standardization of terms and concepts, schemas for transfer and sharing of information, representation of knowledge, and the structures for constructing queries and their responses. Benefits of ontologies include enhancing interoperability between information systems; facilitating the transmission, reuse, and sharing of structured content; as well as integrating knowledge and data. There are many ontologies found in the field of medicine and medical imaging for the electronic exchange of clinical health information. SNOMED-CT (Systematized Nomenclature of Medicine—Clinical Terms) is a standardized, multilingual vocabulary of clinical terminology that is used by physicians and other health care providers supported by the National Library of Medicine within the United States Department of Health and Human Services. In the United States, it is designated as the national standard for additional categories of information in the EHR and health information exchange transactions. It allows healthcare providers to use different terms that mean equivalent things when implementing software applications. For instance, myocardial infarction (MI), heart attack, and MI are interpreted as the same issue by a cardiologist, but to software, these are all different. SNOMED-CT enables semantic interoperability and supports the exchange of normalized clinically validated health data between different providers, researchers, and others in the healthcare environment. Resources include subsets to identify the most commonly used medical codes and terms. This can assist in identifying diseases, signs, and symptoms for subsequent classification, as explained in the next paragraph.
and a RadLex Playbook that assigns RPID (RadLex Playbook IDentifier) tags to those terms (RSNA, 2020a). RadLex has been widely adopted in radiology and for use in registries, such as the American College of Radiology (ACR) Dose Index Registry (DIR). By providing standard names and codes for radiologic studies, the playbook facilitates a variety of operational and quality improvement efforts such as workflow optimization, radiation dose tracking, and image exchange. A more widely adopted and broader standard that covers tests and measurements in many medical domains is called LOINC (Logical Observation Identifiers Names and Codes), initiated in 1994 by the Regenstrief Institute, a distinguished medical research organization part of Indiana University. A harmonized effort to unify these ontologies has been established by both sponsors to use LOINC codes as the primary identifiers for radiology procedures (LOINC, 2019). A more comprehensive and widely adopted vocabulary standard will assist in making radiology procedure data more accessible to clinicians when and where they need it.
information systems, and is the foundation of data communication for the World Wide Web, one of many application structures and network services foundational to the Internet. HyperText Markup Language (HTML) is the standard markup language for documents designed to be displayed in a web browser. Uniform Resource Locator (URL), also known as a web address, specifies the syntax and semantics for location and access of resources via the Internet. Network Time Protocol (NTP) is used to synchronize clocks in computer systems so that messages are interpreted in the appropriate time frame. Simple Mail Transfer Protocol (SMTP) and Internet Message Access Protocol (IMAP) are the basis for email transactions on the Internet. Multipurpose Internet Message Extensions (MIME) protocol allows extension of email messages to include non-textual content including medical images. Transport Layer Security (TLS) and its predecessor Secure Sockets Layer (SSL) define cryptographic mechanisms for securing the content of Internet transactions. The Syslog Protocol is used to convey event notification messages for audit trail and logging purposes. Extensible Markup Language (XML) is a free, open standard for encoding structured data and serializing it for communication between systems and is the method of choice for most new standards development for distributed systems.
(DICOM, 2020). Understanding how these Parts relate to one another is key to navigating the DICOM Standard, as it now constitutes many thousands of pages. (For example, one may refer to a “Part 10 file” as Part 10 defines DICOM file formats.) DICOM is recognized by the International Organization for Standardization as the ISO 10252 standard. DICOM is an open, public standard, and information for developing DICOM-based software applications is defined and regulated by public committees and is now, practically speaking, universal for image exchange for medical imaging modalities. Ever evolving, the standard is maintained in accordance with the procedures of the DICOM Standards Committee through working groups (WGs), standard development processes, public comment, and WG approvals. Proposals for enhancements or corrections (CPs) may be submitted to the Secretariat. Supplements and corrections to the Standard are balloted and approved several times a year. When approved as final text, the change is official and goes into effect immediately. Vendors creating devices or software claiming to support the DICOM standard are required to conform to strict and detailed protocol definitions and must provide documentation of the specific DICOM services and data types supported in a DICOM Conformance Statement as defined by Part 2 of the Standard. DICOM is critical to interoperability and communication of medical imaging and associated data between medical imaging systems and imaging databases. Essentials of DICOM use are covered in Section 5.4.
