Fig. 1.
Exemplary cardiac phases of CP-BOLD MR (top row) and standard CINE MR (bottom row) obtained from the same subject under baseline conditions (absence of ischemia) where the myocardium is color coded to underline the challenge of appearance variation in CP-BOLD MR which is minimal in the case of standard CINE MR (Color figure online).
We adopt a patch-based discriminative dictionary learning technique (which has been used also in echocardiography [6]) to learn features from previously segmented data in a fully supervised manner. The motivation behind the choice of a sparse dictionary is to employ a compact and high-fidelity low-dimensional subspace representation which is able to extract semantic information of the myocardium as well [16]. The key observation behind this strategy is that, though the patch intensity level varies significantly across the cardiac cycle, sparse representations based on learnt dictionaries are invariant across the cardiac cycle, as well as unique and robust. Briefly described, during training two separate dictionaries are learnt at multiple scales for the myocardium and background. In this regard, we also introduce a discriminative initialization step (discarding patches with high values in intra-class Gram matrix) to promote diversity in initialization, and a discriminative pruning step (discarding training patches with high values in inter-class Gram matrix) to further boost the discriminative abilities of the dictionaries. During testing, multiscale sparse features are used.
The main contributions of the paper are twofold. First, we experimentally demonstrate that BOLD contrast significantly affects the accuracy of segmentation algorithms (including segmentation via registration of an atlas, level sets, supervised classifier-based and other dictionary-based methods) which instead perform well in standard CINE MR. Second, to address our hypothesis we design a set of compact features using Multi-Scale Discriminative Dictionary Learning, which can effectively represent the myocardium in CP-BOLD MR. The method has been evaluated on canine subjects, which makes the problem even more challenging (lower accuracy is expected) due to the smaller size of myocardium. The remainder of the paper is organized as follows: Sect. 2 discusses related work, Sect. 3 presents the proposed method, whereas results are described in Sect. 4. Finally, Sect. 5 offers discussions and conclusion.
2 Related Work
Automated myocardial segmentation for standard CINE MR is a well studied problem [10]. Most of these algorithms can be broadly classified into three categories based on whether the methodology is segmentation-only, level set or Atlas-based segmentation with inherent registration. Recently, Atlas-based segmentation techniques have received significant attention. The myocardial segmentation masks available from other subject(s) are generally propagated to unseen data in Atlas-based techniques [2] using non-rigid registration algorithms, e.g., diffeomorphic demons (dDemons) [15], FFD-MI [5] or probabilistic label fusion [2]. Level set class of techniques uses a non-parametric way for segmenting myocardium with weak prior knowledge [3, 7].
Segmentation-only class of techniques mainly focuses on feature-based representation of the myocardium. Texture information is generally considered as an effective feature representation of the myocardium for standard CINE MR images [17]. The patch-based static discriminative dictionary learning technique (SJTAD) [11] and Multi-scale Appearance Dictionary Learning technique [6] have achieved high accuracy and are considered as state-of-the-art mechanisms for supervised learning of discernible myocardial features from previously segmented data. In this paper, we follow the segmentation-only approach with the major feature of considering multi-scale appearance and texture information as the input of a discriminative dictionary learning procedure.
3 Method
General image segmentation strategies are developed on the assumption that both appearance and shape do not vary considerably across the images of a given sequence. Cardiac motion affects the shape invariance assumption, and varying CP-BOLD signal intensities violate the appearance invariance assumption as well. To overcome this issue, dictionary learning techniques can be leveraged to learn better representative features. To this end, we propose a Multi-Scale Discriminative Dictionary Learning (MSDDL) method (detailed in Algorithm 1). The features learnt via dictionary learning are tested in a rudimentary classification scheme solely for the purpose of comparing to other methods.
