Organ segmentation, chest radiograph classification, and lung and liver nodule detections are some of the popular artificial intelligence (AI) tasks in chest and abdominal radiology due to the wide availability of public datasets. AI algorithms have achieved performance comparable to humans in less time for several organ segmentation tasks, and some lesion detection and classification tasks. This article introduces the current published articles of AI applied to chest and abdominal radiology, including organ segmentation, lesion detection, classification, and predicting prognosis.
Key points
- •
Organ segmentation, chest radiograph classification, and lung and liver nodule detections are some of the popular artificial intelligence (AI) tasks in the chest and abdominal radiology due to the wide availability of public datasets.
- •
AI algorithms have achieved performance comparable to humans in less time for several organ segmentation tasks, and some lesion detection, and classification tasks.
- •
The complexity of organs and diseases in the chest and abdomen and the imbalance in the availability of public datasets are some of the challenges.
Introduction
How wonderful would it be if an automated assistant would go through our daily chest radiographs and sort out the ones that need our immediate attention; or maybe pick out the diagnostic errors in our computed tomography (CT) reports that could be as high as 5% before we hit that confirm button. Compared with other body parts, chest and abdominal images have a larger field of view, multiple freely moving organs, and greater variability in shape and size. This is one of the reasons why the chest and abdominal images have been latecomers to the field of artificial intelligence (AI). However, with the growing number of public datasets and increases in computational power, the number of published articles has vastly accelerated in the past few years, especially with the outbreak of the Coronavirus Disease 2019 (COVID-19).
For the clinical application of AI, the sophisticated task of interpreting a radiologic image is broken down into separate simplified tasks: measuring an organ or lesion (segmentation), detecting the region of abnormality from the whole image (detection), providing a diagnosis for the detected lesion (classification), and predicting the pathology or prognosis from an image. This review briefly introduces the current AI-derived published articles on the chest and abdominal radiology, accordingly.
Depending on the nature of the task, some algorithms perform better than others. Radiomics, a technique for extracting a large number of quantitative features, is used to link meaningful features to diagnose diseases or predict prognosis. Most segmentation tasks work best with deep learning (DL) algorithms such as convoluted neural networks, especially U-Net and its variants. With DL, the algorithm does not need predefined features, and unsupervised feature learning is possible. However, to do so, it requires a large amount of data and the performance is unstable with insufficient datasets. Radiomics has the advantage of being able to incorporate human knowledge into the algorithm and also has explainability because we know exactly what predefined features have brought the algorithm to its conclusion. However, the feature extraction in radiomics may be affected by factors such as image resolution, low signal-to-noise ratio, and other artifacts. Algorithms for detection are many and include DenseNet, AlexNet, ResNet, and MaskRCNN. Classification algorithms include AlexNet, ResNet, VGG16, GoogLeNet (Inception-v3), and Unet-like architectures. Generative adversarial networks (GAN) have also been used to create saliency maps.
Chest imaging applications
Organ Segmentation
An image segmentation task is a process of partitioning an image into multiple segments, and in radiologic images, it is used to outline the borders of an organ or lesion of interest. Although segmentation is not a task a radiologist would do daily, image segmentation provides us with the volume, shape, and densities of an organ or lesion of interest. This can then be used to quantify the severity or diagnose diseases such as cardiomegaly, chronic obstructive pulmonary disease (COPD), acute respiratory distress syndrome (ARDS), and aortic aneurysm. Image segmentation is also an important building block in improving other AI-derived tasks such as lesion detection and classification.
Organ segmentation was one of the first areas to be explored by AI, and now DL-derived segmentation algorithms have outperformed traditional segmentation algorithms that had rules for segmentation hard-coded into the software. Currently, fully automated segmentation is possible in areas such as the lung fields and heart shadow of chest radiographs and lung lobes and airways in CT scans exceeding Dice similarity coefficients (DSCs) of 0.93 to 0.98. These automated organ segmentation techniques may assist us in situations such as calculating cardiothoracic ratio (correlation coefficient with reference 0.96), detecting malpositioned feeding tubes (area under the curve [AUC] 0.82–0.87) and endotracheal tubes (AUC 0.81) and generating clavicle and rib-free chest radiograph images ( Fig. 1 ) to improve lung mass detection rate (increase receiver operating characteristic curve 10%). Multiorgan segmentation on chest CT scans show equally good results, suggesting potential use on thoracic radiotherapy planning. However, it should be noted that many of the ground truth lung field segmentation in the chest radiograph datasets , do not include the retrocardiac and posterior base of the lung lobes. Also, the segmentation performances are still lower in organs with high variances in shapes, such as the esophagus (DSC 0.75) and right middle lobe, or diseased lung (Intersection over Union of the right middle lobe was 0.89 in the COVID-19 dataset).
