Fig. 2.1
(a) Electron micrograph of an animal cell showing major organelles within the cell. (b) Schematic drawing of the cell clearly depicting the intricate network of interconnecting intracellular membrane structures such as endoplasmic reticulum (rough and smooth), mitochondria, lysosomes, and nucleus (Reprinted with permission from Raven and Johnson [3])
The entire human body contains about 100 trillion cells that are generated by repeated division from a single precursor cell. Therefore, they constitute clones. As proliferation continues, some of the cells become differentiated from others, adopting a different structure, a different chemistry, and a different function. In the human body, more than 200 distinct cell types are assembled into a variety of types of tissues such as epithelia, connective tissue, muscle, and nervous tissue. Each organ in the body is an aggregate of many different cells held together by intercellular supporting structures. Although the many cells of the body often differ markedly from each other, all of them have certain basic characteristics that are alike. Each cell is a complex structure whose purpose is to maintain an intracellular environment favorable for complex metabolic reactions, to reproduce itself when necessary, and to protect itself from the hazards of its surrounding environment.
2.2 Cell Structure and Function
The different substances that make up the cell are collectively called protoplasm, which is composed mainly of water, electrolytes, proteins, lipids, and carbohydrates. The two major parts of the cell are the nucleus and cytoplasm. The nucleus is separated from the cytoplasm by a nuclear membrane, while the cytoplasm is separated from the extracellular fluid by a cell membrane. The major organelles in the cell are of three general kinds: organelles derived from membranes, organelles involved in gene expression, and organelles involved in energy production [5]. The important subcellular structures of the cell and their functions are summarized in Table 2.1.
Cell structure | Major functions |
|---|---|
Plasma membrane | Cell morphology and movement, transport of ions and molecules, cell-to-cell recognition, cell surface receptors |
Endoplasmic reticulum | Formation of compartments and vesicles, membrane synthesis, synthesis of proteins and lipids, detoxification reactions |
Lysosomes | Digestion of worn-out mitochondria and cell debris, hydrolysis of proteins, carbohydrates, lipids, nucleic acids |
Peroxisomes | Oxidative reactions involving molecular oxygen, utilization of hydrogen peroxide (H2O2) |
Golgi complex | Modification and sorting of proteins for incorporation into organelles and for export; formation of secretory vesicles |
Microbodies | Isolation of particular chemical activities from rest of the cell body |
Mitochondria | Cellular respiration; oxidation of carbohydrates, proteins and lipids; urea and heme synthesis |
Nucleus | DNA synthesis and repair; RNA synthesis and control; center of the cell; directs protein synthesis and reproduction |
Chromosomes | Contain hereditary information in the form of genes |
Nucleolus | RNA processing, assembles ribosomes |
Ribosomes | Sites of protein synthesis in cytoplasm |
Cytoplasm | Metabolism of carbohydrates, lipids, amino acids, nucleotides |
Cytoskeleton | Structural support, cell movement, cell morphology |
2.2.1 The Plasma Membrane
2.2.1.1 Plasma Membrane Structure
The plasma membrane encloses the cell, defines its boundaries, and maintains the essential difference between the cytosol and the extracellular environment. The cell membrane is an organized sea of lipid in a fluid state, a nonaqueous dynamic compartment of cells.
The cell membranes are assembled from four major components: a lipid bilayer, membrane proteins, sugar residues, and a network of supporting fibers.
The basic structure of a cell membrane is a lipid bilayer of phospholipid molecules. The fatty acid portions of the molecules are hydrophobic and occupy the center of the membrane, while the hydrophilic phosphate portions form the two surfaces in contact with intra- and extracellular fluid (Fig. 2.2). This lipid bilayer of 7–10 nm thickness is a major barrier, impermeable to water-soluble molecules such as ions, glucose, and urea. The three major classes of membrane lipid molecules are phospholipids (phosphatidylcholine, phosphatidylserine, phosphatidylethanolamine, sphingomyelin,), cholesterol, and glycolipids. The lipid composition of different biological membranes varies depending upon the specific function of the cell or cell membrane, as summarized in Table 2.2.
