(1)
Here, X and Y are real Banach spaces with continuous duals X ∗ and Y ∗, C and D are closed and convex, A: X → Y is a continuous linear operator, and the integral functional
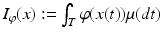 is defined on some vector subspace L p (T, μ) of X for μ, a complete totally finite measure on some measure space T. The integral operator
is defined on some vector subspace L p (T, μ) of X for μ, a complete totally finite measure on some measure space T. The integral operator 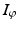 is an entropy with integrand
is an entropy with integrand ![$$\varphi:\, \mathbb{R} \rightarrow ] -\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq3.gif) a closed convex function. This provides an extremely flexible framework that specializes to most of the instances of interest and is general enough to extend results to non-Hilbert space settings. The most common examples are
a closed convex function. This provides an extremely flexible framework that specializes to most of the instances of interest and is general enough to extend results to non-Hilbert space settings. The most common examples are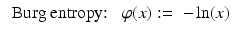
(2)

(3)
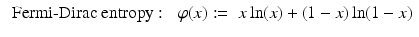
(4)
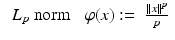
(5)
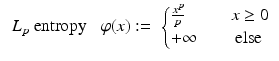
(6)
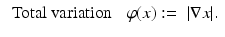
(7)
There is a rich correspondence between the algorithmic approach to applications implicit in the variational formulation ( 1) and the prevalent feasibility approach to problems. Here, one considers the problem of finding the point x that lies in the intersection of the constraint sets:
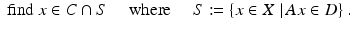 In the case where the intersection is quite large, one might wish to find the point in the intersection in some sense closest to a reference point x 0 (frequently the origin). It is the job of the objective in ( 1) to pick the element of C ∩ S that has the desired properties, that is, to pick the best approximation. The feasibility formulation suggests very naturally projection algorithms for finding the intersection whereby one applies the constraints one at a time in some fashion, e.g., cyclically, or at random [5, 30, 42, 51, 52, 119]. This is quite a powerful framework as it provides a great deal of flexibility and is amenable to parallelization for large-scale problems. Many of the algorithms for feasibility problems have counterparts for the more general best approximation problems [6, 9, 10, 58, 88]. For studies of these algorithms in nonconvex settings, see [2, 7, 8, 11–14, 29, 38, 53, 68, 78, 79, 87–89]. The projection algorithms that are central to convex feasibility and best approximation problems play a key role in algorithms for solving the problems considered here.
In the case where the intersection is quite large, one might wish to find the point in the intersection in some sense closest to a reference point x 0 (frequently the origin). It is the job of the objective in ( 1) to pick the element of C ∩ S that has the desired properties, that is, to pick the best approximation. The feasibility formulation suggests very naturally projection algorithms for finding the intersection whereby one applies the constraints one at a time in some fashion, e.g., cyclically, or at random [5, 30, 42, 51, 52, 119]. This is quite a powerful framework as it provides a great deal of flexibility and is amenable to parallelization for large-scale problems. Many of the algorithms for feasibility problems have counterparts for the more general best approximation problems [6, 9, 10, 58, 88]. For studies of these algorithms in nonconvex settings, see [2, 7, 8, 11–14, 29, 38, 53, 68, 78, 79, 87–89]. The projection algorithms that are central to convex feasibility and best approximation problems play a key role in algorithms for solving the problems considered here.
Before detailing specific applications, it is useful to state a general duality result for problem ( 1) that motivates the convex analytic approach. One of the more central tools is the Fenchel conjugate [62] of a mapping ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq4.gif) , denoted
, denoted ![$$f^{{\ast}}:\, X^{{\ast}}\rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq5.gif) and defined by
and defined by
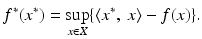 The conjugate is always convex (as a supremum of affine functions), while f = f ∗∗ | X exactly if f is convex, proper (not everywhere infinite), and lower semi-continuous (lsc) [24, 61]. Here and below, unless otherwise specified, X is a normed space with dual X ∗. The following theorem uses constraint qualifications involving the concept of the core of a set, the effective domain of a function (dom f), and the points of continuity of a function (cont f).
The conjugate is always convex (as a supremum of affine functions), while f = f ∗∗ | X exactly if f is convex, proper (not everywhere infinite), and lower semi-continuous (lsc) [24, 61]. Here and below, unless otherwise specified, X is a normed space with dual X ∗. The following theorem uses constraint qualifications involving the concept of the core of a set, the effective domain of a function (dom f), and the points of continuity of a function (cont f).
, denoted and defined byDefinition 1 (Core).
The core of a set F ⊂ X is defined by x ∈ core F if for each 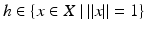 , there exists δ > 0 so that x + th ∈ F for all 0 ≤ t ≤ δ.