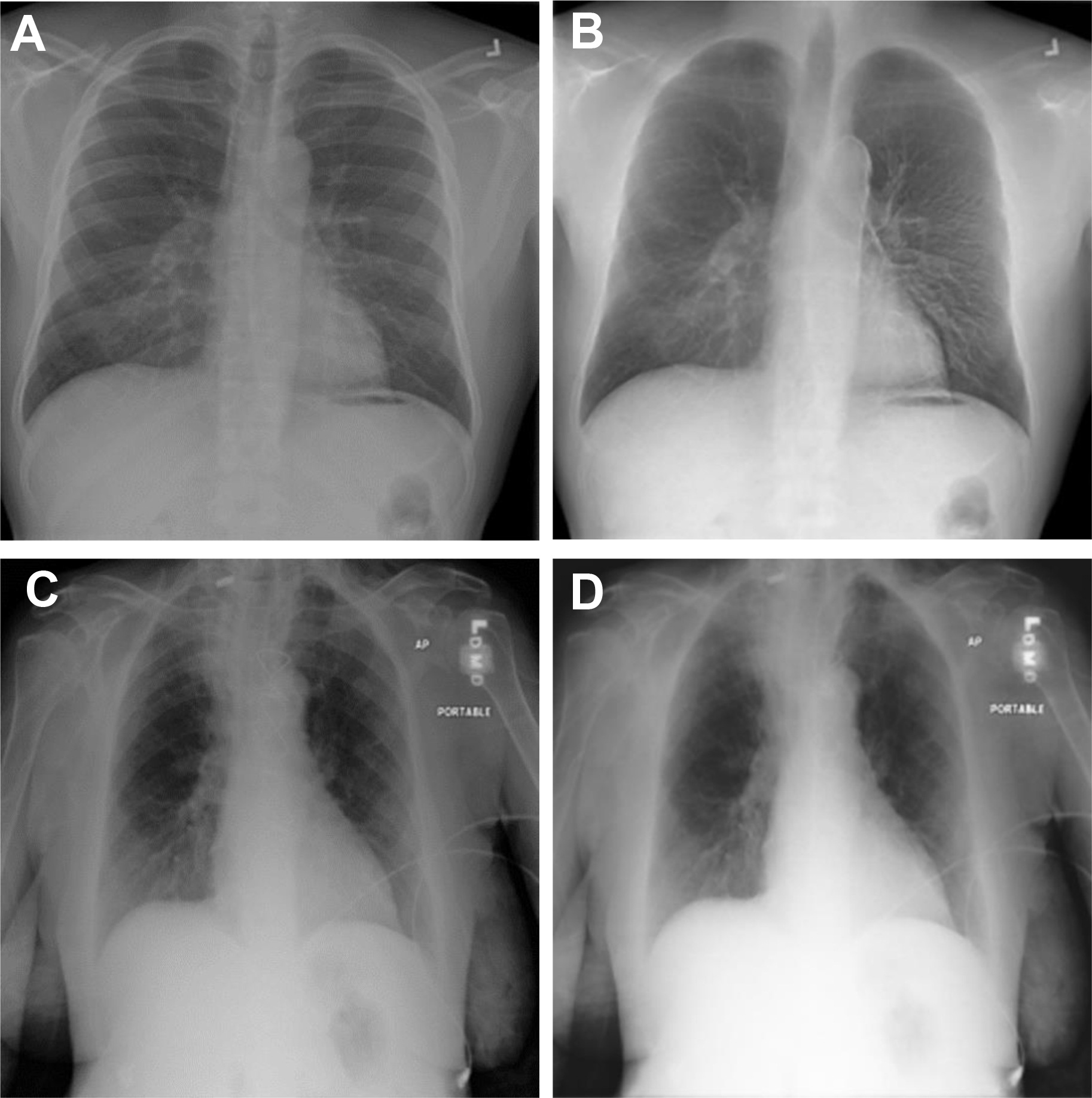
Lesion Detection
Lesion detection is a task of computing the location information of an abnormal lesion in an image, which traditionally involved long processing pipelines. With DL approaches, many of these steps can be avoided, and recently multitask algorithms have achieved lesion detection and segmentation simultaneously in pneumothorax (DSC 0.88), lung nodules (DSC 0.80, 0.82), and rib fractures (DSC 0.72). Although these performances are not fit for clinical use alone, they can be applied to enhance the performance of radiologists in detecting lung nodules and rib fractures in CT.
