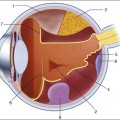
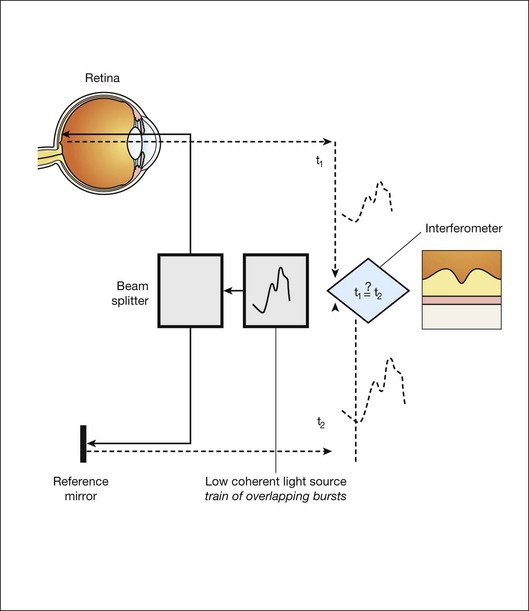
Chapter 6 The optical properties of the eye that allow image formation prevent direct inspection of the retina. Though existence of the red reflex has been known for centuries, special techniques are needed to obtain a focused image of the retina. The first attempt to image the retina, in a cat, was completed by the French physician Jean Mery, who showed that if a live cat is immersed in water, its retinal vessels are visible from the outside.1 The impracticality of such an approach for humans led to the invention of the principles of the ophthalmoscope in 1823 by Czech scientist Jan Evangelista Fig. 6.1 First known image of human retina, as drawn by van Trigt in 1853. (Reproduced from Trigt AC. Dissertatio ophthalmologica inauguralis de speculo oculi. Utrecht: Universiteit van Utrecht, 1853.) In 1961, Novotny and Alvis published their findings on fluorescein angiographic imaging.8 In this imaging modality, a fundus camera with additional narrow-band filters is used to image a fluorescent dye injected into the bloodstream that binds to leukocytes. It remains widely used, because it allows an understanding of the functional state of the retinal circulation. The initial approach to depict the three-dimensional (3D) shape of the retina was stereo fundus photography, as first described by Allen in 1964, where multiangle images of the retina are combined by the human observer into a 3D shape.9 Subsequently, confocal scanning laser ophthalmoscopy (SLO) was developed, using the confocal aperture to obtain multiple images of the retina at different confocal depths, yielding estimates of 3D shape. However, the optics of the eye limit the depth resolution of confocal imaging to approximately 100 µm, which is poor when compared with the typical 300–500 µm thickness of the whole retina.10 OCT, first described in 1987 as a method for time-of-flight measurement of the depth of mechanical structures,11,12 was later extended to a tissue-imaging technique. This method of determining the position of structures in tissue, described by Huang et al. in 1991,13 was termed OCT. In 1993 in vivo retinal OCT was accomplished for the first time.14 Today, OCT has become a prominent biomedical tissue-imaging technique, especially in the eye, because it is particularly suited to ophthalmic applications and other tissue imaging requiring micrometer resolution. Matsui et al. were the first to publish a method for retinal image analysis, primarily focused on vessel segmentation.15 Their approach was based on mathematical morphology and they used digitized slides of fluorescein angiograms of the retina. In the following years, there were several attempts to segment other anatomical structures in the normal eye, all based on digitized slides. The first method to detect and segment abnormal structures was reported in 1984, when Baudoin et al. described an image analysis method for detecting microaneurysms, a characteristic lesion of diabetic retinopathy (DR).16 Their approach was also based on digitized angiographic images. They detected microaneurysms using a “top-hat” transform, a step-type digital image filter.17 This method employs a mathematical morphology technique that eliminates the vasculature from a fundus image yet leaves possible microaneurysm candidates untouched. The field dramatically changed in the 1990s with the development of digital retinal imaging and the expansion of digital filter-based image analysis techniques. These developments resulted in an exponential rise in the number of publications, which continues today. Retinal imaging has developed rapidly during the last 160 years and is a now a mainstay of the clinical care and management of patients with retinal as well as systemic diseases. Fundus photography is widely used for population-based, large-scale detection of DR, glaucoma, and age-related macular degeneration. OCT and fluorescein angiography are widely used in the daily management of patients in a retina clinic setting. OCT has also become an increasingly helpful adjunct in preoperative planning and postoperative evaluation of vitreoretinal surgical patients.18 The overview below is partially based on an earlier review paper.19 1. fundus photography (including so-called red-free photography): image intensities represent the amount of reflected light of a specific waveband 2. color fundus photography: image intensities represent the amount of reflected red (R), green (G), and blue (B) wavebands, as determined by the spectral sensitivity of the sensor 3. stereo fundus photography: image intensities represent the amount of reflected light from two or more different view angles for depth resolution 4. SLO: image intensities represent