Fig. 5.1
Definitions of target volumes
This chapter introduces the automated segmentation approaches for the GTV, the basics of CTV-to-PTV margins, and computational determination of the CTV-to-PTV margin based on statistical shape models.
5.2 Automated Segmentation of GTV
The uncertainties of GTV regions have a high impact on the precision of the entire radiation treatment course including treatment planning and patient positioning (Weiss and Hess 2003). The CTV and PTV in the RTP are determined based on the GTV regions. In particular, the GTV is critical in stereotactic body radiation therapy (SBRT), as highly precise positioning is required to deliver a higher dose per fraction to tumors. Once the GTV regions have been estimated, the CTVs are automatically determined based on the GTV itself or extending the GTV with microscopic invasion. The major reasons for the necessity of computer-assisted delineation of the GTV and CTV are given below:
The GTVs are the fundamental regions used to determine the PTV regions, which are the actual target regions in radiation treatment planning and patient setup. Therefore, a number of automated segmentation approaches of the GTVs have been studied to mitigate the intra- and inter-planner variability, to reduce planning time, and to increase the segmentation accuracy of the GTV (Rousson et al. 2005; Biehl et al. 2006; Aristophanous et al. 2007; El Naqa et al. 2007; Geets et al. 2007; Day et al. 2009; Belhassen and Zaidi 2010; Kerhet et al. 2010; Zhang et al. 2010; Hatt et al. 2011; Niyazi et al. 2013; Jin et al. 2014).
- 1.
Low reproducibility: There are large intra- and interobserver variabilities of GTV contours determined by radiation oncologists (Leunens et al. 1993; van de Steene et al. 2002; Bradley et al. 2004; Chao et al. 2007). Leunens et al. (1993) reported that the results of their study on brain tumors demonstrated that subjective interpretation (manual delineation) of the tumor extent might be one of the largest factors contributing to the overall uncertainty in radiation treatment planning.
- 2.
Tedious and time-consuming manual contouring: According to Chao’s study (Chao et al. 2007), the average percentage of time saved by contouring using a computer-assisted method is 26–29 % for experienced physicians and 38–47 % for less experienced physicians.
The automated segmentation approaches can be categorized into two major types: positron emission tomography (PET)-based and PET/CT-based. PET-based approaches are based on model-based methods (Rousson et al. 2005), thresholding of the standardized uptake value (SUV) (Biehl et al. 2006; Zhang et al. 2010), region-growing methods using the SUV (Day et al. 2009), pixel-clustering-based segmentation (Aristophanous et al. 2007), gradient-based segmentation methods (Geets et al. 2007), the fuzzy locally adaptive Bayesian approach (Hatt et al. 2011), the fuzzy c-means algorithm (Belhassen and Zaidi 2010), the total lesion glycolysis (TLG) algorithm of PET Response Criteria in Solid Tumors (PERCIST) (Niyazi et al. 2013), and a machine-learning framework to assist in the threshold-based segmentation (Kerhet et al. 2010).
PET/CT-based approaches are based on a multivalued level set method that provides a feasible and accurate framework to combine imaging data obtained from different modalities (PET/CT) (El Naqa et al. 2007) and an optimum contour selection (OCS) method for segmentation of lung GTV regions using a level set method (Jin et al. 2014).
In this section, since the textbook focused on dealing with theoretically general approaches, the authors introduced pixel-clustering-based segmentation (Aristophanous et al. 2007), the OCS method (Jin et al. 2014), and the multivalued level set method (El Naqa et al. 2007).
5.2.1 Pixel-Clustering-Based Segmentation
Aristophanous et al. (2007) developed a pixel-clustering-based segmentation technique on selected PET tumor regions from non-small cell lung cancer patients. The general algorithm of the pixel-clustering-based segmentation approach with a Gaussian mixture model (GMM) to classify voxels into tumor and normal tissue voxels is described in this section. The clustering is referred to as “unsupervised learning” and does not require teacher signals (i.e., answers) as does “supervised learning” such as an artificial neural network. The basic idea of the pixel-clustering-based segmentation is to classify voxels into two classes, i.e., tumor and normal tissue voxels, by clustering the voxels according to the maximum a posteriori probability obtained by Bayes’ theorem (Aristophanous et al. 2007).
Let a region of interest (ROI) in an objective image be a vector x = (x 1, x 2, … , x N ), where x i is the intensity at voxel i, and N is the number of voxels in the ROI. The voxel intensity is regarded as the random variable, which is assumed to be independent and identically distributed with a probability density function f(x i ). Suppose that we have a set of K density functions, f k (x i | θ k ), parameterized by θ k , where k is the class number (k = 1 , 2 , … , K; K, the number of classes), called component densities (or classes). Let the probability density function of the voxel intensity x i given by θ k be a Gaussian function, which can be expressed by

