics, including their form (eg, numeric, textual) or domain of acceptable values (positive real numbers). As such, they are generally easier for machines to consume, transform, and generate. Laboratory data and vital signs are highly structured, whereas natural language data are considered to be unstructured. However, some natural language data are more structured than others, simply by belonging to the same domain.
Radiology reports have inherent structure by virtue of being radiology reports; they will use a narrow set of words from the language, compared with a book or newspaper. Reports of abdominal imaging studies will tend to mention all the major abdominal organs. However, even within the domain of radiology reports, there is a wide spectrum of structure, depending on the imaging modality, indication, body region, and individual and institutional documentation preferences and culture. , Nevertheless, these forms of structure can all be helpful when designing an NLP task, algorithm, or model.
Negation is a common linguistic phenomenon that is extremely prevalent in radiology reports; it can take a simple form, for example, “No metastatic disease is seen in the chest,” or make more oblique references to the absence of an entity or abnormality, for example, “The lungs are clear” or “There has been a prior hysterectomy.” As negation is a relatively stereotyped linguistic phenomenon, and particularly if a radiology practice uses many templates, it lends itself to symbolic NLP approaches. Algorithms such as NegEx have been designed for medical text, and other freely available software packages designed for general NLP applications contain explicit negation algorithms. Statistical NLP requires negation be considered during task definition and data annotation.
Like negation, uncertainty is a common phenomenon in radiology reports. Rarely does a radiology report contain a statement such as “this is X.” More commonly, statements such as “an X cannot be excluded,” “without evidence of Y,″ “finding suggestive of Z,″ or complex conditional statements such as “consider A if B″ or “in light of C, D is favored” are found. These phenomena may make it difficult to define a task in terms of binary yes/no outcomes. Both symbolic and statistical approaches will need to consider these questions in their task design, data annotation, and performance assessment. Symbolic rule-based approaches will also need to include additional rules to handle the wide variety of ways to convey uncertainty in radiology reports.
Use cases of natural language processing in radiology
As has been alluded to earlier, there are many applications for NLP in radiology. The vast majority deal with corpora of radiology reports, and more recently, use DL rather than symbolic NLP. Detection of follow-up recommendations, identification of critical findings, and characterization of disease progression are all frequent use cases.
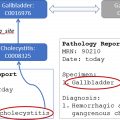
Although earlier initiatives in radiology NLP focused almost exclusively on symbolic approaches, the more common paradigm is some combination of symbolic and statistical NLP, with the latter typically using conventional ML. There are many such examples in the literature: detecting critical findings and follow-up recommendations, quantifying oncologic response, describing the degree of interval change in radiologic findings over time, and identifying diseases such as pneumonia, urinary tract calculi, thromboembolism, and peripheral arterial disease, among others. Extraction of quantitative data from narrative reports, such as measurements, BI-RADS categories, and data that can predict downstream resource use, are other practical applications. Report summarization, including automated generation of report impressions, has also been explored with conventional ML. Radiology-pathology correlation, which has implications in quality improvement, peer learning, and resident education, leverages NLP of both radiology and pathology reports.
DL radiology NLP approaches have become popular in recent years. The use cases are similar to those for symbolic and non-DL statistical NLP and include quantifying oncologic response, identifying pulmonary emboli, , flagging critical findings, , and detecting follow-up recommendations. Broader information extraction from radiology reports has also been demonstrated.
Framework for performing radiology natural language processing
This section is intended to provide a general framework for performing radiology NLP ( Fig. 3 ). Rather than focusing on specific NLP techniques or models, which may become obsolete, this discussion will present a high-level overview with a common sample use case in mind: detecting pulmonary nodules reported on computed tomography (CT).