22.1 Clinical Application and Relevance
How well an individual radiologist performs is a complex process that has been investigated for well over 70 years (Garland, 1949; Yerushalmy, 1969) and continues to be a topic of considerable research attention. Given the known vagaries of radiological performance, it is important that health providers, radiological societies, as well as individual radiologists know that every radiologist is working to an acceptable clinical standard, both in identifying abnormal radiological appearance correctly in a timely manner, and also in agreeing with colleagues on the radiological outcome of a particular case. Whilst real-world performance data are often readily available concerning how an individual reports routine clinical cases, inherently such data are limited as performance metrics depend entirely upon the specific cases that individual has examined and reported on. This is particularly a very pressing issue in radiological screening domains where abnormal presentation rates are very rare and any feedback on decisions may not occur in an effective and timely manner to provide suitable ongoing learning, so that any errors of omission and commission can become compounded.
For instance, breast screening in the UK typically involves a woman being imaged every 3 years. If a small abnormality is missed then it may well be another 3 years before it is subsequently identified, by which time the disease can have progressed. Radiologists receive no feedback on their original incorrect decision until that subsequent date, apart from any interval cancers that might arise between screening rounds. Clearly this is a poor learning situation, especially for new personnel in the breast screening program, or for readers who have a low volume of reading. An approach is needed where rapid feedback occurs so that all radiologists can learn from their clinical oversights and from expert radiological opinions. In a screening situation a radiologist may well over-recall cases, in which case they do gain feedback from subsequent examinations of the woman, but this is at a psychological and physical cost to the woman, an increased financial cost to the screening program for unnecessary tests, and increased cost to the radiologist in terms of time for additional tests.
One appropriate approach to provide a timely and useful personal performance assessment is to use standardized test sets of cases that have already been reported on and so are of known clinical outcome. These sets are then read by radiologists with feedback provided to each individual so as to provide both clinical and comparative peer data. Such sets can be utilized to give peer review and feedback, as well as have a potential quality assurance function. In this chapter the use of test sets is introduced and the PERFORMS self-assessment scheme, which is used primarily in the UK’s breast screening program, is discussed to illustrate the utility of using test sets appropriately. Whilst all medical imaging researchers use a set of test images in their research, the use described here is concerned with large sets of ever-changing images that are used nationally and by the full population of readers in the domain.
22.2 Breast Screening
Approximately one in eight women will be affected by breast cancer during their lifetime with more than 80% of breast cancers occurring in women over the age of 50. The purpose of breast screening is to detect potential disease at an early stage when there is a better chance of successful treatment and when any changes in the breast are too small to be detected by breast self-examination alone. Importantly, breast screening is not the identification per se of breast cancer but rather whether a case (i.e., a person) should be recalled or not for further investigation as to whether she has an abnormality.
Breast screening in the UK currently entails all women aged between 50 and 70 screened every 3 years, with age extension trials extending this range from 47 to 73 years. Full-field digital mammography (FFDM) is employed where two views of the breast, mediolateral oblique (MLO) and craniocaudal (CC), are taken – these four images then comprise a case. Such an approach is common internationally, although screening frequency is often every 2 years or annually. The age range of women screened in the UK is fairly representative of many other countries.
In the UK the resultant mammographic images are examined on high-resolution mammography workstations for signs of abnormality, by specialized consultant radiologists and advanced practitioner radiographers (specially trained technologists) – hereafter both are jointly termed “readers” for simplicity. Double reading is used where two readers independently report each case, with arbitration being used where there is disagreement. One of the outcomes of screening is that a woman is “returned to screen,” where the images are considered to be normal or definitely benign and she is then simply invited for breast screening again in 3 years. Alternatively, a woman is recalled for assessment if an abnormality is suspected. At recall, further imaging with different mammography views, ultrasound, magnetic resonance imaging (MRI), or digital breast tomosynthesis (DBT) and fine-needle aspiration biopsy may be performed. Cases recalled for assessment are then discussed at a multidisciplinary team meeting which determines the clinical outcome.