Feature generation with Multi-scale Discriminative Dictionary Learning (MSDDL): Given some sequences of training images and corresponding ground truth labels (i.e. masks), we can obtain two sets of matrices, 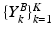 and
and 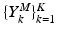 , where the matrix
, where the matrix 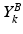 contains the background information at a particular scale k (each scale is characterized by a different patch size), and
contains the background information at a particular scale k (each scale is characterized by a different patch size), and 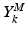 is the corresponding matrix referring to the myocardium. Information is collected from image patches: squared patches are sampled around each pixel of the training images. More precisely, the i-th column of the matrix
is the corresponding matrix referring to the myocardium. Information is collected from image patches: squared patches are sampled around each pixel of the training images. More precisely, the i-th column of the matrix 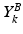 (and similarly for the matrix
(and similarly for the matrix 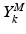 ) is obtained by concatenating the normalized patch vector of pixel intensities at scale k, taken around the i-th pixel in the background, along with the Gabor and HOG features of the same patch. Our MSDDL method takes as input these two sets of training matrices, to learn, at each scale k, two dictionaries,
) is obtained by concatenating the normalized patch vector of pixel intensities at scale k, taken around the i-th pixel in the background, along with the Gabor and HOG features of the same patch. Our MSDDL method takes as input these two sets of training matrices, to learn, at each scale k, two dictionaries, 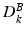 and
and 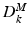 , and two sparse feature matrices,
, and two sparse feature matrices, 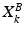 and
and 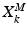 . E.g. , the i-th column of the matrix
. E.g. , the i-th column of the matrix 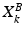 ,
, 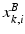 , is considered as the discriminative feature vector for the particular pixel corresponding to the i-th column in
, is considered as the discriminative feature vector for the particular pixel corresponding to the i-th column in 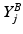 . Dictionaries and sparse features are trained via the well known K-SVD algorithm [1]. One main modification to K-SVD is the use of the “intra-class Gram matrix” to promote diversity in the initialization step. The idea is to have a subset of patches as much diverse as possible to train dictionaries and sparse features. For a given class considered (let us say background) and a given scale k, we can define the intra-class Gram matrix as
. Dictionaries and sparse features are trained via the well known K-SVD algorithm [1]. One main modification to K-SVD is the use of the “intra-class Gram matrix” to promote diversity in the initialization step. The idea is to have a subset of patches as much diverse as possible to train dictionaries and sparse features. For a given class considered (let us say background) and a given scale k, we can define the intra-class Gram matrix as 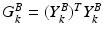 . To ensure a proper discriminative initialization, patches that correspond to high values in the Gram matrix are discarded from the training before performing K-SVD. Notably, we sort the training patches w.r.t. the sum of their related coefficients in the Gram Matrix, and we prune them by choosing a certain percentage.
. To ensure a proper discriminative initialization, patches that correspond to high values in the Gram matrix are discarded from the training before performing K-SVD. Notably, we sort the training patches w.r.t. the sum of their related coefficients in the Gram Matrix, and we prune them by choosing a certain percentage.
and , where the matrix contains the background information at a particular scale k (each scale is characterized by a different patch size), and is the corresponding matrix referring to the myocardium. Information is collected from image patches: squared patches are sampled around each pixel of the training images. More precisely, the i-th column of the matrix (and similarly for the matrix ) is obtained by concatenating the normalized patch vector of pixel intensities at scale k, taken around the i-th pixel in the background, along with the Gabor and HOG features of the same patch. Our MSDDL method takes as input these two sets of training matrices, to learn, at each scale k, two dictionaries, and , and two sparse feature matrices, and . E.g. , the i-th column of the matrix , , is considered as the discriminative feature vector for the particular pixel corresponding to the i-th column in . Dictionaries and sparse features are trained via the well known K-SVD algorithm [1]. One main modification to K-SVD is the use of the “intra-class Gram matrix” to promote diversity in the initialization step. The idea is to have a subset of patches as much diverse as possible to train dictionaries and sparse features. For a given class considered (let us say background) and a given scale k, we can define the intra-class Gram matrix as . To ensure a proper discriminative initialization, patches that correspond to high values in the Gram matrix are discarded from the training before performing K-SVD. Notably, we sort the training patches w.r.t. the sum of their related coefficients in the Gram Matrix, and we prune them by choosing a certain percentage.A second proposed modification relates to a pruning step, which is performed after K-SVD. In this case, at each scale k, an “inter-class Gram matrix” is computed (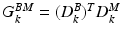 ): the atoms of each dictionary are sorted according to their cumulative coefficients in
): the atoms of each dictionary are sorted according to their cumulative coefficients in 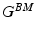 , and a chosen percentage of them is discarded to ensure mutual exclusiveness between the dictionaries of the two different classes. The philosophy behind this operation is similar to the one of the discriminative dictionary learning algorithm proposed in [8], where the norm of the inter-class Gram matrix appears in the optimization formulation as a constraint to be minimized. By pruning the undesired dictionary atoms all at one time, we actually adopt a greedier and low-complexity approach to the same problem. Moreover, we believe that, instead of globally minimizing the Gram matrix norm, directly removing the most “problematic” patches, which create ambiguity between background and myocardium, is more effective in our case.