the amount of reflected single-wavelength laser light obtained in a time sequence 5. adaptive optics SLO: image intensities represent the amount of reflected laser light optically corrected by modeling the aberrations in its wavefront 6. fluorescein angiography and indocyanine angiography: image intensities represent the amounts of emitted photons from the fluorescein or indocyanine green fluorophore that was injected into the subject’s circulation. There are several technical challenges in fundus imaging. Since the retina is normally not illuminated internally, both external illumination projected into the eye as well as the retinal image projected out of the eye must traverse the pupillary plane. Thus the size of the pupil, usually between 2 and 8 mm in diameter, has been the primary technical challenge in fundus imaging.7 Fundus imaging is complicated by the fact that the illumination and imaging beams cannot overlap because such overlap results in corneal and lenticular reflections diminishing or eliminating image contrast. Consequently, separate paths are used in the pupillary plane, resulting in optical apertures on the order of only a few millimeters. Because the resulting imaging setup is technically challenging, fundus imaging historically involved relatively expensive equipment and highly trained ophthalmic photographers. Over the last 10 years or so, there have been several important developments that have made fundus imaging more accessible, resulting in less dependence on such experience and expertise. There has been a shift from film-based to digital image acquisition, and as a consequence the importance of picture archiving and communication systems (PACS) has substantially increased in clinical ophthalmology, also allowing integration with electronic medical records. Requirements for population-based early detection of retinal diseases using fundus imaging have provided the incentive for effective and user-friendly imaging equipment. Operation of fundus cameras by nonophthalmic photographers has become possible due to nonmydriatic imaging, digital imaging with near-infrared focusing, and standardized imaging protocols to increase reproducibility. OCT is a noninvasive optical medical diagnostic imaging modality which enables in vivo cross-sectional tomographic visualization of the internal microstructure in biological systems. OCT is analogous to ultrasound B-mode imaging, except that it measures the echo time delay and magnitude of light rather than sound, therefore achieving unprecedented image resolutions (1–10 µm).20 OCT is an interferometric technique, typically employing near-infrared light. The use of relatively long-wavelength light with a very wide-spectrum range allows OCT to penetrate into the scattering medium and achieve micrometer resolution. The principle of OCT is based upon low-coherence interferometry, where the backscatter from more outer retinal tissues can be differentiated from that of more inner tissues, because it takes longer for the light to reach the sensor. Because the differences between the most superficial and the deepest layers in the retina are around 300–400 µm, the difference in time of arrival is very small and requires interferometry to measure.21 We see the importance of the choice of a good low-coherence source – with either an incoherent or fully coherent source, interferometry is impossible. Such light can be generated by using superluminescent diodes (superbright light-emitting diodes) or lasers with extremely short pulses, femtosecond lasers. The optical setup typically consists of a Michelson interferometer with a low-coherence, broad-bandwidth light source (Fig. 6.2). By scanning the mirror in the reference arm, as in time domain OCT, modulating the light source, as in swept source OCT, or decomposing the signal from a broadband source into spectral components, as in spectral domain OCT (SD-OCT), a reflectivity profile of the sample can be obtained, as measured by the interferogram. The reflectivity profile, called an A-scan, contains information about the spatial dimensions and location of structures within the retina. A cross-sectional tomograph (B-scan) may be achieved by laterally combining a series of these axial depth scans (A-scan). En face imaging (C-scan) at an acquired depth is possible depending on the imaging engine used. Fig. 6.2 Schematic diagram of the operation of an optical coherence tomography instrument, emphasizing splitting of the light in two arms, overlapping train of bursts “labeled” based on their autocorrelogram, and their interference after being reflected from retinal tissue as well as from the reference mirror (assuming the time delays of both paths are equal). With time domain OCT, the reference mirror is moved mechanically