The UK screening program emphasizes high specificity (low percentage of false positives (FPs)) and high sensitivity (high percentage of true positives (TPs)). A key performance measure, in addition to cancer detection performance, is the number of women recalled after screening for follow-up examinations (about 4% overall nationally), to achieve a cancer detection rate of about 8%. This low figure means that overall few UK women are needlessly recalled. Given the low incidence of breast cancer, approximately 7 per 1000 women screened, any given reader can at best expect to see, if any, only a few malignant cases per week. Feedback on cases that have been recalled is relatively rapid (pending further imaging or biopsy), but information on false-negative (FN) decisions by the reader can be extremely lengthy, given that a woman may not return for a future screen for 2–3 years depending on the screening interval.
Latest data (National Health Service, 2017) for the breast screening program in England show that in early 2016 some 5.83 million women aged 53–70 were eligible for screening and 4.40 million had been screened in the past 3 years, covering over 70% of eligible women. In 2015–2016 some 2.85 million women were invited for screening with 2.16 million women aged over 45 years actually screened in the 80 English breast screening units. Uptake of screening varies across the country due to numerous, mainly social, factors. In 2016 some 7.8% of prevalent round women (first-time screened) were subsequently assessed with 3% of incident screened women (who had been previously screened) also recalled. The cancer detection rate for women aged 50–70 years was 8.2% per 1000 women screened. Of these, 20.9% were noninvasive cancers and 79.1% were invasive, and 41.2% had cancers 15 mm or less.
Across the UK there are now some 108 screening centers and currently over 810 readers. All screening cases are double-read, where the second reader is not aware of the first reader’s decisions, as this has been found to increase abnormality detection and any disagreements are addressed via arbitration. In the UK each radiologist must annually examine at least 5000 cases in order to be a reader in the national screening program – this number allows them to develop a detailed appreciation of the wide variety of normal appearances, thereby increasing their ability to identify early abnormal appearances (Royal College of Radiologists, 1990). In practice, many radiologists read far more cases than this, with several reporting reading in excess of 20,000 cases a year. An individual reading 5000 cases a year would, on average, expect to be presented with one or two abnormal cases a week out of some 120 cases examined. With such a very low abnormality presentation rate, maintaining an acceptable level of performance can be difficult, confirming the importance of undertaking test sets regularly in such a domain.
22.3 The PERFORMS Scheme
The PERFORMS scheme (Gale, 2003; Gale and Walker, 1991) is now in its 30th year of continuous implementation across the UK. It is the leading, and first, international self-assessment scheme in radiology. The scheme provides self-assessment, peer review, training, and quality assurance. It was established and initiated in parallel with the introduction in 1988 of UK nationwide breast cancer screening following the Forrest (1986) report and was developed in conjunction with the Royal College of Radiologists and the UK National Health Service (NHS) Breast Screening Programme (NHSBSP). Taking part in the scheme is a mandated activity for all readers and has been independently supported and recommended by various government investigations into real-life breast screening incidents where failures in reporting adequately have been found. For instance, the Burns (2011) review found a radiologist had missed 61 cancers and so the PERFORMS scheme was mandated for all readers. Where appropriate, readers receive continuous medical education points for participation, and technologists receive professional reward for participation.
The scheme grew out of the development of an early computer-aided system, premeditated on identifying key mammographic features correctly, to help identify abnormalities (Gale et al., 1987). Such an approach has somewhat limited utility as features are not universally reported by different readers in the same manner.
Breast screening in the UK has evolved over several incremental stages (Figure 22.1). When screening was started, using only MLO mammographic film imaging, the PERFORMS scheme was designed and deployed using single MLO images as a paper-based system where readers’ responses were recorded and mailed back for analyses, with subsequent feedback again being mailed back to users. Of necessity this offered delayed and somewhat simplistic feedback to readers on their performance. Sets of screening cases were couriered around the UK, coupled with reporting books which participants completed. Two-view screening (MLO and CC) was soon introduced, coupled with double reading of all cases and the scheme developed in parallel. The PERFORMS scheme subsequently evolved using personal digital assistants (PDAs) to provide rapid feedback to readers immediately after they had read the set of test cases. This was then followed by further development using dedicated tablet computers as screening progressed to using two-view FFDM. With the expansion of new technology a cloud-based approach became practical.