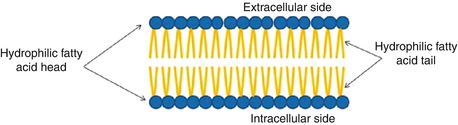
Fig. 2.2
Cell membrane composition
Table 2.2
Specific functions of the cell membrane components
Component | Composition | Function | How it works | Example |
|---|---|---|---|---|
Lipid | Phospholipid bilayer | Permeability barrier | Polar molecules excluded | Glucose |
Transmembrane protein | Channels | Passive transport | Creates a tunnel | Na+, K+ ions |
Carrier or transporters | Facilitates diffusion | Carrier “flip-flops” | Glucose transport | |
Receptors | Transmits information into cell | Following receptor binding, inducing activity in the cell | Peptide hormones, neurotransmitters | |
Cell surface markers | Glycoprotein (GP) | “Self”-recognition | Shape of GP is characteristic of a cell or tissue | Major histocompatibility complex recognized by immune system |
Glycolipid | Tissue recognition | Shape of carbohydrate chain is characteristic of tissue | A, B, O blood group markers | |
Interior protein network | Clathrins | Anchor certain proteins to specific sites | Form network above membrane to which proteins are anchored | Localization of LDL receptor within coated pits |
Spectrin | Determines cell shape | Forms supporting scaffold by binding to both membrane and cytoskeleton | Red blood cell |
The proteins of the membrane are responsible for most membrane functions such as transport, cell identity, and cell adhesion and constitute transport channels, transporters, specific receptors, and enzymes. The membrane proteins can be associated with the lipid bilayer in various ways depending on the function of the protein. The polypeptide chain may extend across the lipid bilayer (transmembrane proteins) or may simply be attached to one or the other side of the membrane.
The cell surface often has a loose carbohydrate coat called glycocalyx. The sugar residues generally occur in combination with proteins (glycoproteins, proteoglycans) or lipids (glycolipids). The oligosaccharide side chains are generally negatively charged and provide the cell with an overall negative surface charge. While some carbohydrates act as receptors for binding hormones such as insulin, others may be involved in immune reactions and cell–cell adhesion events.
2.2.1.2 Plasma Membrane Function
The main function of the cell membrane is to protect the cytoplasm and the component of the cell from the external media. It also helps the exchange of different substance to the cell. It can help the identification of the cell and its communication with other cells.
1.
Selective permeability.
The cell membrane prevents the intrusion of harmful substances. The selective permeability of membrane is essential in maintaining the functional steady state required for cell survival. This mechanism maintains optimal intracellular concentrations of ions, water, enzymes, and substrates. Some molecules can be allowed to cross the cell membrane through different mechanisms.
(a)
Passive diffusion. The substances can cross the membrane in either directions according to the concentration gradient with no need for energy as water.
(b)
Facilitated diffusion. The substances can cross the membrane in unidirectional way by the help of a membrane component with no need for energy as glucose.
(c)
Active transport. The substances can cross the membrane against a concentration gradient. This requires energy, usually adenosine triphosphate (ATP).
2.
Signal transduction.
Receptors for many substances, such as neurotransmitters, protein hormones are located at the cell surface. Signal transmission depends on the receptor class involved. These receptors are:
(a)
Ion channel-linked receptors
(b)
Enzyme-linked receptors
(c)
G-protein-linked receptors
(d)
Steroid hormone receptor family
3.
Phagocytosis: Endocytosis and pinocytosis
4.
Exocytosis (extrusion of material from a cell involves membrane vesicles)
5.
Compartmentalization which means the cell membrane keeps an individual cell separate from other cells and its environment. It may also be used inside the cell to create compartments, such as with organelles allowing each organelle to carry out its own function without mixing its contents with the rest of the cell.
6.
Spatial-temporal organization of metabolic processes
It has been increasingly apparent that microcompartment formation via the interactions of enzyme groups with intracellular membranes, the cytoskeleton, or other proteins is an important regulatory mechanism. The membranes of these intracellular microvesicles play an important role in collecting chains of enzymes promoting metabolite channeling within the metabolic microcompartment, which can help control reaction specificity as well as dictate flux routes through the network, signaling, and ensure the interactions on their surface.
7.
Storage, transport, and secretion
The water-soluble molecules, such as ions, glucose, and urea, only cross the membrane through transmembrane channels, carriers, and pumps, which regulate the supply of the cell with nutrients, control internal ion concentrations, and establish a transmembrane electrical potential. Transmembrane receptors bind extracellular signaling molecules, such as hormones and growth factors, and transduce their presence into chemical or electrical signals that influence the activities of the cell. Genetic defects in signaling proteins can lead to signals for growth in the absence of appropriate extracellular stimuli and cause some human cancers.