, there exists δ > 0 so that x + th ∈ F for all 0 ≤ t ≤ δ.
, there exists δ > 0 so that x + th ∈ F for all 0 ≤ t ≤ δ.It is clear from the definition that int F ⊂ core F. If F is a convex subset of a Euclidean space, or if F is closed, then the core and the interior are identical [27, Theorem 4.1.4].
Theorem 1 (Fenchel Duality [24, Theorems 2.3.4 and 4.4.18]).
Let X and Y be Banach spaces, let ![$$f:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq7.gif) and
and ![$$g:\, Y \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq8.gif) and let A: X → Y be a bounded linear map. Define the primal and dual values p,
and let A: X → Y be a bounded linear map. Define the primal and dual values p, ![$$d \in [-\infty,+\infty ]$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq9.gif) by the Fenchel problems
by the Fenchel problems
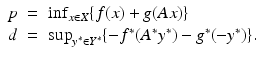
Then these values satisfy the weak duality inequality p ≥ d.
and and let A: X → Y be a bounded linear map. Define the primal and dual values p, by the Fenchel problems(8)
If f, g are convex and satisfy either
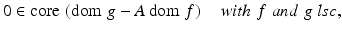
or
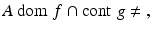
then p = d, and the supremum to the dual problem is attained if finite.
(9)
(10)
Applying Theorem 1 to problem ( 1) yields 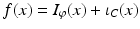 and g(y) = ι D (y) where ι F is the indicator function of the set F:
and g(y) = ι D (y) where ι F is the indicator function of the set F:
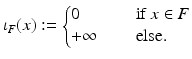
and g(y) = ι D (y) where ι F is the indicator function of the set F:(11)
The tools of convex analysis and the phenomenon of duality are central to formulating, analyzing, and solving application problems. Already apparent from the general application above is the necessity for a calculus of Fenchel conjugation in order to compute the conjugate of sums of functions. In some specific cases, one can arrive at the same conclusion with less theoretical overhead, but this is at the cost of missing out more general structures that are not necessarily automatic in other settings.
Duality has a long-established place in economics where primal and dual problems have direct interpretations in the context of the theory of zero-sum games, or where Lagrange multipliers and dual variables are understood, for instance, as shadow prices. In imaging, there is not as often an easy interplay between the physical interpretation of primal and dual problems. Duality has been used toward a variety of ends in contemporary image and signal processing, the majority of them, however, having to do with algorithms [17, 33, 34, 43–46, 54, 55, 57, 70, 73, 90, 116]. Nevertheless, the dual perspective yields new statistical or information theoretic insight into image processing problems, in addition to faster algorithms. Since the publication of the first edition of this handbook, interest in convex duality theory has only continued to grow. This is, in part, due to the now ubiquitous application of convex duality techniques to nonconvex problems; as heuristics, through appropriate convex relaxations, or otherwise [48, 114, 115]. As a measure of this growing interest, a Web of Science search for articles published between 2011 and 2013 having either “convex relaxation” or “primal dual” in the title, abstract, or keywords, returns a combined count of approximately 1,500 articles.
Modern optimization packages heavily exploit duality and convex analysis. A new trend that has matured in recent years is the field of computational convex analysis which employs symbolic, numerical, and hybrid computations of objects like the Fenchel conjugate [23, 65, 81–85, 91, 98]. Software suites that rely heavily on a convex duality approach include: CCA (Computational Convex Analysis, http://atoms.scilab.org/toolboxes/CCA) for Scilab, CVX and its extensions (http://cvxr.com/cvx/) for MATLAB (including a C code generator) [65, 91], and S-CAT (Symbolic Convex Analysis Toolkit, http://web.cs.dal.ca/~chamilto/research.html) for Maple [23]. For a review of the computational aspects of convex analysis see [84].
In this chapter, five main applications illustrate the variational analytical approach to problem solving: linear inverse problems with convex constraints, compressive imaging, image denoising and deconvolution, nonlinear inverse scattering, and finally Fredholm integral equations. A brief review of these applications is presented below. Subsequent sections develop the tools for their analysis. At the end of the chapter these applications are revisited in light of the convex analytical tools collected along the way.
The application of compressive sensing, or more generally sparsity optimization leads to a new theme that is emerging out of the theory of convex relaxations for nonconvex problems, namely direct global nonconvex methods for structured nonconvex optimization problems. Starting with the seminal papers of Candés and Tao [40, 41], the theory of convex relaxation for finding the sparsest vector satisfying an underdetermined affine constraint has concentrated on determining sufficient conditions under which the solution to a relaxation of the problem to ℓ 1 minimization with an affine equality constraint corresponds exactly to the global solution of the original nonconvex sparsity optimization problem. These conditions have been used in recent years to guarantee global convergence of simple projected gradient- and alternating projections-type algorithms for solving simpler nonconvex optimization problems whose global solutions correspond to a solution of the original problem (see [15, 16, 19, 20, 63, 69] and references therein). This is the natural point at which this chapter leaves off, and the frontier of nonconvex programming begins.