to different positions, resulting in different flight time delays for the reference arm light. Because the speed at which the mirror can be moved is mechanically limited, only thousands of A-scans can be obtained per second. The envelope of the interferogram determines the intensity at each depth.13 The ability to image the retina two-dimensionally and three-dimensionally depends on the number of A-scans that can be acquired over time. Because of motion artifacts such as saccades, safety requirements limiting the amount of light that can be projected on to the retina, and patient comfort, 1–3 seconds per image or volume is essentially the limit of acceptance. Thus, the commercially available time domain OCT, which allowed collecting of up to 400 A-scans per second, has not yet been suitable for 3D imaging. A broadband light source is used, broader than in time domain OCT, and the interferogram is decomposed spectrally using a diffraction grating and a complementary metal oxide semiconductor or charged couple device linear sensor. The Fourier transform is again applied to the spectral correlogram intensities to determine the depth of each scatter signal.22 With SD-OCT, tens of thousands of A-scans can be acquired each second, and thus true 3D imaging is routinely possible. Consequently, 3D OCT is now in wide clinical use, and has become the standard of care. Instead of moving the reference arm, as with time domain OCT imaging, in swept source OCT the light source is rapidly modulated over its center wavelength, essentially attaching a second label to the light, its wavelength. A photo sensor is used to measure the correlogram for each center wavelength over time. A Fourier transform on the multiwavelength or spectral interferogram is performed to determine the depth of all tissue scatters at the imaged location.22 With swept source OCT, hundreds of thousands of A-scans can be obtained every second, with additional increase in scanning density when acquiring 3D image volumes. For early detection and screening, the optimal place for positioning fundus cameras is at the point of care: primary care clinics, public venues (e.g., drug stores, shopping malls). Though the transition from film-based to digital fundus imaging has revolutionized the art of fundus imaging and made telemedicine applications feasible, the current cameras are still too bulky, expensive, and may be difficult to use for untrained staff in places lacking ophthalmic imaging expertise. Several groups are attempting to create more cost-effective and easier-to-use handheld fundus cameras, employing a variety of technical approaches.23,24 For the patient as well as for the clinician, the outcome of disease management is mainly concerned with the resulting organ function, not its structure. In ophthalmology, current functional testing is mostly subjective and patient-dependent, such as assessing visual acuity and utilizing perimetry, which are all psychophysical metrics. Among more recently developed “objective” techniques, oxymetry is a hyperspectral imaging technique in which multispectral reflectance is used to estimate the concentration of oxygenated and deoxygenated hemoglobin in the retinal tissue.25 The principle allowing the detection of such differences is simple: deoxygenated hemoglobin reflects longer wavelengths better than does oxygenated hemoglobin. Nevertheless, measuring absolute oxygenation levels with reflected light is difficult because of the large variety in retinal reflection across individuals and the variability caused by the imaging process. The retinal reflectance can be modeled by a system of equations, and this system is typically underconstrained if this variability is not accounted for adequately. Increasingly sophisticated reflectance models have been developed to correct for the underlying variability, with some reported success.26 Near-infrared fundus reflectance in response to visual stimuli is another way to determine the retinal function in vivo and has been successful in cats. Initial progress has also been demonstrated in humans.27 The optical properties of the normal eye result in a point spread function width approximately the size of a photoreceptor. It is therefore impossible to image individual cells or cell structure using standard fundus cameras because of aberrations in the human optical system. Adaptive optics uses mechanically activated mirrors to correct the wavefront aberrations of the light reflected from the retina, and thus has allowed individual photoreceptors to be imaged in vivo.28 Imaging other cells, especially the clinically highly important ganglion cells, has thus far been unsuccessful in humans. 