TABLE 5-1 PARTS OF THE DICOM STANDARDa | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
provided and in which integration profiles they participate. Purchasers of medical imaging equipment can use conformance to the IHE technical framework as a contractual obligation and as an effective shorthand in a request for purchase document that avoids the complexities of specifying standards and methods to achieve a given interoperability. A major benefit of the IHE integration profiles is that a single integration profile can require conformance with DICOM, HL7, and other standards. A commitment by a vendor to support that integration profile will commit the vendor to conforming to the various standards included in that single integration profile. Verification of successful interoperability requires quality control testing, as described in Section 5.3.9—PACS Quality Control.
as they are on the Internet. Simple programming tools or even no programming at all can be used for data access using the REST model. When APIs need to communicate between different nodes on a network, a mechanism called a Remote Procedure Call (RPC) can be employed, as well. Modern Operating Systems provide a rich set of remotely accessible system services. An extension to provide security and fully distributed software components is part of a broader Service Oriented Architecture (SOA). SOA refers to architectures designed with a focus on services. Begun in the 1990s, the classic approach of SOA architectures was based upon complex services to build complex systems. SOA has evolved to encompass microservices, which represent a more recent subset by implementing applications as a set of simple independently deployable services using modern JavaScript. Web services and RESTful interfaces are also under the umbrella of SOA.
multiple interfaces to facilitate redundancy and throughput management. A switching device connecting two or more networks may have an address on each network.
device. As the information is passed up the layer stack, each layer removes the information appended by the corresponding layer on the sending computer until the information sent by the application on the sending device is delivered to the intended application on the receiving device.
 ▪ FIGURE 5-1 International Standards Organization (ISO) Open Systems Interconnect (OSI) 7-layer network model is a conceptual framework used to describe the functions of a networking system. It characterizes computing functions to support interoperability between different products and software and defines 7 layers of network architecture. This is foundational to understanding concepts such as Layer 3 switching (discussed below). |
 ▪ FIGURE 5-2 The OSI 7-layer framework is used to model the interconnection of medical imaging equipment. DICOM uses the OSI upper layer service to separate the exchange of DICOM messages at the Application Layer from the communication support provided by the lower layers. The DICOM upper layer augments TCP/IP and combines the upper layer protocols into a simple to implement single protocol on general networks. This is an essential property of the modern Standard—avoiding proprietary network architectures (which were once common). |
 ▪ FIGURE 5-3 A. Wide area networks are commonly formed by linking together two or more local area networks (LANs) using routers and links. Routers connect and relay packets to intended destinations. Most often, the public Internet with a virtual private network is used, in lieu of older leased T1 and T3 links between LANs. B. The public internet is leveraged to allow clients to interact with servers through a node to node private and secure channel connection. This is achieved as part of carrier-provided VPNs as shown on the lower half of the figure, using “edge devices” to provide secure connections to each local area network and ensuring quality of service using multiprotocol label switching. |
 ▪ FIGURE 5-4 Internet Protocol addresses. Top: IP version 4, shown in “Dot-decimal notation” as four components—the first two represent the network routing prefix, the third the subnet, and the fourth the specific node connection. Each is shown as the binary equivalent requiring 8 bits, for a total of 32 bits or 4 bytes to represent the specific address. IPv4 can address 232 unique locations. Bottom: IP version 6, shown in colon hexadecimal notation as 8 hexadecimal components—the leading 4 components are currently used, each representing 16 bits of unique address locations. The latter 4 components are currently nulled for future use. In all, IP v6 can address 2128 unique locations. |
established in a “virtual machine” environment, where the virtual machine (VM) is based on a computer architecture to provide the functionality and emulation of a physical computer in a centralized location. The implementation may involve specialized hardware, software, or a combination. VM instances can allow multiple OSs such as Windows and Linux; provide multiple CPUs to a specific software instance; allocate storage space; and meet unique needs as necessary in an enterprise environment. This provides flexibility, efficiency, and ability to reallocate and expand/shrink resources as necessary to meet the needs of the informatics computing infrastructure. A cloud server is a virtual server running in a cloud computing environment that is hosted and delivered on a cloud computing platform via the Internet and can be accessed remotely. Configuration of such a server for a PACS server-side rendering environment requires several component servers to handle tasks within the image database such as: data extraction, DICOM conversion, image rendering, storage, and load balancing. A computer on a network that makes use of a server is called a client and is typically a workstation.