Classification
Disease diagnosis in chest radiograph
Classification is a task of predicting a category for a presented example, and one of the perfect applications for this is the task of predicting the diagnosis in chest radiograph images. This task can be done as a binary task in which the categories may be normal versus abnormal (AUC 0.98), , normal versus pneumonia (AUC 0.99), pneumothorax versus nonpneumothorax (accuracy 87.3%), and pulmonary tuberculosis versus nontuberculosis (AUC 0.75). A more realistic setting would be to solve this as a multiclass task in which the chest radiograph categories may be critical, urgent, nonurgent, and normal (sensitivities 65%, 76%, 48%, and 71%) or 4 different diseases (AUCs 0.95 for pneumothorax, 0.72 for nodule or mass, 0.91 for opacity, and 0.86 for fracture) or 8 different diseases (average per-class AUC approximately 0.7), or 14 different diseases (average per-class AUC 0.83). The performances for the multiclass algorithms were lower than binary models and were generally good for emphysema, cardiomegaly, and pneumothorax, and poor for infiltration, pneumonia, and mass. However, multiclass algorithms have proven to reduce report time in a simulation study (from 11.2 to 2.7 days for radiographs with critical imaging findings) and improve performance of radiology residents in the emergency department when used as a second reader (sensitivity improved from 66% to 73%). Although perhaps with more limited use, DL-based automatic lung nodule detection algorithms improved nodule detection performances by physicians , or show performance superior to that of human readers.
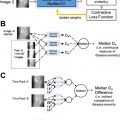
To consider the AI-derived prediction as a second reader, it is also important to understand “how” the algorithm came up with such prediction and radiologic imaging saliency maps are the most common explanation method. Recently, Tang and colleagues used a deep disentangled generative model to generate a patient-specific “normal” chest radiograph image from an abnormal radiograph and obtained residue maps and saliency maps from them ( Fig. 2 ).
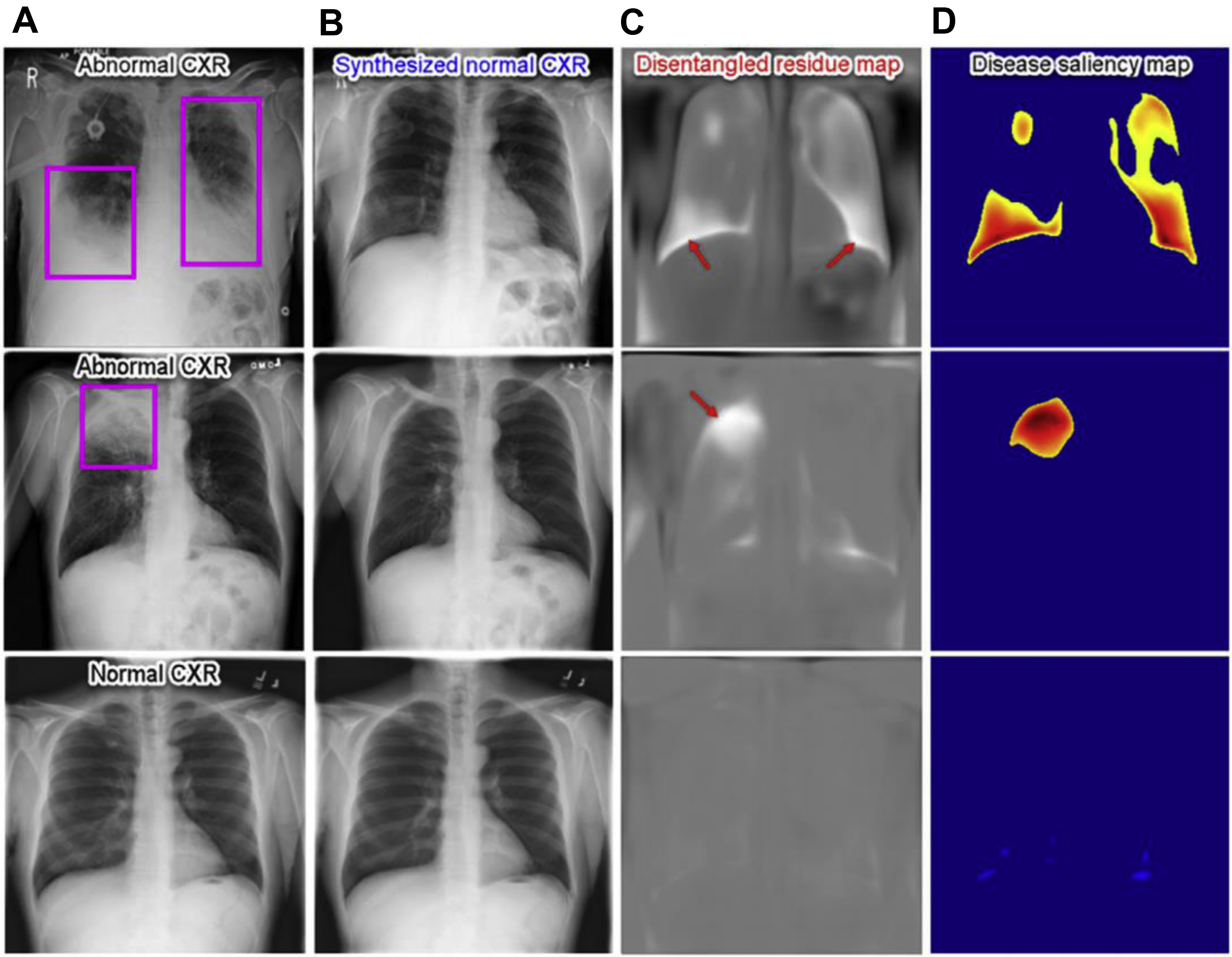
Lung nodule detection and classification in computed tomography