Adhesive glycoproteins of the plasma membrane allow cells to bind specifically to each other or to the extracellular matrix. These selective interactions allow cells to form multicellular structures, like epithelia. Similar interactions allow white blood cells to bind bacteria, so that they can be ingested and digested in lysosomes.
Although lipid bilayers provide a barrier to diffusion of ions and polar molecules larger than about 150 D, protein pores provide selective passages for these larger molecules across membranes. These proteins allow cells to control solute traffic across membranes, an essential feature of many physiological processes. Integral proteins that control membrane permeability fall into three broad classes: pumps, carriers, and channels each with distinct properties.
Pumps are enzymes using energy from adenosine triphosphate (ATP), light, or other sources of energy to move ions, mainly cations and other solutes across membranes at relatively modest rates, up to concentration gradients as great as 100,000-fold.
Carriers are enzyme-like proteins that provide passive pathways for solutes to move across membranes from a region of higher concentration to lower concentration. Carriers use ion gradients as a source of energy. Some carriers use translocation of an ion down its concentration gradient to drive another ion or solute up a concentration gradient. Carrier can provide also a pathway for substrates to move up concentration gradients, provided that their passage through the carrier is coupled to the transport of another substrate down its electrochemical gradient. Glucose provides good examples of both downhill and uphill movement through different carriers. The reactions mediated by carriers are reversible, so that substrates can move in either direction across the membrane, depending on the polarity of the driving forces. Carriers and pumps are found in all cell membranes for exchanging molecules for metabolism, storage, or extrude wastes. Table 2.3 summarizes the different functions of proteins embedded in the cell membranes.
Table 2.3
Different functions of proteins embedded in membrane serve
Protein
Function
Channel proteins
Form small openings for molecules to diffuse through
Carrier proteins
Binding site on protein surface “grabs” certain molecules and pulls them into the cell
Receptor proteins
Molecular triggers that set off cell responses (such as release of hormones or opening of channel proteins)
Cell recognition proteins
ID tags, to identify cells to the body’s immune system
Enzymatic Proteins
Carry out metabolic reactions
Channels are ion-specific pores that open and close transiently in a regulated manner. When a channel is open, ions pass quickly across the membrane through the channel, driven by electrical and concentration gradients. The movement of ions through open channels controls the potential across membranes and produces rapid electrical signals in excitable membranes of nerves, muscle, and other cells. Channels can do three essential functions. First, certain channels cooperate with pumps and carriers to transport water and ions across cell membranes, to regulate cellular volume and also for secretion and absorption of fluid, as in salivary glands and kidney. Second, ion channels regulate the electrical potential across membranes. The sign and magnitude of the membrane potential depend on ion gradients created by pumps and carriers and the relative permeabilities of various channels. Open channels allow unpaired ions to diffuse down concentration gradients across a membrane producing a membrane potential. Coordinated opening and closing of channels change the membrane potential and produce an electrical signal that spreads rapidly over the surface of a cell. Nerve and muscle cells use these action potentials for high-speed communication. Third, other channels permit calcium ion from outside the cell or from the endoplasmic reticulum to enter the cytoplasm where it triggers a variety of processes, such as muscle contraction and secretion.
The following are examples of membrane types:
Blood–brain barrier. The membranes between the blood and brain have effectively no pores. This will prevent many polar materials (often toxic materials) from entering the brain. However, smaller lipid materials or lipid soluble materials, such as diethyl ether and halothane, can easily enter the brain. These compounds are used as general anesthetics.
Renal tubules. In the kidney there are a number of regions important for drug elimination. In the tubules drugs may be reabsorbed. However, because the membranes are relatively nonporous, only lipid compounds or non-ionized species (dependent of pH and pKa) are reabsorbed.
Blood capillaries and renal glomerular membranes. These membranes are quite porous allowing nonpolar and polar molecules (up to a fairly large size, just below that of albumin, M.Wt 69,000) to pass through. This is especially useful in the kidney since it allows excretion of polar (drug and waste compounds) substances.