Linear Inverse Problems with Convex Constraints
Let X be a Hilbert space and 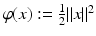 . The integral functional
. The integral functional 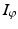 is the usual L 2 norm and the solution is the closest feasible point to the origin:
is the usual L 2 norm and the solution is the closest feasible point to the origin:
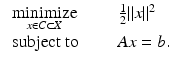
Levi, for instance, used this variational formulation to determine the minimum energy band-limited signal that matched N measurements  with the model
with the model  [77]. Note that the signal space is infinite dimensional while the measurement space is finite dimensional, a common situation in practice. Potter and Arun [100] recognized a much broader applicability of this variational formulation to remote sensing and medical imaging and applied duality theory to characterize solutions to ( 12) by
[77]. Note that the signal space is infinite dimensional while the measurement space is finite dimensional, a common situation in practice. Potter and Arun [100] recognized a much broader applicability of this variational formulation to remote sensing and medical imaging and applied duality theory to characterize solutions to ( 12) by 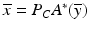 , where
, where 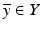 satisfies
satisfies 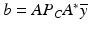 [100, Theorem 1]. Particularly attractive is the feature that when Y is finite dimensional, these formulas yield a finite dimensional approach to an infinite dimensional problem. The numerical algorithm suggested by Potter and Arun is an iterative procedure in the dual variables:
[100, Theorem 1]. Particularly attractive is the feature that when Y is finite dimensional, these formulas yield a finite dimensional approach to an infinite dimensional problem. The numerical algorithm suggested by Potter and Arun is an iterative procedure in the dual variables:
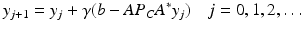
The optimality condition and numerical algorithms are explored at the end of this chapter.
. The integral functional is the usual L 2 norm and the solution is the closest feasible point to the origin:(12)
with the model [77]. Note that the signal space is infinite dimensional while the measurement space is finite dimensional, a common situation in practice. Potter and Arun [100] recognized a much broader applicability of this variational formulation to remote sensing and medical imaging and applied duality theory to characterize solutions to ( 12) by , where satisfies [100, Theorem 1]. Particularly attractive is the feature that when Y is finite dimensional, these formulas yield a finite dimensional approach to an infinite dimensional problem. The numerical algorithm suggested by Potter and Arun is an iterative procedure in the dual variables:(13)
As satisfying as this theory is, there is a crucial assumption in the theorem of Potter and Arun about the existence of 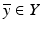 such that
such that 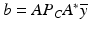 ; one need only to consider linear least squares, for an example, where the primal problem is well posed, but no such
; one need only to consider linear least squares, for an example, where the primal problem is well posed, but no such 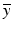 exists [22]. A specialization of Theorem 1 to the case of linear constraints facilitates the argument. The next corollary is a specialization of Theorem 1, where g is the indicator function of the point b in the linear constraint.
exists [22]. A specialization of Theorem 1 to the case of linear constraints facilitates the argument. The next corollary is a specialization of Theorem 1, where g is the indicator function of the point b in the linear constraint.
such that ; one need only to consider linear least squares, for an example, where the primal problem is well posed, but no such exists [22]. A specialization of Theorem 1 to the case of linear constraints facilitates the argument. The next corollary is a specialization of Theorem 1, where g is the indicator function of the point b in the linear constraint.Corollary 1 (Fenchel Duality for Linear Constraints).
Given any f: X → (−∞,∞], any bounded linear map A: X → Y, and any element b ∈ Y, the following weak duality inequality holds:
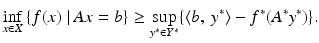 If f is lsc and convex and b ∈ core (A dom f), then equality holds and the supremum is attained if finite.
If f is lsc and convex and b ∈ core (A dom f), then equality holds and the supremum is attained if finite.
Suppose that C = X, a Hilbert space and A: X → X. The Fenchel dual to ( 12) is
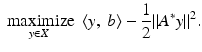
(The L 2 norm is self-dual.) Suppose that the primal problem ( 12) is feasible, that is, b ∈ range(A). The objective in ( 14) is convex and differentiable, so elementary calculus (Fermat’s rule) yields the optimal solution 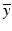 with
with 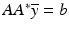 , assuming
, assuming 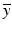 exists. If the range of A is strictly larger than that of AA ∗, however, it is possible to have b ∈ range(A) but b ∉ range(AA ∗), in which case the optimal solution
exists. If the range of A is strictly larger than that of AA ∗, however, it is possible to have b ∈ range(A) but b ∉ range(AA ∗), in which case the optimal solution 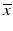 to ( 12) is not equal to
to ( 12) is not equal to 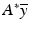 , since
, since 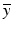 is not attained. For a concrete example see [22, Example 2.1].
is not attained. For a concrete example see [22, Example 2.1].