where μ k and σ k are the mean value and standard deviation in the kth class, respectively. Then, the probability density function of the voxel intensity x i given by a parameter vector Ψ = (π 1, π 2, … , π K , θ 1, θ 2, … , θ K )(π k , mixing proportions) is defined by

The mixing proportion π k , which is regarded as the probability of belonging to a class k, satisfies the following conditions:

Let  be a class random vector, where
be a class random vector, where  is defined as
is defined as

The class random vector Z (i) follows a multinomial distribution. In accordance with Bayes’ theorem, the posterior probability that Z (i) = k when a voxel intensity x i and a parameter vector Ψ are given is calculated by

This equation denotes the probability that the ith voxel belongs to the kth class. The final class of each voxel can be determined by the class, which has the maximum a posteriori probability among classes 1 to K. By using an expectation-maximization (EM) algorithm, from which the maximum likelihood parameters can be obtained, the parameter vector Ψ can be estimated by maximizing the following likelihood function:

At the Eth step, at first, the posterior probability P(Z (i) = k| x i , Ψ) (Eq. 5.5) is calculated with the probability density function f k (x i | θ k ) based on the initially clustered regions. Second, the expectation of a natural logarithm of the likelihood is obtained by using Eq. (5.6). At the Mth step, the parameter vector Ψ is updated based on new clustered regions. This iteration of E- and M-steps is stopped when the change in the logarithm of the likelihood is smaller than a threshold value.
(5.1)
(5.2)
(5.3)
be a class random vector, where is defined as(5.4)
(5.5)
(5.6)
5.2.2 Optimum Contour Selection Method
The OCS method retrospectively determines a global optimum objective contour from multiple active delineations around a tumor. In addition, PET images are employed to determine the initial GTV regions to be used in the OCS method. First, the PET image is registered with the planning CT image through a diagnostic CT image of the PET/CT dataset by using an affine transformation (Jin et al. 2014). Initial GTV regions are obtained by thresholding the PET image at 80 % of the maximum standard uptake value (SUVmax) within a rectangular volume of interest (VOI), which has the same geometric position as the VOI in the planning CT image. Each initial GTV location is corrected in the VOI. Finally, the GTV region is segmented using the OCS method.
The SUV is employed for identification of the initial GTV regions, and is calculated as a ratio of the radioactivity concentration of tissue at a single time point to the injected dose of radioactivity concentration at that time point, divided by the body weight (Boellaard 2009):

where C represents the radioactivity concentration in kBq/ml obtained from the pixel value in the PET image multiplied by a cross calibration factor, D is the injected dose of 18-fluorodeoxyglucose (FDG) administered in MBq (decay corrected), and W is the body weight of the patient in kg.
(5.7)
The final GTVs are segmented by applying the OCS method to the initial regions, which are determined from the PET images. The basic concept of the OCS method is to retrospectively select a global optimum object contour from among multiple active delineations with a level set method around the tumors. In the OCS method, the level set method (LSM) (Sethian 1999) is employed for searching for the optimum object contour in the relationship between the average speed function value on an evolving curve and the evolution time.
An original level set equation of a partial differential equation (Sethian 1999) can be defined as

where ϕ(r(t), t) is the level set function, r(t) is the position vector at time t, and F is the speed function, which depends on circumstances on the evolution curve. The level set function is actually a distance image where the pixel values inside the initial curve are negative Euclidean distance values from each pixel to the closest pixel on the curve, but those outside the curve are positive distance values. The level set equation can be transformed into a Hamilton-Jacobi equation, which is equivalent to the Euler-Lagrange equation, as follows:

where H(F, ϕ(r(t), t), t)= F||∇ϕ(r(t), t)||, which is considered as a Hamiltonian. Solving (integration of a differential equation) a Hamilton-Jacobi equation of a contour involves the prediction of the contour with a minimum energy (possibly, a stable contour) from the analytical mechanics standpoint.
(5.8)
(5.9)
In the first step of the OCS method, the GTV contour and the speed function value obtained by the LSM are recorded at each evolution time from the initial GTV region until the evolution time reaches 10,000 or the evolving curve reaches the edge of the ROI in the planning CT image. The level set function φ(x, y, t) is updated from the initial GTV contour by using the following discrete partial differential equation:

where n is the evolution number, t is the evolution time, Δt is the evolution time interval, and F(x, y, t) is the speed function. The evolution time is the time of the contour deformation in updating the discrete partial differential equation. The zero level set of ϕ(x, y, t), which corresponds to the contour of the segmented region, moves according to the speed function F(x, y, t) in the three-dimensional level set function. The zero level set function, i.e., the evolving curve, moves according to the following speed function F(x, y, t):


where b(x, y) is the function of the edge indicator, G(x, y) is the Gaussian function, I(x, y) is the planning CT image to be processed, * denotes convolution, v is a constant, and κ(x, y, t) is the curvature. The edge indicator function b(x, y) and speed F (x, y, t) would be small around the edge, whereas the functions b(x, y) and F (x, y, t) would be large in relatively homogeneous regions.
(5.10)
(5.11)
(5.12)
In the second step, the GTV contour is determined from the optimum contour derived using the LSM by searching for the minimum point in the relationship between the evolution time and the average speed function value on an evolving curve, based on the steepest descent method (SDM). To avoid local minimum traps, the average speed function is smoothed by a median filter, and the smoothed function is resampled by a larger interval than the original one, before applying the SDM.
Figure 5.2a shows the relationship in the LSM between the evolution time and the average speed function value on an evolving curve. Figure 5.2b illustrates GTV contours, which were multiply delineated by the proposed method on the planning CT image of a lung cancer case. The average speed function  as a function of the evolution time t converges to a global minimum of 4803. Therefore, the optimum contour can be determined by detecting the minimum point in the relationship between the average speed function and the evolution time.
as a function of the evolution time t converges to a global minimum of 4803. Therefore, the optimum contour can be determined by detecting the minimum point in the relationship between the average speed function and the evolution time.

as a function of the evolution time t converges to a global minimum of 4803. Therefore, the optimum contour can be determined by detecting the minimum point in the relationship between the average speed function and the evolution time.Fig. 5.2
Illustrations of (a) the relationship in the level set method between the evolution time and the average speed function on a moving front line and (b) contours on a planning CT image at evolution times
5.2.3 Machine-Learning-Based Delineation
The key idea of the machine-learning-based delineation (MLD) was to feed image features around GTV contours determined based on the knowledge or experiences of radiation oncologists into a machine learning classifier during the training step, after which the classifier produced the “degree of GTV” for each voxel in the testing step (Ikushima et al. 2016). The overall procedure of the MLD framework consists of the following four steps:
- 1.
The PET and diagnostic CT images were aligned with planning CT images based on the centroid of lung regions in two CT images.
- 2.
The morphological and biological image features were derived from planning CT, PET, and diagnostic CT images. The image features are pixels and gradient values of three types of images.
- 3.
The initial GTV regions were obtained using one of machine learning techniques, i.e., a support vector machine (SVM), which learned the image features inside and outside each GTV region determined by radiation oncologists or radiologists.
- 4.
Final GTV regions were determined by thresholding the SVM outputs and/or the OCS method.
The SVM (Vapnik 1999) is one of machine learning techniques that can classify data into several (generally two) categories based on the output of a discriminant function. The SVM constructs a discriminant function in a linearly separable space by applying a nonlinear kernel function to a given training dataset. We consider a training dataset of training data and teacher signals, [x i , ] (x i ∈ R n , i , data number ; n , dimension ; i = 1 , … , l , l , number of data,
] (x i ∈ R n , i , data number ; n , dimension ; i = 1 , … , l , l , number of data,  ), which we would like to classify. The discriminant function
), which we would like to classify. The discriminant function  constructed by the SVM is expressed by (Vapnik 1999)
constructed by the SVM is expressed by (Vapnik 1999)