2.2.2 Cytoplasm and Its Organelles
The cytoplasm is an aqueous solution (cytosol) that fills the cytoplasmic matrix, the space between the nuclear envelope and the cell membrane. The cytosol contains many dissolved proteins, electrolytes, glucose, certain lipid compounds, and thousands of enzymes. In addition, glycogen granules, neutral fat globules, ribosomes, and secretory granules are dispersed throughout the cytosol. Many chemical reactions of metabolism occur in the cytosol, where substrates and cofactors interact with various enzymes. The various organelles suspended in the cytosol are either surrounded by membranes (nucleus, mitochondria, and lysosomes) or derived from membranous structures (endoplasmic reticulum, Golgi apparatus). Within the cell, these membranes interact as an endomembrane system by being in contact with one another, giving rise to one another, or passing tiny membrane-bound sacs called vesicles to one another. All biological membranes are phospholipid bilayers with embedded proteins. The chemical composition of lipids and proteins in membranes varies depending upon a specific function of an organelle or a specific cell in a tissue or an organ.
2.2.2.1 The Endoplasmic Reticulum
The cytoplasm contains an interconnecting network of tubular and flat membranous vesicular structures called the endoplasmic reticulum (ER). Like the cell membrane, the walls of the ER are composed of a lipid bilayer containing many proteins and enzymes. The regions of ER rich in ribosomes are termed rough or granular ER, while the regions of ER with relatively few ribosomes are called smooth or agranular ER. Ribosomes are large molecular aggregates of protein and ribonucleic acid (RNA) that are involved in the manufacture of various proteins by translating the messenger RNA (mRNA) copies of genes. Subsequently, the newly synthesized proteins (hormones and enzymes) are incorporated into other organelles (Golgi complex, lysosomes) or transported or exported to other target areas outside the cell. Enzymes anchored within the smooth ER catalyze the synthesis of a variety of lipids and carbohydrates. Many of these enzyme systems are involved in the biosynthesis of steroid hormones and in detoxification of a variety of substances.
2.2.2.2 The Golgi Complex
The Golgi complex or apparatus is a network of flattened smooth membranes and vesicles. It is the delivery system of the cell. It collects, packages, modifies, and distributes molecules within the cell or secretes the molecules to the external environment. Within the Golgi bodies, the proteins and lipids synthesized by the ER are converted to glycoproteins and glycolipids and collected in membranous folds or vesicles called cisternae, which subsequently move to various locations within the cell. In a highly secretory cell, the vesicles diffuse to the cell membrane and then fuse with it and empty their contents to the exterior by a mechanism called exocytosis. The Golgi apparatus is also involved in the formation of intracellular organelles such as lysosomes and peroxisomes.
2.2.2.3 Lysosomes
Lysosomes are small vesicles (0.2–0.5 μm) formed by the Golgi complex and have a single limiting membrane. Lysosomes maintain an acidic matrix (pH 5 and below) and contain a group of glycoprotein digestive enzymes (hydrolases) that catalyze the rapid breakdown of proteins, nucleic acids, lipids, and carbohydrates into small basic building molecules. The enzyme content within lysosomes varies and depends on the specific needs of an individual tissue. Through a process of endocytosis, a number of cells remove either extracellular particles (phagocytosis) such as microorganisms or engulf extracellular fluid with the unwanted substances (pinocytosis). Subsequently, the lysosomes fuse with the endocytotic vesicles and form secondary lysosomes or digestive vacuoles. Products of lysosomal digestion are either reutilized by the cell or removed from the cell by exocytosis. Throughout the life of a cell, lysosomes break down the organelles and recycle their component proteins and other molecules at a fairly constant rate. However, in metabolically inactive cells, the hydrolases digest the lysosomal membrane and release the enzymes, resulting in the digestion of the entire cell. By contrast, metabolically inactive bacteria do not die, since they do not possess lysosomes. Programmed cell death (apoptosis) or selective cell death is one of the principal mechanisms involved in the removal of unwanted cells and tissues in the body. In this process, however, lysosomes release the hydrolytic enzymes into the cytoplasm to digest the entire cell.
2.2.2.4 Peroxisomes
Peroxisomes are small membrane-bound vesicles or microbodies (0.2–0.5 μm), derived from the ER or Golgi apparatus. Many of the enzymes within the peroxisomes are oxidative enzymes that generate or utilize hydrogen peroxide (H2O2). Some enzymes produce hydrogen peroxide by oxidizing D-amino acids, uric acid, and various 2-hydroxy acids using molecular oxygen, while certain enzymes such as catalase convert hydrogen peroxide to water and oxygen. Peroxisomes are also involved in the oxidative metabolism of long-chain fatty acids, and different tissues contain different complements of enzymes depending on cellular conditions.