(14)
with , assuming exists. If the range of A is strictly larger than that of AA ∗, however, it is possible to have b ∈ range(A) but b ∉ range(AA ∗), in which case the optimal solution to ( 12) is not equal to , since is not attained. For a concrete example see [22, Example 2.1]. Imaging with Missing Data
Let 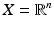 and
and 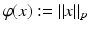 for p = 0 or p = 1. The case p = 1 is the ℓ 1 norm, and by
for p = 0 or p = 1. The case p = 1 is the ℓ 1 norm, and by 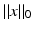 is meant the function
is meant the function
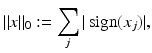 where sign(0): = 0. This yields the optimization problem
where sign(0): = 0. This yields the optimization problem
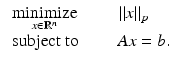
This model has received a great deal of attention recently in applications of compressive sensing where the number of measurements is much smaller than the dimension of the signal space, that is, 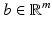 for m ≪ n. This problem is well known in statistics as the missing data problem.
for m ≪ n. This problem is well known in statistics as the missing data problem.
and for p = 0 or p = 1. The case p = 1 is the ℓ 1 norm, and by is meant the function(15)
for m ≪ n. This problem is well known in statistics as the missing data problem.For ℓ 1 optimization (p = 1), the seminal work of Candés and Tao establishes probabilistic criteria for when the solution to ( 15) is unique and exactly matches the true signal x ∗ [41]. Sparsity of the original signal x ∗ and the algebraic structure of the matrix A are key requirements. Convex analysis easily yields a geometric interpretation of these facts. The dual to this problem is the linear program
![$$\displaystyle{ \begin{array}{ll} \mathop{\mbox{ maximize }}\limits_{y \in \mathbb{R}^{m}}\qquad b^{T}y & \\ \mbox{ subject to }\qquad \left (A^{{\ast}}y\right )_{j} \in [-1,1]\quad j = 1,2,\ldots,n.&\end{array} }$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Equ16.gif)
Deriving this dual is one of the goals of this chapter. Elementary facts from linear programming guarantee that the solution includes a vertex of the polyhedron described by the constraints, and hence, assuming A is full rank, there can be at most m active constraints. The number of active constraints in the dual problem provides an upper bound on the number of nonzero elements in the primal variable – the signal to be recovered. Unless the number of nonzero elements of x ∗ is less than the number of measurements m, there is no hope of uniquely recovering x ∗. The uniqueness of solutions to the primal problem is easily understood in terms of the geometry of the dual problem, that is, whether or not solutions to the dual problem reside along the edges or faces of the polyhedron. More refined details about how sparse x ∗ needs to be in order to have a reasonable hope of exact recovery require more work, but elementary convex analysis already provides the essential intuition.
(16)
For the function 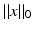 (p = 0 in ( 15)) the equivalence of the primal and dual problems is lost due to the nonconvexity of the objective. The theory of Fenchel duality still yields weak duality, but this is of limited use in this instance. The Fenchel dual to ( 15) is
(p = 0 in ( 15)) the equivalence of the primal and dual problems is lost due to the nonconvexity of the objective. The theory of Fenchel duality still yields weak duality, but this is of limited use in this instance. The Fenchel dual to ( 15) is
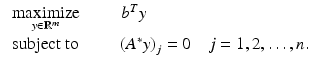
Denoting the values of the primal ( 15) and dual problems ( 17) by p and d, respectively, these values satisfy the weak duality inequality p ≥ d. The primal problem is a combinatorial optimization problem, and hence NP-hard; the dual problem, however, is a linear program, which is finitely terminating. Relatively elementary variational analysis provides a lower bound on the sparsity of signals x that satisfy the measurements. In this instance, however, the lower bound only reconfirms what is already known. Indeed, if A is full rank, then the only solution to the dual problem is y = 0. In other words, the minimal sparsity of the solution to the primal problem is zero, which is obvious. The loss of information in passing from primal to dual formulations of nonconvex problems is a common phenomenon and underscores the importance of convexity.