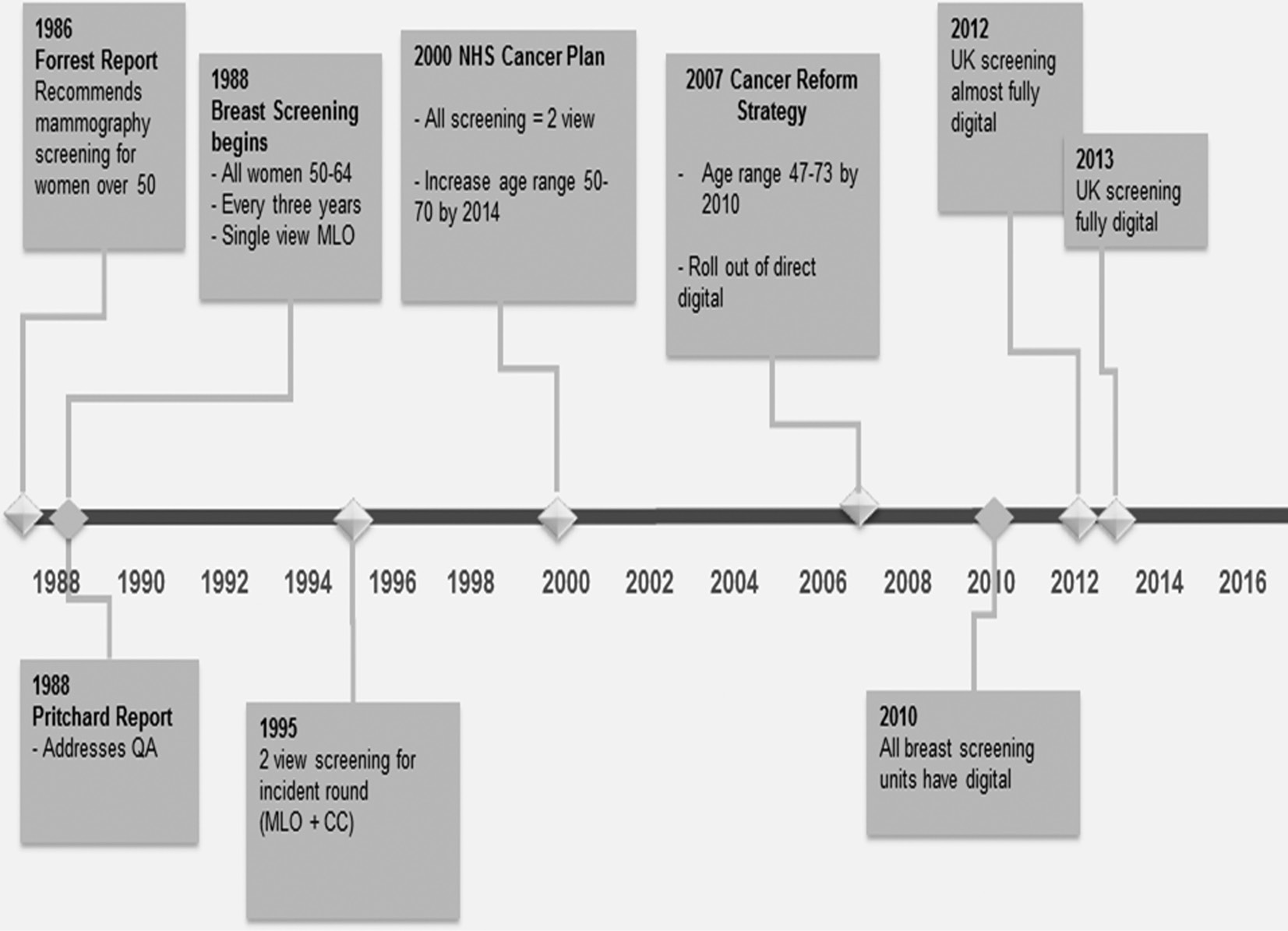
Figure 22.1 The development of national breast screening in the UK. CC, craniocaudal; NHS, National Health Service; MLO, mediolateral oblique; QA, quality assurance.