Low-dose chest CT is now the recommended method for lung cancer screening. However, detecting and classifying pulmonary nodules is a time-consuming task and also prone to interobserver and intraobserver variability. AI-derived algorithms have now gone beyond the old computer-aided detection systems and can suggest a possible diagnosis for the automatically detected lung nodules. With DL-derived methods, the nodule classifications do not have to be limited to the hand-crafted features of the nodule, such as size, density, and growth. DL algorithms can be trained to give a probability of malignancy score with excellent performance in predicting cancerous and noncancerous nodules (sensitivity 94.8%, AUCs more than 0.9 ), surpassing the performance of the Lung CT Screening Reporting and Data System (Lung-RADS) in predicting deaths from lung cancer. Algorithms detecting and classifying nodules into 4 , or 6 types (solid, nonsolid, part-solid, calcified, perifissural, and spiculated nodules) have shown performances comparable to human observers, and sometimes better if no previous CT imaging are available. One thing we should keep in mind is that these algorithms were trained on carefully prepared nodule-only data, whereas the real-world data is mixed with nodule and non-nodule diseases. Also, because of the black-box nature of the DL algorithms, it may be difficult to explain why it has come up with such a conclusion or in which step (detection, segmentation, classification) it went wrong.
Classification of diffuse lung disease in computed tomography
Diffuse lung disease includes a group of heterogeneous diseases with considerably different prognoses and treatment. As many of these diseases have similar appearances on CT and tend to have much disagreement between readers, , quantitative tools in CT scans are being used to assist in the diagnosis and disease severity assessment of diseases such as emphysema, cystic fibrosis, asthma, idiopathic pulmonary fibrosis, and hypersensitivity pneumonitis. These quantitative tools have been applied with DL-derived algorithms or texture analysis to automatically assess the extent of systemic sclerosis-related interstitial lung disease (ILD), emphysema, and COPD to show good correlation with pulmonary function tests. DL models have also been used to classify lung parenchyma into regional patterns (ground-glass opacity, consolidation, reticular opacity, emphysema, and honeycombing) or classify lung CT scans according to idiopathic pulmonary fibrosis guidelines achieving human-level accuracy. Although with relatively low performance, ILD classifying models that allow the whole lung as input have been reported , and should be encouraged.