2.2.2.5 Mitochondria
Mitochondria are tubular or sausage-shaped organelles (1–3 μm). They are composed mainly of two lipid bilayer–protein membranes. The outer membrane is smooth and derived from the ER. The inner membrane contains many infoldings or shelves called cristae which partition the mitochondrion into an inner matrix called mitosol and an outer compartment. The outer membrane is relatively permeable, but the inner membrane is highly selective and contains different transporters. The inner membrane contains various proteins and enzymes necessary for oxidative metabolism, while the matrix contains dissolved enzymes necessary to extract energy from nutrients. Mitochondria contain a specific DNA. However, the genes that encode the enzymes for oxidative phosphorylation and mitochondrial division have been transferred to the chromosomes in the nucleus. The cell does not produce brand new mitochondria each time the cell divides; instead, mitochondria are self-replicative: the mitochondrion divides into two and these are partitioned between the new cells. The mitochondrial reproduction, however, is not autonomous but is controlled by the cellular genome. The total number of mitochondria per cell depends on the specific energy requirements of the cell and may vary from less than a hundred to up to several thousands. Mitochondria are called the “powerhouses” of the cell. The cell derives energy from glucose, amino acids, and fatty acids. In a process called glycolysis, glucose is converted to pyruvic acid, which subsequently enters mitochondria where it begins a sequence of chemical reactions called the citric acid or Krebs cycle. Various enzymes present in the inner membrane oxidize the pyruvic acid to carbon dioxide and water. The oxidative metabolism of the glucose molecule generates 36 molecules of ATP. The amino acids and fatty acids are converted to acetyl coenzyme A (in the cytoplasm) which also enters the citric acid cycle and gets oxidized with the generation of ATP molecules.
2.2.2.6 Ribosomes
Ribosomes are large complexes of RNA and protein molecules and are normally attached to the outer surfaces of the ER. The major function of ribosomes is to synthesize proteins. Each ribosome is composed of one large and one small subunit with a mass of several million daltons.
2.2.3 Cytoskeleton
The cytoplasm contains a network of protein fibers, called the cytoskeleton, that provides a shape to the cell and anchors various organelles suspended in the cytosol. The fibers of the cytoskeleton are made up of different proteins of different sizes and shapes such as actin (actin filaments), tubulin (microtubules), and vimentin and keratin (intermediate filaments). The exact composition of the cytoskeleton varies depending upon the cell type and function. Centrioles are small organelles that occur in pairs within the cytoplasm, usually located near the nuclear envelope, and are involved in the organization of microtubules. Each centriole is composed of nine triplets of microtubules (long hollow cylinders about 25 nm long) and plays a major role in cell division.
2.2.4 Nucleus
The nucleus is the largest membrane-bound organelle in the cell, occupying about 10 % of the total cell volume. The nucleus is composed of a double membrane, called the nuclear envelope, that encloses the fluid-filled interior, called nucleoplasm. The outer membrane is contiguous with the ER. The nuclear envelope has numerous nuclear pores about 90 Å in diameter and 50–80 nm apart, permitting certain molecules to pass into and out of the nucleus.
The primary functions of the nucleus are cell division and the control of phenotypic expression of genetic information that directs all of the activities of a living cell. The cellular deoxyribonucleic acid (DNA) is located in the nucleus as a DNA–histone protein complex known as chromatin that is organized into chromosomes. The total genetic information stored in the chromosomes of an organism is said to constitute its genome. The human genome consists of 24 chromosomes (22 different chromosomes and two different sex chromosomes) and contains about 3 × 109 nucleotide pairs. The smallest unit of DNA that encodes a protein product is called a gene and consists of an ordered sequence of nucleotides located in a particular position on a particular chromosome. There are approximately 100,000 genes per human genome, and only a small fraction (15 %) of the genome is actively expressed in any specific cell type. The genetic information is transcribed into ribonucleic acid (RNA), which subsequently is translated into a specific protein on the ribosome. The nucleus contains a subcompartment called the nucleolus that contains large amounts of RNA and protein. The main function of the nucleolus is to form granular subunits of ribosomes, which are transported into the cytoplasm where they play an essential role in the formation of cellular proteins.
2.3 DNA and Gene Expression
2.3.1 DNA: The Genetic Material
The ability of cells to maintain a high degree of order depends on the hereditary or genetic information that is stored in the genetic material, the DNA. Within the nucleus of all mammalian cells a full complement of genetic information is stored, and the entire DNA is packaged into 23 pairs of chromosomes. A chromosome is formed from a single, enormously long DNA molecule that consists of many small subsets called genes; these represent a specific combination of DNA sequence designed for a specific cellular function. The three most important events in the existence of a DNA molecule are replication, repair, and expression.