3D OCT imaging is now the clinical standard of care for several eye diseases. The wavelengths around 840 µm used in currently available devices are optimized for imaging of the retina. Deeper structures, such as the choroidal vessels, which are important for AMD and other choroidal diseases, and the lamina cribrosa, relevant for glaucomatous damage, are not as well depicted. Because longer wavelengths penetrate deeper into the tissue, a major research effort has been undertaken to develop low-coherence swept source lasers with center wavelengths of 1000–1300 µm. Prototypes of these devices are already able to resolve detail in the choroid and lamina cribrosa.29 The most obvious example of a retinal screening application is retinal disease detection, in which the patient’s retinas are imaged in a remote telemedicine approach. This scenario typically utilizes easy-to-use, relatively low-cost fundus cameras, automated analyses of the images, and focused reporting of the results. This screening application has spread rapidly over the last few years, and, with the exception of the automated analysis functionality, is one of the most successful examples of telemedicine.30 While screening programs exist for detection of glaucoma, age-related macular degeneration, and retinopathy of prematurity, the most important screening application focuses on early detection of DR. Early detection of DR via population screening associated with timely treatment has been shown to prevent visual loss and blindness in patients with retinal complications of diabetes.31,32 Almost 50% of people with diabetes in the USA currently do not undergo any form of regular documented dilated eye exam, in spite of guidelines published by the American Diabetes Association, the American Academy of Ophthalmology, and the American Optometric Association.33 In the UK, a smaller proportion or approximately 20% of diabetics are not regularly evaluated, as a result of an aggressive effort to increase screening for people with diabetes. Blindness and visual loss can be prevented through early detection and timely management. There is widespread consensus that regular early detection of DR via screening is necessary and cost-effective in patients with diabetes.34–37 Remote digital imaging and ophthalmologist expert reading have been shown to be comparable or superior to an office visit for assessing DR and have been suggested as an approach to make the dilated eye exam available to unserved and underserved populations that do not receive regular exams by eye care providers.38,39 If all of these underserved populations were to be provided with digital imaging, the annual number of retinal images requiring evaluation would exceed 32 million in the USA alone (approximately 40% of people with diabetes with at least two photographs per eye).39,40 In the next decade, projections for the USA are that the average age will increase, the number of people with diabetes in each age category will increase, and there will be an undersupply of qualified eye care providers, at least in the near term. Several European countries have successfully instigated in their healthcare systems early detection programs for DR using digital photography with reading of the images by human experts. In the UK, 1.7 million people with diabetes were screened for DR in 2007–2008. In the Netherlands, over 30 000 people with diabetes were screened since 2001 in the same period, through an early-detection project called EyeCheck.41 The US Department of Veterans Affairs has deployed a successful photo screening program through which more than 120 000 veterans were screened in 2008. While the remote imaging followed by human expert diagnosis approach was shown to be successful for a limited number of participants, the current challenge is to make the early detection more accessible by reducing the cost and staffing levels required, while maintaining or improving DR detection performance. This challenge can be met by utilizing computer-assisted or fully automated methods for detection of DR in retinal images.42–44 In addition to detecting DR and age-related macular degeneration, it also deserves mention that fundus photography allows certain cardiovascular risk factors to be determined. Such metrics are primarily based on measurement of retinal vessel properties, such as the arterial to venous diameter ratio, and indicate the risk for stroke, hypertension, or myocardial infarct.45,46 Another highly relevant example of a disease that will benefit from image-guided therapy is exudative age-related macular degeneration. With the advent of the anti-vascular endothelial growth factor (VEGF) agents ranibizumab and bevacizumab, it has become clear that outer retinal and subretinal fluid is the main indicator of a need for anti-VEGF retreatment.47–51 Several studies are under way to determine whether