Predicting prognosis
With the emerging field of radiomics and DL, we can now automatically extract large numbers of features from a lesion of interest and use them to predict pathology, prognosis, and mortality. Risk scores can be obtained from images to predict mortality in chest radiographs (mortality rates were 53.0% and 33.9% for high-risk score groups) and CT (C index 0.72 in smoker group). Radiomics can also find certain features that may have a better response with adjuvant chemotherapy, differentiate squamous cell carcinoma from adenocarcinoma (AUC 0.89), or predict epidermal growth factor receptor genotyping in lung adenocarcinoma CT (AUC 0.8). Studies can be designed to predict the time to progression and overall survival in a baseline CT (hazard ratio 2.8, 2.4) or time-series CT (hazard ratio 6.2 in overall survival).
Artificial Intelligence on Coronavirus Disease 2019
In 2020 the world was hit by COVID-19, and up to the point of writing this review, more than 500 DL papers using COVID-19 images have been published. Before the diagnostic test kit was available around the world, many studies were focused on screening COVID-19 in chest radiographs and CT. Although many of them had a good performance, radiologic images have less advantage in diagnosing COVID-19 infection because more than half of the symptomatic patients have a normal chest CT. We are now looking toward using DL to ease the hospital resource allocation in the pandemic. One of those tasks is automatically assessing the severity of patients with COVID-19 by classifying them into severity scores. DL and quantitative analysis can help discriminate between patients with and without COVID-19 (AUC 0.88 for external data), evaluate disease progression, , predict patients who develop ARDS, predict oxygen therapy, intubation, hospitalized days, or mortality. , We hope AI will continue to support us with decisions such as when to image patients for extrapulmonary manisfestations and how to incorporate information about underlying diseases or patient demographics in treating COVID, especially now that vaccines and treatment therapies are starting to be used.
Abdominal imaging applications
Organ Segmentation
Fully automated organ segmentation in the abdominal and pelvic regions must deal with problems such as high anatomic variability, indistinctive boundaries with neighboring structures, and mobility of the patient and organs. This explains why the segmentation Dice scores are approximately 0.95 for the spleen, visceral and subcutaneous adipose tissue, muscle, and vertebrae ; approximately 0.9 and higher for the liver, kidneys, prostate, bladder, and rectum , ; approximately 0.8 and higher for the esophagus, pancreas, , and uterus ; and less than 0.8 for the stomach, colon, and small bowel. There are multiorgan segmentation models that segment several organs at once with equally good accuracies. , The segmentation task is now turning toward more detailed substructures, such as hepatic vessels, Couinaud liver segments, biliary tree anatomy, and prostate zonal anatomy.
Clinicians have been using manual or semiautomated measurements of organs for various medical decisions, and now fully automated segmentation algorithms may assist them in surgical , or radiotherapy planning, or diagnose organomegaly in the spleen and prostate. There are several commercially available liver segmentation software packages and solutions that even have picture archiving and communication system (PACS) interfaces. Measurements from these automated segmentations may be used as biomarkers to assess diseases such as sarcopenia, liver steatosis, liver fibrosis, or cardiovascular events and mortality.
Lesion Detection
Automatically detecting and segmenting a certain tumor or disease has been a popular topic, especially in organs with good organ segmentation. The performances are better for tumors of the liver (DSC 0.83, Fig. 3 ), kidney (DSC 0.87), prostate (detection sensitivity 86%, DSC 0.87), rectum (DSC 0.9), and uterine fibroids (DSC 0.9). Performances are poorer for pancreas tumors (DSC 0.71), cervical tumors (DSC 0.82), and small-sized tumors (detection sensitivity 10% vs 85%, DSC 0.14 vs 0.68 for liver tumor smaller than 1 cm vs larger than 2 cm). A few preliminary studies have focused on segmenting the active and necrotic parts of liver tumors. , This would potentially be helpful in assessing the accurate tumor burden.