The chromosomes can undergo self-replication, permitting the DNA to make copies of itself as the cell divides and transfers the DNA (23 pairs of chromosomes) to daughter cells, which can thus inherit every property and characteristic of the original cell. There are approximately 100,000 genes per human genome, and genes control every aspect of cellular function, primarily through protein synthesis. The sequence of amino acids in a particular protein or enzyme is encoded in a specific gene. Most chromosomal DNA, however, does not code for proteins or RNAs. The central dogma of molecular biology is that the overall process of information transfer in the cell involves transcription of DNA into RNA molecules, which subsequently generate specific proteins on ribosomes by a process known as translation.
A major characteristic of DNA is its ability to encode an enormous quantity of biological information. Only a few picograms (10−12 g) of DNA are sufficient to direct the synthesis of as many as 100,000 distinct proteins within a cell. Such a supreme coding effectiveness of DNA is due to its unique chemical structure.
2.3.1.1 DNA Structure
DNA was first discovered in 1869 by a chemist, Friedrich Miescher, who extracted a white substance from the cell nuclei of human pus and called it “nuclein.” Since nuclein was slightly acidic, it was known as nucleic acid. In the 1920s, a biochemist, P.A. Levine, identified two sorts of nucleic acid: DNA and RNA. Levine also concluded that the DNA molecule is a polynucleotide (Fig. 2.3a), formed by the polymerization of nucleotides. Each nucleotide subunit of DNA molecule is composed of three basic elements: a phosphate group, a five-carbon sugar (deoxyribose), and one of the four types of nitrogen-containing organic bases. Two of the bases, thymine and cytosine, are called pyrimidines, while the other two, adenine and guanine, are called purines. Their first letters commonly represent the four bases: T, C and A, G.
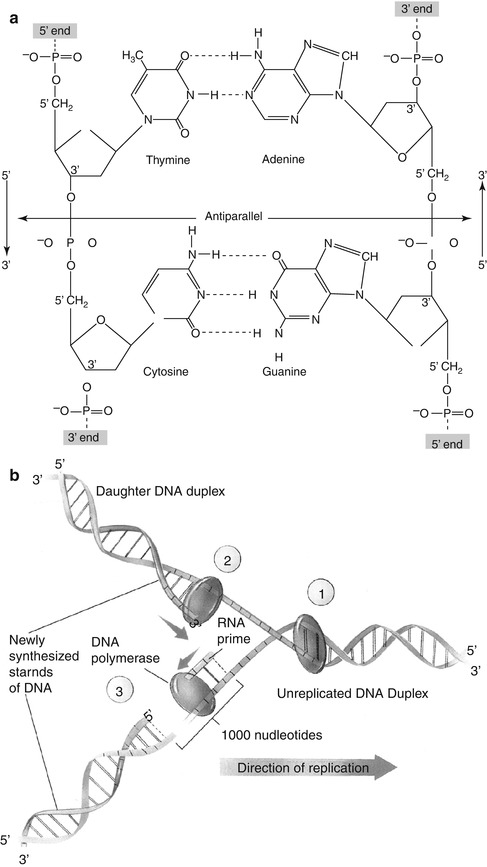
Fig. 2.3
(a) The double-stranded DNA molecule consists of four bases (thymine, cytosine, adenine, and guanine), deoxyribose sugar, and phosphate. The antiparallel nature of DNA strands shows the opposite direction of the two strands of a double helix. Note the hydrogen bonds between the two strands of DNA molecules (Reprinted with permission from Devin [2]). (b) DNA replication fork. Replication occurs in three stages: special proteins separate and stabilize the strands of the double helix, creating a fork (1). During continuous synthesis of a new DNA strand, DNA polymerase adds nucleotides to the 3′ end of a leading strand (2). In discontinuous synthesis, a short RNA primer is added 1,000 nucleotides ahead of the end of lagging strand. DNA polymerase then adds nucleotides to the primer until the gap is filled (3) (Reprinted with permission from Raven and Johnson [3])
The presence of 5′-phosphate and the 3′-hydroxyl groups in the deoxyribose molecule allows DNA to form a long chain of polynucleotides via the joining of nucleotides by phosphodiester bonds. Any linear strand of DNA will always have a free 5′-phosphate group at one end and a free 3′-hydroxyl group at the other. Therefore, the DNA molecule has an intrinsic directionality (5′–3′ direction). Although some forms of cellular DNA exist as single-stranded structures, the most widespread DNA structure, discovered by Watson and Crick in 1953, represents DNA as a double helix containing two polynucleotide strands that are complementary mirror images of each other. The “backbone” of the DNA molecule is composed of the deoxyribose sugars joined by phosphodiester bonds to a phosphate group, while the bases are linked in the middle of the molecule by hydrogen bonds. The relationship between the bases in a double helix is described as complementarity, since adenine always bonds with thymine and guanine always bonds with cytosine. As a consequence, the double-stranded DNA contains equal amounts of purines and pyrimidines. An important structural characteristic of double-stranded DNA is that its strands are antiparallel, meaning that they are aligned in opposite directions.