, and a chosen percentage of them is discarded to ensure mutual exclusiveness between the dictionaries of the two different classes. The philosophy behind this operation is similar to the one of the discriminative dictionary learning algorithm proposed in [8], where the norm of the inter-class Gram matrix appears in the optimization formulation as a constraint to be minimized. By pruning the undesired dictionary atoms all at one time, we actually adopt a greedier and low-complexity approach to the same problem. Moreover, we believe that, instead of globally minimizing the Gram matrix norm, directly removing the most “problematic” patches, which create ambiguity between background and myocardium, is more effective in our case.

): the atoms of each dictionary are sorted according to their cumulative coefficients in , and a chosen percentage of them is discarded to ensure mutual exclusiveness between the dictionaries of the two different classes. The philosophy behind this operation is similar to the one of the discriminative dictionary learning algorithm proposed in [8], where the norm of the inter-class Gram matrix appears in the optimization formulation as a constraint to be minimized. By pruning the undesired dictionary atoms all at one time, we actually adopt a greedier and low-complexity approach to the same problem. Moreover, we believe that, instead of globally minimizing the Gram matrix norm, directly removing the most “problematic” patches, which create ambiguity between background and myocardium, is more effective in our case.Building a Rudimentary Classifier for Segmentation: When considering the same patch-based approach in a segmentation problem, we have a set of test matrices 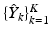 , obtained by sampling patches at multiple scales from the test image, and concatenating intensity values of these patches, along with Gabor and HOG features. The goal is to assign to each pixel of the test image a label, i.e. establish if the pixel is included in the background or the myocardial region. To perform this classification, we use the multi-scale dictionaries,
, obtained by sampling patches at multiple scales from the test image, and concatenating intensity values of these patches, along with Gabor and HOG features. The goal is to assign to each pixel of the test image a label, i.e. establish if the pixel is included in the background or the myocardial region. To perform this classification, we use the multi-scale dictionaries, 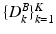 and
and 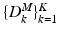 , previously learnt with MSDDL. The Orthogonal Matching Pursuit (OMP) algorithm [12] is used to compute, at each scale k, the two sparse feature matrices
, previously learnt with MSDDL. The Orthogonal Matching Pursuit (OMP) algorithm [12] is used to compute, at each scale k, the two sparse feature matrices 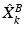 and
and 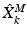 . A certain patch at scale k,
. A certain patch at scale k, 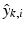 will be assigned to the class that gives the smallest dictionary approximation error. More precisely, if
will be assigned to the class that gives the smallest dictionary approximation error. More precisely, if 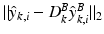 is larger than
is larger than 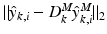 , at scale k the patch is assigned to the background; otherwise, it is considered belonging to the myocardial region. In this study, we employed a simple majority voting across all scales to obtain the final classification for each pixel of the test image.
, at scale k the patch is assigned to the background; otherwise, it is considered belonging to the myocardial region. In this study, we employed a simple majority voting across all scales to obtain the final classification for each pixel of the test image.
, obtained by sampling patches at multiple scales from the test image, and concatenating intensity values of these patches, along with Gabor and HOG features. The goal is to assign to each pixel of the test image a label, i.e. establish if the pixel is included in the background or the myocardial region. To perform this classification, we use the multi-scale dictionaries, and , previously learnt with MSDDL. The Orthogonal Matching Pursuit (OMP) algorithm [12] is used to compute, at each scale k, the two sparse feature matrices and . A certain patch at scale k, will be assigned to the class that gives the smallest dictionary approximation error. More precisely, if is larger than , at scale k the patch is assigned to the background; otherwise, it is considered belonging to the myocardial region. In this study, we employed a simple majority voting across all scales to obtain the final classification for each pixel of the test image.Related posts:
 Motion Estimation Using Ultrafast Ultrasound Imaging Tested in a Finite Element Model of Cardiac Mechanics
Motion Estimation Using Ultrafast Ultrasound Imaging Tested in a Finite Element Model of Cardiac Mechanics
 Anisotropic Myocardial Stiffness from Magnetic Resonance Elastography: A Simulation Study
Anisotropic Myocardial Stiffness from Magnetic Resonance Elastography: A Simulation Study
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