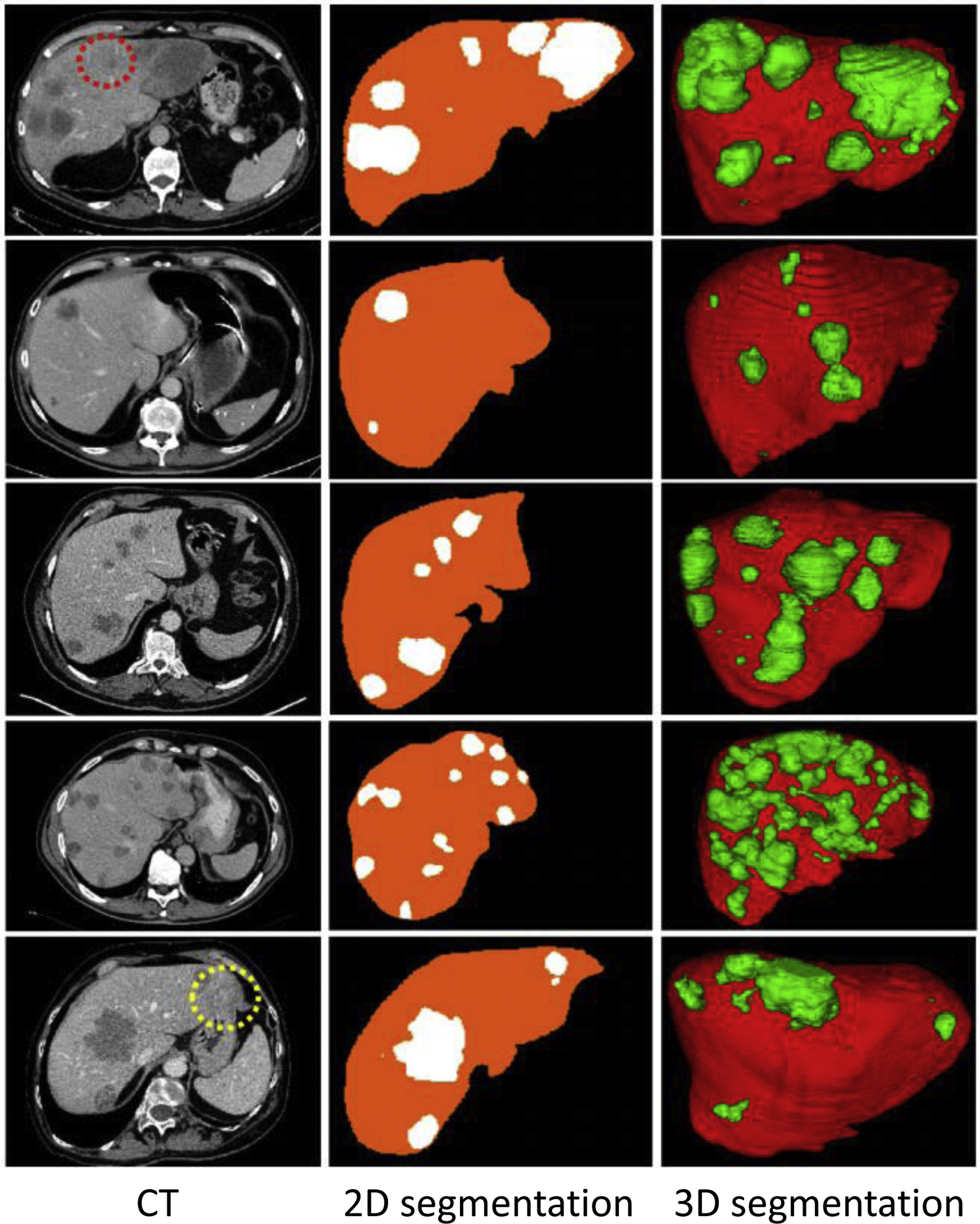
Other nontumoral disease entities such as colonic polyps, abdominal calcified plaque, , hemoperitoneum, pneumoperitoneum, and urinary stones have been targeted for detection and segmentation and have shown promising results. However, more work needs to be done on detecting “universal lesions” on the whole abdomen. For instance, detecting metastatic lymph nodes or multiple diseases (average sensitivity 69.2%, 86.1%) in the entire abdomen and pelvic CT.