(p = 0 in ( 15)) the equivalence of the primal and dual problems is lost due to the nonconvexity of the objective. The theory of Fenchel duality still yields weak duality, but this is of limited use in this instance. The Fenchel dual to ( 15) is(17)
The Fenchel conjugates of the ℓ 1 norm and the function 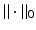 are given respectively by
are given respectively by
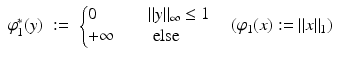
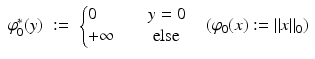
It is not uncommon to consider the function 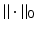 as the limit of
as the limit of 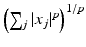 as p → 0. This suggests an alternative approach based on the regularization of the conjugates. For L and ε > 0 define
as p → 0. This suggests an alternative approach based on the regularization of the conjugates. For L and ε > 0 define
![$$\displaystyle\begin{array}{rcl} \varphi _{\epsilon,L}(y)&:= \left \{\begin{array}{@{}l@{\quad }l@{}} \epsilon \left (\frac{(L+y)\ln (L+y)+(L-y)\ln (L-y)} {2L\ln (2)} -\frac{\ln (L)} {\ln (2)} \right )\quad &\ (y \in [-L,L]) \\ +\infty \quad &\mbox{ for }\vert y\vert> L. \end{array} \right.&{}\end{array}$$” src=”/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Equ20.gif”></DIV></DIV><br />
<DIV class=EquationNumber>(20)</DIV></DIV></DIV><br />
<DIV class=Para>This is a scaled and shifted Fermi–Dirac entropy ( <SPAN class=InternalRef><A href=]() 4). It is also a smooth convex function on the interior of its domain and so elementary calculus can be used to calculate the Fenchel conjugate,
4). It is also a smooth convex function on the interior of its domain and so elementary calculus can be used to calculate the Fenchel conjugate,
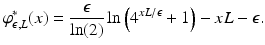
For L > 0 fixed,
![$$\displaystyle{\lim _{\epsilon \rightarrow 0}\varphi _{\epsilon,L}(y) = \left \{\begin{array}{@{}l@{\quad }l@{}} 0 \quad &y \in [-L,L]\quad \\ +\infty \quad &\mbox{ else} \end{array} \right.\quad \mbox{ and }\quad \lim _{\epsilon \rightarrow 0}\varphi _{\epsilon,L}^{{\ast}}(x) = L\vert x\vert.}$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Eque.gif) For ε > 0 fixed
For ε > 0 fixed
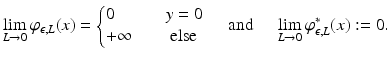 Note that
Note that 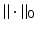 and
and 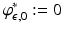 have the same conjugate, but unlike
have the same conjugate, but unlike 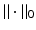 the biconjugate of
the biconjugate of 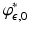 is itself. Also note that
is itself. Also note that 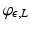 and
and 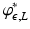 are convex and smooth on the interior of their domains for all ε, L > 0. This is in contrast to metrics of the form
are convex and smooth on the interior of their domains for all ε, L > 0. This is in contrast to metrics of the form 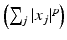 which are nonconvex for p < 1. This suggests solving
which are nonconvex for p < 1. This suggests solving
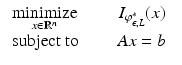
as a smooth convex relaxation of the conventional ℓ p optimization for 0 ≤ p ≤ 1. For further details see [28].
Get Clinical Tree app for offline access

are given respectively by(18)
(19)
as the limit of as p → 0. This suggests an alternative approach based on the regularization of the conjugates. For L and ε > 0 define(21)
and have the same conjugate, but unlike the biconjugate of is itself. Also note that and are convex and smooth on the interior of their domains for all ε, L > 0. This is in contrast to metrics of the form which are nonconvex for p < 1. This suggests solving(22)
Image Denoising and Deconvolution
Consider next problems of the form
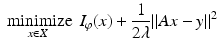
where X is a Hilbert space, ![$$I_{\varphi }:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq42.gif) is a semi-norm on X, and A: X → Y, is a bounded linear operator. This problem is explored in [17] as a general framework that includes total variation minimization [108], wavelet shrinkage [59], and basis pursuit [47]. When A is the identity, problem ( 23) amounts to a technique for denoising; here y is the received, noisy signal, and the solution
is a semi-norm on X, and A: X → Y, is a bounded linear operator. This problem is explored in [17] as a general framework that includes total variation minimization [108], wavelet shrinkage [59], and basis pursuit [47]. When A is the identity, problem ( 23) amounts to a technique for denoising; here y is the received, noisy signal, and the solution 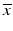 is an approximation with the desired statistical properties promoted by the objective
is an approximation with the desired statistical properties promoted by the objective 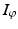 . When the linear mapping A is not the identity (for instance, A models convolution against the point spread function of an optical system) problem ( 23) is a variational formulation of deconvolution, that is, recovering the true signal from the image y. The focus here is on total variation minimization.
. When the linear mapping A is not the identity (for instance, A models convolution against the point spread function of an optical system) problem ( 23) is a variational formulation of deconvolution, that is, recovering the true signal from the image y. The focus here is on total variation minimization.