OCT-based quantification of fluid parameters and affected retinal tissue can help improve the management of patients with anti-VEGF agents. Image analysis is a field that relies heavily on mathematics and physics. The goal of this section is to explain the major clinically relevant concepts and challenges in image analysis, with no use of mathematics or equations. For a detailed explanation of the underlying mathematics, the reader is referred to the appropriate textbooks.52 • Slides and computer printouts stored in the paper chart or photo archive • Slides and paper printouts scanned and stored in a PACS • Clinically relevant views stored in a PACS • All raw data and clinically relevant views stored in a PACS • Standard for storage and communication of ophthalmology images. DICOM stands for Digital Imaging and Communications in Medicine and is an organization founded in 1983 to create a standard method for the transmission of medical images and their associated information across all fields of medicine. For ophthalmology, Working Group 9 (WG-9) of DICOM is a formal part of the American Academy of Ophthalmology. Until recently, the work of WG-9 has focused on creating standards for fundus, anterior-segment, and external ophthalmic photography, resulting in DICOM Supplement 91 Ophthalmic Photography Image SOP Classes, and on OCT imaging in DICOM Supplement 110: Ophthalmic Tomography Image Storage SOP53,54 (http://medical.nema.org). There are many parallels between image preprocessing using computers and human retinal image processing in ganglion cells.19 There are many parallels between the features and the convolution process in digital image analysis, and the filters in the human visual cortex.55 The design and development of a retinal image analysis system usually involves the combination of some of the steps as explained above, with specific sizes of features and specific operations used to map the input image into the desired interpretation output. The term “unsupervised” is used to indicate such systems. The term “supervised” is used when the algorithm is improved in stepwise fashion by testing whether additional steps or a choice of different parameters can improve performance. This procedure is also called training. The theoretical disadvantage of using a supervised system with a training set is that the provenance of the different settings may not be clear. However, because all retinal image analysis algorithms undergo some optimization of parameters, by the designer or programer, before clinical use, this is only a relative, not absolute, difference. Two distinct stages are required for a supervised learning/classification algorithm to function: a training stage, in which the algorithm “statistically learns” to classify correctly from known classifications, and a testing or classification stage in which the algorithm classifies previously unseen images. For proper assessment of supervised classification method functionality, training data and performance testing data sets must be completely separate.52 Pixel feature classification is a machine learning technique that assigns one or more classes to the pixels in an image.55,57 Pixel classification uses multiple pixel features including numeric properties of a pixel and the surroundings of a pixel. Originally, pixel intensity was used as a single feature. More recently, n-dimensional multifeature vectors are utilized, including pixel contrast with the surrounding region and information regarding the pixel’s proximity to an edge. The image is transformed into an n-dimensional feature space and pixels are classified according to their position in space. The resulting hard (categorical) or soft (probabilistic) classification is then used either to assign labels to each pixel (for example “vessel” or “nonvessel” in the case of hard classification), or to construct class-specific likelihood maps (e.g., a vesselness map for soft classification). The number of potential features in the multifeature vector that can be associated with each pixel is essentially infinite. One or more subsets of this infinite set can be considered optimal for classifying the image according to some reference standard. Hundreds of features for a pixel can be calculated in the training stage to cast as wide a net as possible, with algorithmic feature selection steps used to determine the most distinguishing set of features. Extensions of this approach include different approaches to classifying groups of neighboring pixels subsequently by utilizing group properties in some manner, for example cluster feature classification, where the size, shape, and average intensity of the cluster may be used. The performance of a lesion detection system can be measured by its sensitivity, which