Services (AWS) Glacier can cost as little as $5/TB/yr at scale for large volumes). Some disadvantages of cloud computing and services include the following: (1) a dependence on an Internet connection with upload and download speed and latency issues; (2) hard drives and physical storage devices are often still needed for many applications requiring very high-performance access; (3) end-user customer support is often lacking; (5) after migrating data, concern about privacy and who owns the information could be a major issue for medically sensitive data.
archive to store images, display workstations to permit physicians to view the images, and a computer network to transfer images and related information between the imaging devices and the archive and between the archive and the display workstations. A database program tracks the locations of images and related information in the archive and software permits the selection and manipulation of images for interpretation by radiologists and consultation by referring physicians. PACS can replicate images at multiple display workstations simultaneously and be a repository for several years’ images. For efficiency of workflow and avoidance of errors, the PACS exchanges information with other information systems, such as the EHR, RIS, and other information systems on the hospital, clinic, or teleradiology network. A web server is typically part of the PACS to provide images to referring clinicians within the enterprise network. A schematic of a PACS with sub-components and simple connectivity is illustrated in Figure 5-5.
physicians. The goal is to store all images in a medical center or healthcare system on PACS, with images available to interpreting and referring clinicians through the EHR or thin-client workstations within the enterprise, with the PACS receiving requests for studies from the RIS, and with the PACS providing information to the RIS on the status of studies, and images available on the EHR. Another goal, far from being achieved, is to make medical images and related reports available regionally and nationwide, regardless of where they were acquired.
 ▪ FIGURE 5-5 Modern PACS infrastructure. The PACS is interconnected to the imaging modalities and information systems including the RIS and the EHR. The RIS provides the patient database for scheduling and reporting of image examinations through HL7 transactions and provides modality worklists (MWLs) with patient demographic information to the modalities, allowing technologists to select patient-specific scheduled studies to ensure accuracy. After a study is performed, image information is sent to the PACS in DICOM format and reconciled with the exam-specific information (accession number). Radiologist reporting is performed at the primary diagnostic workstations and transmitted to the RIS via HL7 transactions. An emergency backup server ensures business continuity (orange line directly connecting the modalities) in the event of unscheduled PACS downtime. For referring physicians and remote reading radiologists (teleradiology applications) a webserver is connected to the Internet—access is protected by a Virtual Private Network (VPN) to obtain images and reports. Users within the medical enterprise have protected access through a LAN. Also depicted are an “offsite” backup archive for disaster recovery and real-time customer care monitoring to provide around the clock support. A mirror archive provides on-site backup within the enterprise firewall with immediate availability in case of failure of the primary archive. |
 ▪ FIGURE 5-6 Mini PACS provide modalityspecific capabilities for handling images in ways that are not available in a generalized enterprise PACS. Established mini PACS include Mammography with navigation enhancements through a proprietary electronic panel and robust hanging protocols; Ultrasound for handling video sequences more efficiently and facilitating structured reports; Nuclear Medicine for improving display of smaller images with unique contrast/brightness adjustments, and support of quantitative evaluations of uptake and physiological rate constants. |
 ▪ FIGURE 5-7 Interpretation workstation containing two 1.5k by 2k pixel (3 megapixel) portrait-format color displays for high resolution and high luminance image interpretation, flanked by two 1.9k by 1k (2 MP) color “navigation” displays (left and right) for PACS access, patient worklist, timeline, and thumbnail image displays;, digital voice dictation reporting, and EMR and RIS information access. The keyboard, mouse, and image navigation and voice dictation device assist Ramit Lamba, M.D., in his interpretation duties. |
However, with close inspection, a significant amount of image information can be lost (Fig. 5-8). Currently, there is controversy on how much compression can be tolerated. Research shows that the amount of compression is strongly dependent upon the type of examination, the compression algorithm used, and the way that the image is displayed. In some cases, images that are irreversibly compressed and subsequently decompressed are preferred by radiologists over the original images, due to some reduction of image noise with the compression algorithms. Legal considerations also affect decisions on the use of irreversible compression in medical imaging. Diagnostically acceptable irreversible compression refers to compression that does not affect a particular diagnostic task and may be used under the direction of a qualified physician. Practically speaking, this means that any artifacts generated by the compression scheme should not be perceptible by the viewer or are at such a low level that they do not interfere with interpretation. The US Food and Drug Administration (FDA) requires that an irreversible compressed image, when displayed, must be labeled with a message stating the approximate compression ratio and/or quality factor. In addition, the type of compression scheme (JPEG, JPEG-2000) should also be indicated.