The current organization is a very complex online training scheme with extensive immersive educational approaches. All readers have their own confidential web pages from where they can log in to a dedicated web-based reporting app; download numerous sets of test cases at will; take part and report cases; subsequently view personalized performance reports; and enter into online peer and expert discussions on cases, and other associated activities. After taking part, immediate feedback is provided by the app itself which allows readers instantly to revisit any, or all, cases and examine annotated expert radiological pictorial and textual feedback as well as associated pathology information where relevant. Statistically underperforming individuals (mild and also severe statistical outliers) are identified and followed up, with further training offered and other support mechanisms. Additionally, ongoing work is incorporating artificial intelligence and augmented-reality approaches to provide yet greater enhanced educational benefit (Tang et al., 2017).
As a range of vendor workstations are installed across the UK, each with its own dedicated Digital Imaging and Communications in Medicine (DICOM) viewing software, the decision was taken not to develop the current scheme software simply as a version of a DICOM viewer to install on every workstation. With such an approach, any variations found in reader performance could simply be due to them using novel software or a slightly different implementation of the software in different screening centers, rather than actual performance differences.
Instead readers simply use whatever workstation software they usually employ to examine the images and use the PERFORMS app, typically running on a laptop or other device (iPad, PC, MAC) beside the workstation (although it can also run on the workstation itself) to report the cases and receive feedback. The scheme then easily accommodates any vendor software updates or change in vendor supplier by a screening center. The app has been carefully developed to have high usability and to be very transparent. Figure 22.2 shows a typical setup where the radiologist has the list of available test cases on his radiological information system monitor on the left and is examining the relevant DICOM FFDM images on the twin mammographic monitors. In this example he is then reporting his various decisions about the case into the PERFORMS app which is running on an iPad in front of him.

Figure 22.2 Reporting PERFORMS cases using an iPad.
After reporting on a set of cases, readers can log into their private web pages at any time and view how their anonymous peers have reported the same cases. The web-based feedback is updated on a daily basis and so readers can repeatedly visit the website and check how they performed compared to all their peers who have taken part to date. A range of reports are produced annually for individual screeners comparing their performances with those of anonymous peers, as well as management reports for the screening program and related professional bodies. Over 2000 detailed individual participation and organizational management reports are regularly produced per annum.
22.4 Reader Participation
When the scheme began, breast screening had just been initiated in the UK in 1988 and the first trial of the test sets was across three health regions using 30 radiologists. As would be expected in such a young discipline, data readily demonstrated considerable variation in skills in identifying key mammographic features. Subsequently breast screening has expanded and recent data over the past five rounds (Figure 22.3) show that over 811 readers currently participate annually. The recent growth in technologists taking part in routine screening can be seen. The “other” group comprises a range of other health professionals who also interpret screening cases.

Figure 22.3 Reader participation in recent rounds.
22.5 User Feedback
When implementing test sets as an educational scheme it is always useful to gather reader feedback as a means of gauging whether the users themselves find participation a meaningful exercise. As part of participation in the PERFORMS scheme such reader feedback is routinely and automatically collected which then helps define modifications and future extensions of the approach. Examples of reader feedback are shown in Figure 22.4. In our experience such feedback is overwhelmingly positive, despite the fact that participation in the test sets effectively increases readers’ daily workload. Any negative feedback is immediately addressed. An example of the usefulness of feedback is that we had implemented a function to collect data on breast density. After some time the feedback on this from readers was that they did not like to report density as this was outside their normal screening behavior and hence this function in the app was subsequently disabled.