is the number of true positives divided by the sum of the total number of (incorrectly missed) false negatives plus the number of (correctly identified) true positives.52 System specificity is determined as the number of true negatives divided by the sum of the total number of false positives (incorrectly identified as disease) and true negatives. Sensitivity and specificity assessment both require ground truth, which is represented by location-specific discrete values (0 or 1) of disease presence or absence for each subject in the evaluation set. The location-specific output of an algorithm can also be represented by a discrete number (0 or 1). However, the output of the assessment algorithm is often a continuous value determining the likelihood p of local disease presence, with an associated probability value between 0 and 1. Consequently, the algorithm can be made more specific or more sensitive by setting an operating threshold on this probability value, p. If an algorithm outputs a continuous value, as explained above, multiple sensitivity/specificity pairs for different operating thresholds can be calculated. These can be plotted in a graph, which yields a curve, the so-called receiver operator characteristics or ROC curve.52,56 The area under this ROC curve (AUC, represented by its value Az) is determined by setting a number of different thresholds for the likelihood p. Sensitivity and specificity pairs of the algorithm are then obtained at each of these thresholds. The ground truth is kept constant. The maximum AUC is 1, denoting a perfect diagnostic procedure, with some threshold at which both sensitivity and specificity are 1 (100%). Typically these performance measurements are made by comparing the output of the image analysis system to some standard, usually called the reference standard or gold standard. Because the performance of some image analysis systems, for example for detection of DR, is starting to exceed that of individual clinicians or groups of clinicians, creating the reference standard is an area of active research.42
Image Processing
History of retinal imaging
 (frequently spelled Purkinje) and its reinvention in 1845 by Charles Babbage.2,3 Finally, the ophthalmoscope was reinvented yet again and reported by von Helmholtz in 1851.4 Thus, inspection and evaluation of the retina became routine for ophthalmologists, and the first images of the retina (Fig. 6.1) were published by the Dutch ophthalmologist van Trigt in 1853.5 The first useful photographic images of the retina, showing blood vessels, were obtained in 1891 by the German ophthalmologist Gerloff.6 In 1910, Gullstrand developed the fundus camera, a concept still used to image the retina today7; he later received the Nobel Prize for this invention. Because of its safety and cost-effectiveness at documenting retinal abnormalities, fundus imaging has remained the primary method of retinal imaging.
(frequently spelled Purkinje) and its reinvention in 1845 by Charles Babbage.2,3 Finally, the ophthalmoscope was reinvented yet again and reported by von Helmholtz in 1851.4 Thus, inspection and evaluation of the retina became routine for ophthalmologists, and the first images of the retina (Fig. 6.1) were published by the Dutch ophthalmologist van Trigt in 1853.5 The first useful photographic images of the retina, showing blood vessels, were obtained in 1891 by the German ophthalmologist Gerloff.6 In 1910, Gullstrand developed the fundus camera, a concept still used to image the retina today7; he later received the Nobel Prize for this invention. Because of its safety and cost-effectiveness at documenting retinal abnormalities, fundus imaging has remained the primary method of retinal imaging.
History of retinal image processing
Current status of retinal imaging
Fundus imaging
Optical coherence tomography imaging
Time domain OCT
Frequency domain OCT
Spectral domain OCT
Swept source OCT
Areas of active research in retinal imaging
Portable, cost-effective fundus imaging
Functional imaging
Adaptive optics
Longer-wavelength OCT imaging
Clinical applications of retinal imaging
Early detection of diabetic retinopathy
Early detection of systemic disease from fundus photography
Image-guided therapy for retinal diseases with 3D OCT
Image analysis concepts for clinicians
The retinal image
Different strategies for storing ophthalmic images
Digital exchange of retinal images and DICOM
Retinal image analysis
Common image-processing steps
Preprocessing
Detection
Unsupervised and supervised image analysis
Pixel feature classification
Measuring performance of image analysis algorithms
Sensitivity and specificity
Receiver operator characteristics
The reference standard or gold standard
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Image Processing