TABLE 5-2 TYPICAL RADIOLOGIC IMAGE FORMATS AND STORAGE REQUIREMENTS PER STUDY | ||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||
mammograms to meet the requirement for retention of original mammograms. The reader should refer to current guidance from the FDA on this topic (FDA, 2020).
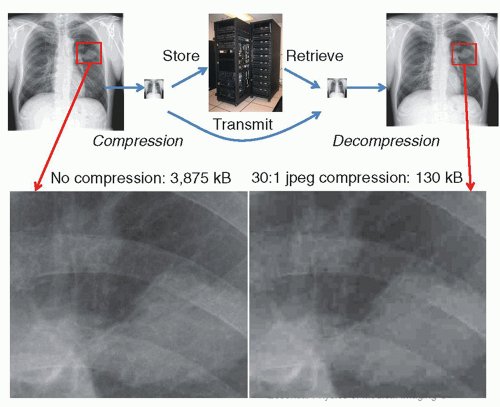 ▪ FIGURE 5-8 Image compression reduces the number of bytes in an image to reduce image storage space and image transmission times. At a display workstation, an image retrieved from the archive over the network requires image decompression, which restores the images to full physical size (number of pixels) and number of bytes. Shown above is a chest image with lossless compression (left), and 30:1 jpeg lossy compression (right). Although the minified images (above) look similar, the magnified views (below) illustrate loss of image fidelity and non-diagnostic image quality with too much lossy compression. |
studies in for storage and sends copies of the studies received from imaging devices to the storage devices, including backup storage. The transfers between imaging devices and the PACS must conform to the DICOM standard. The archive management software must also obtain studies from the storage devices and send either the studies or selected images from them to workstations requesting studies or images for display. In PACS with hierarchical storage, the archive management software transfers studies between the various levels of archival storage, based upon factors such as the recentness of the study and, when a new study is ordered, prefetches relevant older studies from near-line storage to online storage to reduce the time required for display.
libraries. On-line storage describes the fraction of studies with immediate and rapid access for viewing. Near-line storage refers to storage at remote disk farms or automated libraries of magnetic tape, from which studies may be retrieved albeit less rapidly. Off-line storage refers to storage not directly accessible (requiring some human intervention to be made available). With the lowered cost of storage media, off-line mechanisms are generally no longer used as primary storage tiers, but often still employed as disaster recovery mechanisms. With magnetic tape capacities already at 30 terabytes (TB) (LTO-8 compressed, at around a $100 per cartridge) and planned to exceed 100 TB (LTO-10 compressed), many sites utilize off-site magnetic tape storage for cost-effective disaster recovery. When hierarchical storage is used, the system must automatically copy (“prefetch”) relevant older studies from near-line to on-line storage to be available without delay for comparison when new studies are viewed. An alternative to hierarchical storage is to store all images on arrays of magnetic or solid-state disk drives. As these become full, more disk arrays are added to the system, which has become feasible because of the increasing capacities of disk drives and the decreasing cost per unit storage capacity. This method is referred to as “everything online” storage.
consistency and presentation of displayed images. A description and complete listing of the DICOM standard is available (DICOM, 2020).
service operations are defined: Service Class User (SCU)—invokes operations, and Service Class Provider (SCP)—performs operations. Table 5-3 lists a subset of common DICOM vocabulary terms and acronyms that are widely used by PACS administrators.
 ▪ FIGURE 5-9 A. DICOM information model—Service/Object relationship. The Service Class specification (top rectangle) defines the services—operations such as moving, storing, finding, or printing that can be performed on data objects that DICOM can manage. The service group is comprised of DICOM Message Service Element (DIMSE) services such as “C-move,” “C-store,” “C-find,” etc., as described in Part 4 of the DICOM standard. Data objects have Information Object Definitions (IODs) with attributes defining the object (e.g., a CT series containing images). A specific combination of a Service and an Object is termed a Service-Object-Pair (SOP), middle rectangle, which constitutes the basic unit of DICOM operability. Model shown above is adapted from the DICOM standard in Part 3.3. (DICOM PS3.3-2003, by permission). B. An example might be a SOP that combines “C-Move” service with “CT” IOD. In a Conformance Statement, this might be represented as shown, attesting that the implementation can both send and receive CT images. The “UID” is a Unique Identifier associated with this particular SOP class, describing a DICOM transfer syntax.
Related posts:Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
 Get Clinical Tree app for offline access
Get Clinical Tree app for offline access

|