Figure 22.4 User feedback captured in the PERFORMS app.
22.6 Perceptual Theory and Test Sets
What then are the perceptual and cognitive issues facing readers in this domain and particularly with regard to related test sets? In the UK it was expected that some 60 screening cases an hour could be reported by radiologists, and any casual observation of radiologists reading such cases confirms that they can sometimes spend only a matter of seconds examining a case. Theoretically understanding how readers achieve this level of proficiency then is important so as to implement and interpret test set data appropriately.
In common with many other researchers in this domain, a conceptual explanatory model of radiological performance is used based largely on Neisser’s (1976) schematic map concept. This concept proposes that cognitive schema of the current environment directs perceptual exploration, which then samples the real present environment, which in turn modifies the cognitive map of the environment. Such a circular approach to ever-changing plans emphasizes the role of saccadic eye movements in gathering the appropriate image information and how that information then affects subsequent behavior. This is the basis of an approach to perception known as active vision (Findlay and Gilchrist, 2003). Somewhat based on this then is the established work of Kundel and colleagues (Krupinski, 1996; Kundel et al., 1978) and others (Gale, 1997) arguing that the medical image inspection process incorporates global and focal perceptual processes. Such an approach describes both the acquisition of radiological knowledge as well as how experienced readers’ skills subsequently are almost automatically and quickly performed.
Mistakes can occur for various reasons in examining images. Some are due to organizational reasons and human factor issues. With regard to the readers themselves in examining the images, such a model enables FN errors to be classified as being due to visual search (broadly meaning that the reader did not look at or look near an abnormality location on a mammogram), a detection (perceptual) error where there is evidence that the reader has looked at (visually fixated upon) the abnormality site but then not reported it, and an interpretation (cognitive) error, where the reader has looked at the abnormality site, detected features (either by virtue of having recorded a key feature or features at that location or in eye movement studies has visually dwelt upon that area for longer than a criterion time), yet failed to then appropriately interpret that information as indicative of abnormality.
Various research studies have demonstrated that approximately 24–30% of FN errors are due to errors of visual search, some 25% perceptual, and 45–52% cognitive (Krupinski, 1996; Kundel et al., 1978). The split of types of error classification found will vary depending upon the study design, reader experience, and images used. The exact percentages are not necessarily important but the overall split of FNs over these three types of processes is important as it demonstrates that readers often foveally examine sites of abnormality, but then for various reasons fail to correctly identify and report an abnormality. This information can then be used to design appropriate targeted training programs. Test sets alone can tease out FN errors due to perceptual/detection and cognitive/interpretation factors. Similarly, FP errors can be identified by examining where a reader has specified the location of a feature and where this is incorrect. To identify FN errors due to visual search, however, we monitor the eye movements of readers as they examine a set of cases and then interactively give them feedback to help them improve how they visually inspect these mammographic images. Such a full educational approach of providing feedback on all types of errors is not really feasible without the use of test sets.
To illustrate this, Figure 22.5 shows examples of seven mammographic cases containing abnormalities (abnormality highlighted by an outlined area) from a test set of cases being examined by four inexperienced readers (Chen, 2010). The patterns of scanning are shown as lines representing saccadic eye movements joining fixations (circles) together. Where many fixations occur, overlapping circles are shown. Each column represents one observer’s eye movements on the set of images and each row represents one mammographic case examined by different observers.

Figure 22.5 Visual search behavior of inexperienced observers.
Errors of visual search, detection, and interpretation are shown in several of these cases. For instance, observer 4, when examining cases B and G, fails to look at or near the abnormality. The same is true for observers 1 and 2 when examining case G. A detection error is shown by observer 1 with case A where the reader fixates a feature but fails to report it. An interpretation example is shown by observer 3 with case G where the person fixates the feature, reports it, but then does not interpret this information as representing an abnormality.