2.3.1.2 DNA Replication
In order to serve as the basic genetic material, all the chromosomes in the nucleus duplicate their DNA prior to every cell division. When a DNA molecule replicates, the double-stranded DNA separates or unzips at one end, forming a replication fork (Fig. 2.3b). The principle of complementary base pairing dictates that the process of replication proceeds by a mechanism in which a new DNA strand is synthesized that matches each of the original strands serving as a template. If the sequence of the template is ATTGCAT, the sequence of a new strand in the duplex must be TAACGTA. Replication is semiconservative, in the sense that at the end of each round of replication, one of the parental strands is maintained intact, and it combines with one newly synthesized complementary strand.
DNA replication requires the cooperation of many proteins and enzymes. While DNA helicases and single-stranded binding proteins help unzip the double helix and hold the strands apart, a self-correcting DNA polymerase moves along in a 5′→3′ direction on a single strand (leading strand) and catalyzes nucleotide polymerization or base pairing. Since the two strands are antiparallel, this 5′→3′ DNA synthesis can take place continuously on the leading strand only, while the base pairing on the lagging strand is discontinuous and involves synthesis of a series of short DNA molecules that are subsequently sealed together by the enzyme DNA ligase. In mammals, DNA replication occurs at a polymerization rate of about 50 nucleotides per second. At the end of replication, a repair process known as DNA proofreading is catalyzed by DNA ligase and DNA polymerase enzymes, which cut out the inappropriate or mismatched nucleotides from the new strand and replace these with the appropriate complementary nucleotides. The replication process almost never makes a mistake and the DNA sequences are maintained with very high fidelity. For example, a mammalian germline cell with a genome of 3 × 109 base pairs is subjected on average to only about 10–20 base pair changes per year. Genetic change, however, has great implications for evolution and human health; it is the product of mutation and recombination.
2.3.1.3 Gene Mutation
A mutation is any inherited change in the genetic material involving irreversible alterations in the sequence of DNA nucleotides. These mutations may be phenotypically silent (hidden) or expressed (visible). Mutations may be classified into two categories: base substitutions and frameshift mutations. Point mutations are base substitutions involving one or a few nucleotides in the coding sequence and may include replacement of a purine–pyrimidine base pair by another base pair (transitions) or a pyrimidine–purine base pair (transversions). Point mutations cause changes in the hereditary message of an organism and may result from physical or chemical damage to the DNA or from spontaneous errors during replication. Frameshift mutation involves spontaneous mispairing and may result from insertion or deletion of a base pair. Mutational damage to DNA is generally caused by one of three events: (a) ionizing radiation causes double-stranded breaks in DNA due to the action of free radicals on phosphodiester bonds, (b) ultraviolet radiation creates DNA cross-links due to the absorption of UV energy by pyrimidines, and (c) chemical mutagens modify DNA bases and alter base-pairing behavior. Mutations in germline tissue are of enormous biological significance, while somatic mutations may cause cancer.
2.3.1.4 DNA Recombination
DNA can undergo important and elegant exchange events through recombination, which refers to a number of distinct processes of genetic material rearrangement. Recombination is defined as the creation of new gene combinations and may include exchange of an entire chromosome or rearranging the position of a gene or a segment of a gene on a chromosome. Homologous or general recombination produces an exchange between a pair of distinct DNA molecules, usually located on two copies of the same chromosome. Sections of DNA may be moved back and forth between chromosomes, but the arrangement of genes on a chromosome is not altered. An important example is the exchange of sections of homologous chromosomes in the course of meiosis that is characteristic of gametes. As a result, homologous recombination generates new combinations of genes that can lead to genetic diversity. Site-specific recombination does not require DNA homology and involves alteration of the relative positions of short and specific nucleotide sequences in either one or both of the two participating DNA molecules. Transpositional recombination involves insertion of viruses, plasmids, and transposable elements, or transposons into chromosomal DNA. Gene transfer in general represents the unidirectional transfer of genes from one chromosome to another. The acquisition of an AIDS-bearing virus by a human chromosome is an example of gene transfer.