(23)
is a semi-norm on X, and A: X → Y, is a bounded linear operator. This problem is explored in [17] as a general framework that includes total variation minimization [108], wavelet shrinkage [59], and basis pursuit [47]. When A is the identity, problem ( 23) amounts to a technique for denoising; here y is the received, noisy signal, and the solution is an approximation with the desired statistical properties promoted by the objective . When the linear mapping A is not the identity (for instance, A models convolution against the point spread function of an optical system) problem ( 23) is a variational formulation of deconvolution, that is, recovering the true signal from the image y. The focus here is on total variation minimization.Total variation was first introduced by Rudin et al. [108] as a regularization technique for denoising images while preserving edges and, more precisely, the statistics of the noisy image. The total variation of an image x ∈ X = L 1(T) – for T and open subset of  – is defined by
– is defined by
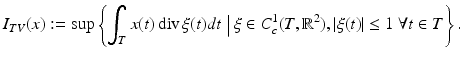 The integral functional I TV is finite if and only if the distributional derivative Dx of x is a finite Radon measure in T, in which case I TV (x) = | Dx | (T). If, moreover, x has a gradient
The integral functional I TV is finite if and only if the distributional derivative Dx of x is a finite Radon measure in T, in which case I TV (x) = | Dx | (T). If, moreover, x has a gradient 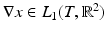 , then I TV (x) = ∫ | ∇x(t) | dt, or, in the context of the general framework established at the beginning of this chapter,
, then I TV (x) = ∫ | ∇x(t) | dt, or, in the context of the general framework established at the beginning of this chapter, 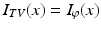 where
where 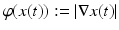 . The goal of the original total variation denoising problem proposed in [108] is then to
. The goal of the original total variation denoising problem proposed in [108] is then to
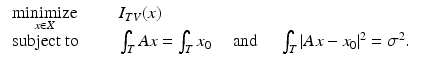
The first constraint corresponds to the assumption that the noise has zero mean and the second assumption requires the denoised image to have a predetermined standard deviation σ. Under reasonable assumptions [44], this problem is equivalent to the convex optimization problem
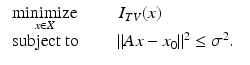
– is defined by, then I TV (x) = ∫ | ∇x(t) | dt, or, in the context of the general framework established at the beginning of this chapter, where . The goal of the original total variation denoising problem proposed in [108] is then to(24)
(25)
Several authors have exploited duality in total variation minimization for efficient algorithms to solve the above problem [43, 46, 57, 70]. One can “compute” the Fenchel conjugate of I TV indirectly by using the already mentioned property that the biconjugate of a proper, convex lsc function is the function itself: f ∗∗(x) = f(x) if (and only if) f is proper, convex, and lsc at x. Rewriting I TV as the Fenchel conjugate of some function yields
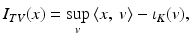 where
where
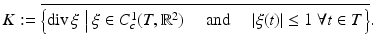 From this, it is then clear that the Fenchel conjugate of I TV is the indicator function of the convex set K, ι K .
From this, it is then clear that the Fenchel conjugate of I TV is the indicator function of the convex set K, ι K .
In [43], duality is used to develop an algorithm, with proof of convergence, for the problem
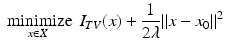
with X a Hilbert space. First-order optimality conditions for this unconstrained problem are
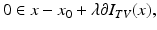
where ∂ I TV (x) is the subdifferential of I TV at x defined by
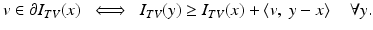 The optimality condition ( 27) is equivalent to [24, Proposition 4.4.5]
The optimality condition ( 27) is equivalent to [24, Proposition 4.4.5]
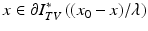
or, since I TV ∗ = ι K ,
 where
where 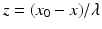 . (For the finite dimensional statement, see [71, Proposition I.6.1.2].) Since K is convex, standard facts from convex analysis determine that ∂ ι K (z) is the normal cone mapping to K at z, denoted N K (z) and defined by
. (For the finite dimensional statement, see [71, Proposition I.6.1.2].) Since K is convex, standard facts from convex analysis determine that ∂ ι K (z) is the normal cone mapping to K at z, denoted N K (z) and defined by
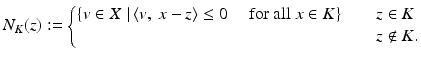 Note that this is a set-valued mapping. The resolvent
Note that this is a set-valued mapping. The resolvent 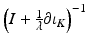 evaluated at x 0∕λ is the orthogonal projection of x 0∕λ onto K. That is, the solution to ( 26) is
evaluated at x 0∕λ is the orthogonal projection of x 0∕λ onto K. That is, the solution to ( 26) is
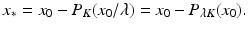 The inclusions disappear from the formulation due to convexity of K: the resolvent of the normal cone mapping of a convex set is single valued. The numerical algorithm for solving ( 26) then amounts to an algorithm for computing the projection P λ K . The tools from convex analysis used in this derivation are the subject of this chapter.