Classification
Disease diagnosis
DL-based diagnosis is outperforming the human-made measurements, such as the hepatorenal index method in liver steatosis or PI-RADS (prostate imaging–reporting and data system) in prostate cancer. With the help of U-Net, radiomics, and ensemble DL algorithms, disease diagnosis can be approached as a binary or multiclass classification problem. The task of classifying abdominal tumors into 2 types or multiple types has achieved variable results. Examples include benign or malignant classification in liver tumors on ultrasound (AUC 0.94), pancreas tumors on CT (sensitivity 97%), adrenal tumors on CT (AUC 0.8), kidney tumors on CT (accuracy 77.3%), prostate tumors on magnetic resonance (MR) images (AUC 0.79), ovary tumors on MR (AUC 0.86), cervical tumors on MR (accuracy 0.9%), 6 liver tumor types on MR (sensitivity 82.9%), and PI-RADS classification on MR (moderate agreement with expert radiologists). The interpretation of these performances can sometimes be confusing, because the imaging modality, tumor types, gold-standard methods, and dataset populations vary between studies. Some of the studies show that they achieve similar or better performances than radiologists in predicting pathology-proven diagnosis, but many of the studies lack comparisons with both radiologists’ evaluation and traditional methods.
Sometimes radiologists are challenged with difficult differential diagnoses that have crucial consequences. This is a good situation to use AI-derived algorithms. Some studies have achieved interesting results in differentiating ambiguous lesions, such as fat-poor renal angiomyolipoma from renal cell carcinoma in CT (AUC 0.96), hepatocellular carcinoma (HCC) from intrahepatic cholangiocarcinoma in CT (AUC 0.72), stromal benign prostatic hyperplasia from transitional zone prostate cancer (AUC 0.9), and benign borderline ovarian tumors from malignant ovarian tumors (AUC 0.89). AI algorithms can also lend a hand in stressful tasks such as detecting vessel invasion of pancreatic cancer in CT (AUC 0.85, comparable performance to senior radiologist), or early-stage cervical cancer in MR (AUC 0.9), detecting extraprostatic extension of prostate cancer (AUC 0.88), detecting local recurrence of rectal cancer anastomosis in MR (AUC 0.86), and detecting HCC in patients with cirrhosis (AUC 0.7). They can even be tried on tasks in which radiologists feel less confident, such as differentiating HCC in noncontrast MR, classifying small hypoattenuating hepatic nodules in colorectal carcinoma CT (AUC 0.84, lower than radiologist), and diagnosing appendicitis in acute abdominal pain CT (accuracy more than 90%).
Disease grading
The classification does not have to be limited to traditional labels. Transfer learning radiomics models can be used to classify liver fibrosis in grayscale and elastogram ultrasounds that perform better than prior liver stiffness measurements. Contrast-enhanced CT scans can be used as inputs to classify grades of liver steatosis (AUC of 0.67, 0.85, and 0.97 for predicting MR proton density fat fraction thresholds of 5%, 10%, and 15%) or liver fibrosis (AUC of 0.96, 0.97, and 0.95 for significant fibrosis, advanced fibrosis, and cirrhosis).
Texture analysis and DL-derived classification algorithms use features beyond the human vision, allowing creative classification tasks, such as predicting estimated glomerular filtration rate (correlation coefficient of 0.74) or interstitial fibrosis and tubular atrophy grades (F1 84%) from ultrasound images, distinguishing aldosterone-producing and cortisol-producing functional adrenocortical adenomas in CT (AUC 0.88), classifying dysplasia grades of intraductal papillary mucinous neoplasia in MR (AUC 0.78), differentiating renal cell carcinoma subtypes in MR (accuracy 81.2%), or grading pancreatic neuroendocrine neoplasm histology types in CT (AUC 0.81). Radiomic features have even shown better results than PI-RADS in diagnosing prostate cancer (AUC 0.96 vs 0.88).
Predicting prognosis
The whole point of classifying any disease into stages or categories is to predict the prognosis and plan a treatment strategy. Radiomics features coupled with machine learning approaches are now used to bypass this hand-crafted staging and directly predict clinical outcome, or predict certain gene expression, and even discover new image biomarkers for well-known diseases. Radiomics features extracted from pretreatment radiologic images have been shown to improve the detection of early recurrence, or predict treatment response or overall survival in HCC, , liver metastasis, prostate cancer, and many more malignancies. , Models can predict future events of gastro-esophageal variceal bleeding, hepatic encephalopathy in liver cirrhotic CT, or predict intraoperative blood loss in pernicious placenta previa MR (accuracy 75.6%).