where x i (i = 1 , … , N , N, number of support vectors) is the support vector, b and α i are parameters that determine the discriminant function, and K(x, x i ) is the nonlinear kernel function, which can map a linearly non-separable dataset to a linearly separable dataset. The output was referred to as “degree of GTV” in this study.
] (x i ∈ R n , i , data number ; n , dimension ; i = 1 , … , l , l , number of data, ), which we would like to classify. The discriminant function constructed by the SVM is expressed by (Vapnik 1999)(5.13)
The training procedure of construction of the SVM is shown as follows:
Step 1: A training dataset of image features and teacher signals [x i , ] is prepared, where x i = (x 1i , x 2i , … , x Fi ) (F, number of image features). In this study, F is 6 or 4, which depends on lung tumor type.
] is prepared, where x i = (x 1i , x 2i , … , x Fi ) (F, number of image features). In this study, F is 6 or 4, which depends on lung tumor type.
Step 2: All parameters of the discriminant function are optimized by repeatedly calculating the parameters using image features of the training dataset based on a quadratic programming approach (Vapnik 1999).
The efficacy of the proposed framework was evaluated in 14 lung cancer cases (solid, 6; ground glass opacity (GGO), 4; mixed GGO, 4) using the three-dimensional Dice similarity coefficient (DSC), which denotes the degree of region similarity between the GTVs contoured by radiation oncologists and those determined using the proposed framework. Figure 5.3 shows the planning CT, PET, and SVM-output images for three types of lung tumors. A tumor of the solid type has a high intensity with SUVmax of 7.75, but the GGO and mixed GGO types of tumors show low intensities with SUVmax of 1.09 and 1.62, respectively. On the other hand, the SVM enhanced not only the solid type of tumor but also the GGO and mixed GGO types of tumors in spite of low SUVmax. The proposed framework including the SVM and OCS method achieved an average DSC of 0.777 for 14 cases, whereas the OCS-based framework produced 0.507. The average DSCs for GGO and mixed GGO were 0.763 and 0.701, respectively, obtained by the proposed framework.

Fig. 5.3
shows the planning CT, PET, and SVM-output images for three types (solid, GGO, mixed GGO) of lung tumors
5.2.4 Multivalued Level Set Method
El Naqa et al. (2007) demonstrated the multimodality segmentation approach for delineating target regions by combining complementary information from different imaging modalities such as PET, CT, and MR systems and thus identifying GTV regions by simultaneously using anatomical and functional information. Their method was based on an active contour model without edges for vector-valued images (such as RGB or multispectral images) (Chan et al. 2000). The advantage of this model is to segment objects with different missing parts in different channels in a mutually complementary manner. El Naqa et al. took advantage of mutually complementary functions of the active contour model for vector-valued images such as medical multimodality images in a same coordinate system.
El Naqa et al. (2007) developed variational methods based on multivalued level set (MVLS) deformable models for simultaneous 2D or 3D segmentation of multimodality images consisting of combinations of coregistered PET, CT, or MR datasets. In their approach, a GTV region in an image I i (x, y) for the ith imaging modality is segmented by minimizing the following energy function E with information of N images I i (x, y) (i = 1 to N ; N, number of imaging modalities):

 Computer-Assisted Treatment Planning Approaches for IMRT
Computer-Assisted Treatment Planning Approaches for IMRT
 Computer-Aided Detection and Differentiation of Breast Cancer on Mammograms
Computer-Aided Detection and Differentiation of Breast Cancer on Mammograms
 Computerized Prediction of Treatment Outcomes and Radiomics Analysis
Computerized Prediction of Treatment Outcomes and Radiomics Analysis
 X-Ray Image-Based Patient Positioning
X-Ray Image-Based Patient Positioning
 Computer-Assisted Treatment Planning Approaches for Carbon-Ion Beam Therapy
Computer-Assisted Treatment Planning Approaches for Carbon-Ion Beam Therapy
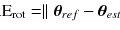 Surface-Imaging-Based Patient Positioning in Radiation Therapy
Surface-Imaging-Based Patient Positioning in Radiation Therapy




Related posts:
Computer-Assisted Treatment Planning Approaches for IMRT
Computer-Aided Detection and Differentiation of Breast Cancer on Mammograms
Computerized Prediction of Treatment Outcomes and Radiomics Analysis
X-Ray Image-Based Patient Positioning
Computer-Assisted Treatment Planning Approaches for Carbon-Ion Beam Therapy
Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