The inclusions disappear from the formulation due to convexity of K: the resolvent of the normal cone mapping of a convex set is single valued. The numerical algorithm for solving ( 26) then amounts to an algorithm for computing the projection P λ K . The tools from convex analysis used in this derivation are the subject of this chapter.
(26)
(27)
(28)
. (For the finite dimensional statement, see [71, Proposition I.6.1.2].) Since K is convex, standard facts from convex analysis determine that ∂ ι K (z) is the normal cone mapping to K at z, denoted N K (z) and defined by evaluated at x 0∕λ is the orthogonal projection of x 0∕λ onto K. That is, the solution to ( 26) isInverse Scattering
An important problem in applications involving scattering is the determination of the shape and location of scatterers from measurements of the scattered field at a distance. Modern techniques for solving this problem use indicator functions to detect the inconsistency or insolubility of an Fredholm integral equation of the first kind, parameterized by points in space. The shape and location of the object is determined by those points where the auxiliary problem is solvable. Equivalently, the technique determines the shape and location of the scatterer by determining whether a sampling function, parameterized by points in space, is in the range of a compact linear operator constructed from the scattering data.
These methods have enjoyed great practical success since their introduction in the latter half of the 1990s. Recently Kirsch and Grinberg [74] established a variational interpretation of these ideas. They observe that the range of a linear operator G: X → Y (X and Y are reflexive Banach spaces) can be characterized by the infimum of the mapping
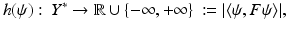 where F: = GSG ∗ for S: X ∗ → X, a coercive bounded linear operator. Specifically, they establish the following.
where F: = GSG ∗ for S: X ∗ → X, a coercive bounded linear operator. Specifically, they establish the following.
Theorem 2 ([74, Theorem 1.16]).
Let X, Y be reflexive Banach spaces with duals X ∗ and Y ∗. Let F: Y ∗ → Y and G: X → Y be bounded linear operators with F = GSG ∗ for S: X ∗ → X a bounded linear operator satisfying the coercivity condition
![$$\displaystyle{\left \vert \left \langle \varphi,\ S\varphi \right \rangle \right \vert \geq c\|\varphi \|_{X^{{\ast}}}^{2}\quad {for \,\,some}\,\,c> 0\,\, {and \,\,all}\,\,\varphi \in \mathrm{range}(G^{{\ast}}) \subset X^{{\ast}}.}$$” src=”/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Equo.gif”></DIV></DIV></DIV><SPAN class=EmphasisTypeItalic>Then for any ϕ ∈ Y ∖{0} ϕ ∈</SPAN> range <SPAN class=EmphasisTypeItalic>(G) if and only if</SPAN><br />
<DIV id=Equp class=Equation><br />
<DIV class=EquationContent><br />
<DIV class=MediaObject><IMG alt=]() 0.}$$” src=”/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Equp.gif”>
0.}$$” src=”/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Equp.gif”>
It is shown below that the infimal characterization above is equivalent to the computation of the effective domain of the Fenchel conjugate of h,
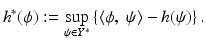
(29)
In the case of scattering, the operator F above is an integral operator whose kernel is made up of the “measured” field on a surface surrounding the scatterer. When the measurement surface is a sphere at infinity, the corresponding operator is known as the far field operator. The factor G maps the boundary condition of the governing PDE (the Helmholtz equation) to the far field pattern, that is, the kernel of the far field operator. Given the right choice of spaces, the mapping G is compact, one-to-one, and dense. There are two keys to using the above facts for determining the shape and location of scatterers: first, the construction of the test function ϕ and, second, the connection of the range of G to that of some operator easily computed from the far field operator F. The secret behind the success of these methods in inverse scattering is, first, that the construction of ϕ is trivial and, second, that there is (usually) a simpler object to work with than the infimum in Theorem 2 that depends only on the far field operator (usually the only thing that is known). Indeed, the test functions ϕ are simply far field patterns due to point sources:  , where
, where 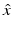 is a point on the unit sphere (the direction of the incident field), k is a nonnegative integer (the wave number of the incident field), and z is some point in space.
is a point on the unit sphere (the direction of the incident field), k is a nonnegative integer (the wave number of the incident field), and z is some point in space.