Challenges of artificial intelligence application and future works
There are more than a dozen different kinds of organs in the chest and abdomen, many of which are constantly moving, and each of them can have multiple diseases. This makes it challenging for many AI tasks, including registration, detection, and classification. Currently, most studies are focused on a certain organ, a single phase or sequence, and a specific disease condition, on a carefully collected dataset. However, the real-world task needs more than 1 diagnosis on more than 1 organ, and more research needs to be done on multitask algorithms with a universal approach. Also, the real-world dataset may have a much lower disease prevalence and a broader spectrum of diseases. Thus, more research needs to be done on larger imaging datasets with external validation on data from multiple institutions. The availability of large radiologic datasets is currently a bottleneck for AI research, contributed by many factors including institutional review board approvals, patient privacy and anonymity, the complexities of working with DICOM (digital imaging and communications in medicine) files and their size, and the cost of assembling and maintaining a database. Despite all the efforts to minimize training data, it is still true that where there is no data there is no study. This is proven by how the AI methods thrive on fields with large public datasets (chest radiograph frontal view, lung nodule CT, and liver tumor CT ) and are scarce in fields such as chest radiograph lateral view, bowels, and pelvic organs.
For the same reason described previously, one must be careful when interpreting the results of the chest and abdominal AI studies. The accuracies depend greatly on the dataset, the complexity of the task, how the gold standard was chosen, image modality, scanner types, and protocol. , , The results need to be presented as case-control studies in which the AI results could be statistically compared with human experts, conventionally used measurements, or results of other AI methods.
Currently, the accuracies of these single-task AI algorithms are approximately 80%, and depending on the nature of the task, this may be clinically helpful in the emergency department, improve inter-reader agreements, or monitor disease progression. , To be of more practical value, the algorithms should be ready to incorporate additional information, such as the chief complaint, medical history, and laboratory results, and be able to interact with human corrections, preferably on PACS, ultrasound, and intervention machines. Future AI studies should not dwell on mimicking human radiologists. They should be targeted to outperform the human eye by training on clinical and pathology-proven gold standards.
In conclusion, the chest and abdominal AI studies are latecomers but have advanced immensely in the past few years, in some fields more than others, probably due to the imbalance of dataset availability. Organ segmentation, chest radiograph diagnosis, detection, and classification of lung and liver tumors have relatively better performance.
Clinics care points
- •
Organ segmentation tools will be able to assist in surgical or radiotherapy planning and diagnose diseases such as organomegaly, sarcopenia, and diffuse liver and lung diseases.
- •
Currently, the accuracies of single-task classification algorithms are approximately 80%, but this may still be clinically helpful in the emergency department, improve inter-reader agreements, or monitor disease progression.
- •
Caution is needed in interpreting the accuracies of AI as the studies greatly depend on the data they were trained on.
- •
More clinical validation is needed for AI to be of help to radiologists and clinicians.
Acknowledgments
This research was supported by the Intramural Research Program of the National Institutes of Health Clinical Center.
Funding: Not applicable.
Conflicts of interest: Author R.M. Summers receives royalties from iCAD, ScanMed, Philips, Translation Holdings, and Ping An. His laboratory received research support from Ping An and NVIDIA .
References
1. Itri J.N., Tappouni R.R., McEachern R.O., et. al.: Fundamentals of diagnostic error in imaging. Radiographics. 2018; 38: pp. 1845-1865.Related posts:
 Regulatory Issues and Challenges to Artificial Intelligence Adoption
Regulatory Issues and Challenges to Artificial Intelligence Adoption
 Clinical Artificial Intelligence Applications in Radiology
Clinical Artificial Intelligence Applications in Radiology
 Artificial Intelligence Enabling Radiology Reporting
Artificial Intelligence Enabling Radiology Reporting
 Clinical Artificial Intelligence Applications
Clinical Artificial Intelligence Applications
 Artificial Intelligence for Quality Improvement in Radiology
Artificial Intelligence for Quality Improvement in Radiology
 Clinical Artificial Intelligence Applications
Clinical Artificial Intelligence Applications

Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