In the PERFORMS scheme, readers examine a case and locate and identify several different types of key mammographic appearances, such as: well-defined mass; ill-defined mass; calcifications; architectural distortion; asymmetry; speculate mass; diffuse calcification. Readers can be instructed to identify additional features or feature subclasses can be used for particular purposes depending upon the study purpose. As well as locating and identifying features, readers rate each feature in terms of suspiciousness. They then classify each breast image overall as regards recall or not recall. In doing this they use the UK screening classification rating scale or when the scheme is being used outside the UK they use the appropriate Breast Imaging Reporting and Data System (BI-RADS) (Sickles et al., 2013) rating scale.
All test cases have their key mammographic features first identified by a panel of expert breast radiologists who also rate case density, case difficulty, and other factors. By inspecting a reader’s feature identifications against the expert panel decisions it is possible to assess whether the observer has identified appropriate features or not (possible detection error) and if appropriately identified, has the reader then reported them suitably (possible interpretation error)? Where a reader is found to have difficulty in identifying appropriate features then the individual can be pointed to additional training test sets which are geared to improve identification performance of particular features.
The type of error can also be directly related to specific mammographic features (Figure 22.6). For instance, across three rounds of the scheme (360 test cases) it was found that architectural distortions/asymmetry, calcifications, and masses were more often undetected rather than reported but then misinterpreted. Out of these features, masses were the most often missed feature, which is somewhat surprising given that these would be a larger visual target than the other features.

Figure 22.6 Error types and mammographic features. AD/Asym, architectural distortion/asymmetry; Calc, calcification.
22.7 Test Set Data and Real-Life Data
In the NHSBSP, readers’ real-life data are recorded, providing important measures for individuals concerning their performance (National Health Service, 2017). However, given that cancer occurrence is about seven out of 1000, an individual’s annual sensitivity measure is based solely on a very small number (~35) of abnormal cases out of the 5000 cases examined (the recommended reading volume per year per reader in the UK). Picking up, or missing, a very small number of cancer cases will then lead to a relatively large difference in sensitivity measure in readers’ annual performance review. Hence any report of an individual’s real-life screening performance must be based on several years of screening in order to encompass a representative number of cancer cases. This is where using test sets to assess performance is important, as such sets can give rapid feedback on an individual’s skills.
Recently, an increasing number of new readers have been introduced to the UK NHSBSP. Additionally, the UK has welcomed several locum readers to help the recent workforce issue of a shortage of radiologists. It is difficult to gauge the skill levels of such new or locum readers without the use of appropriate test sets to evaluate their reader performances as compared with all their peers.
A key aspect of the use of test sets is whether what they measure actually relates to real clinical practice. In the PERFORMS scheme the variables recorded are based upon the routine measures used in everyday breast screening in the UK. However, the nature of any test set is that the exemplar cases used must be challenging enough to be able to tease out any performance differences between participants as otherwise a test set is inadequate. This means that a set of difficult test cases has to be carefully derived. However, case difficulty is fairly subjective and so the best way to select cases is to employ a panel of experienced radiologists, as opposed to a single expert, to select the cases. The latter approach of using a single expert is fraught with difficulty as our data clearly demonstrate that what comprises a difficult case for one experienced radiologist can sometimes be a very simple case for another.
We use a panel of expert radiologists to gauge case difficulty as well as monitoring reported case difficulty by readers themselves. Sometimes somewhat surprising findings can occur and cases that experts consider to be difficult may not generally be considered so by large numbers of readers. This raises an interesting question concerning expertise as clearly the experienced expert readers are identifying very subtle indicators on such images that imply difficulty which the majority of readers may not be. Again, this is why using a single expert radiologist to define a test set is a mistake.