2.3.2 Gene Expression and Protein Synthesis
2.3.2.1 DNA Transcription
Proteins are the tools of heredity. The essence of heredity is the ability of the cell to use the information in its DNA to control and direct the synthesis of all proteins in the body. The production of RNA is called transcription and is the first stage of gene expression. The result is the formation of messenger RNA (mRNA) from the base sequence specified by the DNA template. All types of RNA molecules are transcribed from the DNA. An enzyme called RNA polymerase first binds to a promoter site (beginning of a gene), then unwinds the two strands of DNA double helix, moves along the DNA strand, and synthesizes the RNA molecule by binding complementary RNA nucleotides with the DNA strand. Upon reaching the termination sequence, the enzyme breaks away from the DNA strand, and at the same time, the RNA molecule is released into the nucleoplasm. It is important to recognize that only one strand (the sense strand) of the DNA helix contains the appropriate sequence of bases to be copied into an RNA sense strand. This is accomplished by maintaining the 5′–3′ direction in producing the RNA molecule. As a result, the RNA chain is complementary to the DNA strand and is called the primary RNA transcript of the gene. This primary RNA transcript consists of long stretches of noncoding nucleotide sequences called introns that intervene between the protein-coding nucleotide sequences called exons. In order to generate mRNA molecules, all the introns are cut out and the exons are spliced together. Further modifications to stabilize the transcript include 5-methylguanine capping at the 5′ end and polyadenylation at the 3′ end. The spliced, stabilized mRNA molecules are finally transported to the ER in the cytoplasm, where proteins are synthesized.
2.3.2.2 RNA Structure
Both transcription and translation are mediated by the RNA molecule, an unbranched linear polymer of ribonucleoside 5′-monophophates. RNA is chemically similar to DNA, the main difference being that the RNA molecule contains ribose sugar and another pyrimidine, uracil, in place of thymine. RNAs are classified according to the different roles they play in the course of protein synthesis. The length of the molecules varies from approximately 65–200,000 nucleotides, depending upon the role they play. There are many types of RNA molecules within a cell, and some RNAs contain modified nucleotides which provide greater metabolic stability. mRNA molecules carry the genetic code to the ribosomes, where they serve as templates for the synthesis of proteins. The transfer RNA (tRNA) molecule, also generated in the nucleus, transfers specific amino acids from the soluble amino acid pool to the ribosomes and ensures the alignment of these amino acids in a proper sequence. Ribosomal RNA (rRNA) forms the structural framework of ribosomes, where most proteins are synthesized. All RNA molecules are synthesized in the nucleus. While the enzyme RNA polymerize II is mainly responsible for the synthesis of mRNA, RNA polymerases I and III mediate the synthesis of rRNA and tRNA, respectively.
2.3.3 Genetic Code
The genetic code in a DNA sense strand consists of a specific nucleotide sequence coded in successive “triplets” that will eventually control the sequence of amino acids in a protein molecule. During transcription, a complementary code of triplets in the mRNA molecule, called codons, is synthesized. For example, the successive triplets in a DNA sense strand are represented by bases, GGC, AGA, and CTT. The corresponding complementary mRNA codons are CCG, UCU, and GAA representing the three amino acids proline, serine, and glutamic acid, respectively. Each amino acid is represented by a specific mRNA codon. The various mRNA codons for the 20 amino acids and the codons for starting and stopping protein synthesis are summarized in Table 2.4. The genetic code is regarded as degenerate, since most of the amino acids are represented by more than one codon. An important feature of the genetic code is that it is universal; all living organisms use precisely the same DNA codes to specify proteins.
Table 2.4
The genetic code: RNA codons for the different amino acids and for the start and stop of protein synthesis
Amino acid | Letter code | RNA codons | |||||
|---|---|---|---|---|---|---|---|
Alanine | A | GCU | GCC | GCA | GCG | ||
Arginine | R | CGU | CGC | CGA | CGG | AGA | AGG |
Asparagine | D | AAU | AAC | ||||
Aspartic acid | N | GAU | GAC | ||||
Cysteine | C | UGU
Related posts:Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree
 Get Clinical Tree app for offline access
Get Clinical Tree app for offline access

| |||||