For instance, in one study (Scott and Gale, 2005) we examined data concerning 15 expert breast radiologists and approximately 400 other readers on 180 test cases. When experts were selecting cases to use in the scheme they were asked to rate case difficulty. Whilst individual differences between experts were found, they overall rated (Figure 22.7A) the malignant and benign cases as significantly more difficult than the challenging normal cases. There was no significant difference between the benign and malignant cases on the case difficulty measure. Subsequently, the 400 readers reported the cases, where they were not asked specifically about case difficulty but were asked for other information, including whether each case should be recalled or not. Taking the number of errors readers made in each class of image as a surrogate measure of case difficulty then conversely, for these cases, there were fewer errors on the malignant cases as compared to the benign and normal ones, with most errors on the normals (Figure 22.7B). This is the reverse finding of what was expected from the experts’ ratings of case difficulty.

Figure 22.7 (A) Experts’ rating of difficulty and (B) readers’ incorrect decisions.
Inherently, reporting test set cases is essentially the same task as routine everyday reporting and so similar performance measures should be found for an individual in real life and also whilst reading test sets. However, major differences between the two situations exist that must be acknowledged when interpreting results of test set implementation. Firstly, the prevalence of abnormal cases in the test case set may not relate to real-life prevalence. For instance, in breast screening to have a test set of cases with a similar prevalence of abnormality as in real life, where prevalence is about seven abnormalities per 1000 cases, is quite logistically challenging and so weighted test sets of selected challenging cases are used instead, with more benign and malignant cases than would be found in real-life screening. In the UK with an individual reading 5000 cases a year then we estimate that reading our full scheme per year gives them the equivalent experience of challenging abnormal cases as they would experience when reading several years’ worth of routine screening cases.
The difficulty of test cases will usually be much harder than routinely found because the cases need to identify individuals who are having difficulty with certain appearances of cases so that they may be offered further training. Inevitably the desire to use challenging cases may mean that unusual and rare abnormal, benign, and normal appearances are employed in the case selection.
The measures used in reporting test cases and in reporting real-life cases may well vary. For instance, in real life, measures of sensitivity and specificity are straightforward to define and for a reader to understand and utilize in clinical practice. In our test sets we use the number of cases correctly returned to screen as a measure of specificity and number of cases correctly recalled as a measure of sensitivity. In our research in medical imaging perception, typically receiver operating characteristic (ROC) and free-response ROC (FROC) are used alongside multiple reader, multiple case (MRMC) designs. ROC analyses have associated measures of Az or area under the curve (AUC) that represent the trade-off between sensitivity and specificity as readers vary their decision criteria about cases. Jackknife free-response ROC (JAFROC) uses another type of figure of merit as a performance measure. Whilst such experimental approaches and measures are experimentally important, it is essential that such measures also make sense to clinicians so that they can use the data to improve their daily clinical behavior. For instance, in our experience, the vast majority of radiologists simply rely on us translating their data into sensitivity and specificity measures to guide their everyday clinical practice.
The readers’ knowledge that these are test cases may well affect how they perform and the readers’ potentially differing attitude to reading test cases as compared to routine radiology reporting is important. However, such factors apply to all readers of the same test set and so it is reasonable to compare readers’ data across such cases. Asking busy clinicians to read test cases on top of their normal workload has to be approached appropriately, as clearly the amount of available free clinical time a reader has to take part in reading a set of test cases is limited and the purpose and benefits of participation have to be clearly communicated to each individual. Furthermore, the management outcome of the reader’s performance in a test set is also important – whether data are anonymous and not reported to a user’s line manager (in general our own approach) or otherwise.
Consequently, whilst real-life and test set reading are equivalent, it is possible that different performance values are found. In the PERFORMS scheme we use case sets of 60, although in practice any size of case set can be employed, with the presentation order randomized for every participant. Readers examine two such sets a year as this fits into the needs of the screening program. In the UK, a reader would typically read 60 real-life screening cases in an hour whereas we find that the average reader takes longer to read test sets despite the fact that the cases are extremely easy to report and user-friendly; this increased time largely reflects the additional care readers take when participating in test case reading.
Unless a single test set is used repeatedly (which in general is not to be recommended as in our experience readers can rapidly learn the appearances of the cases, especially when these are challenging cases), over time with administering different test cases there has to be inherent variability in the mix of cases and in their apparent difficulty. In the PERFORMS scheme we assess each reader against known pathology and initially against an expert radiological panel decision of recall/not recall. Once all readers have taken part then we change the second comparison to one of peer comparison. Essentially we begin by assessing how good an individual is against experts (an achievable level of radiological decision making) and then against peers (an acceptable level of radiological performance), so addressing the question of “if this woman presented anywhere in the UK would she be treated in the same manner?” No predetermined performance pass marks are used in this process.
Another related scheme which we run (IMPROVE) is geared specifically to address the learning achievements of individual technologists as they are trained. For this we test readers’ skills early on in, or before, training and then again at the end. In doing so we provide no feedback until after the second time and pass marks of acceptable performances are used – the performance benchmarks are defined by a panel of expert radiologists for the specific IMPROVE case set used.
The PERFORMS self-assessment scheme has good content validity as it uses real-life screening cases and logically also has good content validity as the cases evidence the same mammographic features as found in real life. However, criterion validity is important and so regular comparisons between test and real-life data are important. We have regularly examined such a relationship over the past years.
Initially, data from the first few rounds of the scheme were analyzed and compared to the real-life data of radiologists over a 5-year period as breast screening was being introduced nationally. At that time the number of radiologists in breast screening overall was small but expanding rapidly and only 36 radiologists allowed access to their real-life performance data for comparison purposes. The mammographic features which were missed in the PERFORMS scheme and those that were recorded in an interval cancer database were examined (Cowley and Gale, 1999). The proportions of features missed were very similar, demonstrating that readers had similar difficulty with these features both in real life and in the scheme.
The number of missed cancers on the PERFORMS set were significantly correlated with real-life sensitivity measures from 1996 and 1997. Readers’ real-life screening recall rates were correlated with PERFORMS measures of correct recall (a measure of sensitivity) and correct return to screen (a measure of specificity). Very detailed performance data of three radiologists were also examined, as compared to their performances on the PERFORMS scheme, and some significant correlations were found, although the very small sample size here was used primarily as a means to explore in detail how to compare interval cancer data and test set data.
A difficulty for such early comparisons of performance between real-life and test set data relates to the images themselves. At that time radiographic film was in use and so to construct test sets meant copying interesting films. The quality of initial copies may inherently not have been as good as the originals. Mammographic films subsequently were digitized and test sets then printed out using a dedicated mammographic printer. With the advent of digital mammography the construction of tests sets has become greatly simplified.
Subsequent work (Scott et al., 2009) studied the relationship between different types of readers in one UK health region. Initially data for 48 readers were examined using data from the national NHS National Breast Screening System (NBSS) database. Real-life data were extracted from NBSS for the years 2005 and 2006 and this information was compared to known PERFORMS data for the similar time frame. The test set data were based on individuals’ scores as compared to the majority decisions of all readers for these test cases as well as known pathology. A range of measures were examined which thoroughly encompassed readers’ performances. These included FP, FN, TP, and TN decisions as well as positive predictive value (PPV). Data were further considered as either first or second reader where possible.
As a measure of FN the real-life missed cancers (i.e., incorrectly returned cases in routine screening) were compared to missed cancers in PERFORMS test sets. Additionally the miss rate on the scheme and in real life was compared as another FN measure. The incorrect recall percentage on PERFORMS cases was compared to the percentage of cases in real life which were arbitrated and returned to routine screening and these were taken as FP comparisons.
Three measured comparisons were considered as representing TP evaluations: real-life PPV and PPV on PERFORMS; correct recall percentage in real life and on PERFORMS; and cancer detection in real life and on PERFORMS. TN comparisons were based on real-life specificity and correct return to screen percentages on PERFORMS. Significant positive correlations were found between the PERFORMS data and most of these real-life measures. Current research is eliciting ethical agreements from all readers across England, a large cohort of circa 700, to allow access to their real-life screening data records so as to be able to relate these anonymously to data from the PERFORMS scheme.
Related posts:
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