, where is a point on the unit sphere (the direction of the incident field), k is a nonnegative integer (the wave number of the incident field), and z is some point in space.The crucial observation of Kirsch is that ϕ z is in the range of G if and only if z is a point inside the scatterer. If one does not know where the scatter is, let alone its shape, then one does not know G, however, the Fenchel conjugate depends not on G but on the operator F which is constructed from measured data. In general, the Fenchel conjugate, and hence the Kirsch–Grinberg infimal characterization, is difficult to compute, but depending on the physical setting, there is a functional U of F under which the ranges of U(F) and G coincide. In the case where F is a normal operator, 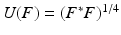 ; for non-normal F, the functional U depends more delicately on the physical problem at hand and is only known in a handful of cases. So the algorithm for determining the shape and location of a scatterer amounts to determining those points z, where
; for non-normal F, the functional U depends more delicately on the physical problem at hand and is only known in a handful of cases. So the algorithm for determining the shape and location of a scatterer amounts to determining those points z, where 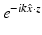 is in the range of U(F) and where U and F are known and easily computed.
is in the range of U(F) and where U and F are known and easily computed.
; for non-normal F, the functional U depends more delicately on the physical problem at hand and is only known in a handful of cases. So the algorithm for determining the shape and location of a scatterer amounts to determining those points z, where is in the range of U(F) and where U and F are known and easily computed.Fredholm Integral Equations
In the scattering application of the previous section, the prevailing numerical technique is not to calculate the Fenchel conjugate of h(ψ) but rather to explore the range of some functional of F. Ultimately, the computation involves solving a Fredholm integral equation of the first kind, returning to the more general setting with which this chapter began. Let
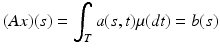 for reasonable kernels and operators. If A is compact, for instance, as in most deconvolution problems of interest, the problem is ill posed in the sense of Hadamard. Some sort of regularization technique is therefore required for numerical solutions [60, 66, 67, 76, 113]. Regularization is explored in relation to the constraint qualifications ( 9) or ( 10).
for reasonable kernels and operators. If A is compact, for instance, as in most deconvolution problems of interest, the problem is ill posed in the sense of Hadamard. Some sort of regularization technique is therefore required for numerical solutions [60, 66, 67, 76, 113]. Regularization is explored in relation to the constraint qualifications ( 9) or ( 10).
Formulating the integral equation as an entropy minimization problem yields
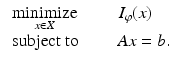
Following [22, Example 2.2], let T and S be the interval [0, 1] with Lebesgue measures μ and ν, and let a(s, t) be a continuous kernel of the Fredholm operator A mapping X: = C([0, 1]) to Y: = C([0, 1]), both equipped with the supremum norm. The adjoint operator is given by 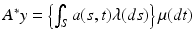 , where the dual spaces are the spaces of Borel measures, X ∗ = M([0, 1]) and Y ∗ = M([0, 1]). Every element of the range is therefore μ-absolutely continuous and A ∗ can be viewed as having its range in L 1([0, 1], μ). It follows from [105] that the Fenchel dual of ( 30) for the operator A is therefore
, where the dual spaces are the spaces of Borel measures, X ∗ = M([0, 1]) and Y ∗ = M([0, 1]). Every element of the range is therefore μ-absolutely continuous and A ∗ can be viewed as having its range in L 1([0, 1], μ). It follows from [105] that the Fenchel dual of ( 30) for the operator A is therefore
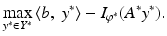
Note that the dual problem, unlike the primal, is unconstrained. Suppose that A is injective and that b ∈ range(A). Assume also that 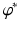 is everywhere finite and differentiable. Assuming the solution
is everywhere finite and differentiable. Assuming the solution 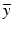 to the dual is attained, the naive application of calculus provides that
to the dual is attained, the naive application of calculus provides that
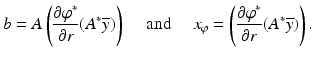
Similar to the counterexample explored in section “Linear Inverse Problems with Convex Constraints”, it is quite likely that 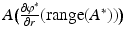 is smaller than the range of A, hence it is possible to have b ∈ range(A) but not in
is smaller than the range of A, hence it is possible to have b ∈ range(A) but not in 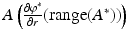 . Thus the assumption that the solution to the dual problem is attained cannot hold and the primal–dual relationship is broken.
. Thus the assumption that the solution to the dual problem is attained cannot hold and the primal–dual relationship is broken.
(30)
, where the dual spaces are the spaces of Borel measures, X ∗ = M([0, 1]) and Y ∗ = M([0, 1]). Every element of the range is therefore μ-absolutely continuous and A ∗ can be viewed as having its range in L 1([0, 1], μ). It follows from [105] that the Fenchel dual of ( 30) for the operator A is therefore(31)
is everywhere finite and differentiable. Assuming the solution to the dual is attained, the naive application of calculus provides that(32)
is smaller than the range of A, hence it is possible to have b ∈ range(A) but not in . Thus the assumption that the solution to the dual problem is attained cannot hold and the primal–dual relationship is broken.For a specific example, following [22, Example 2.2], consider the Laplace transform restricted to [0, 1]: 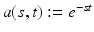 (s ∈ [0, 1]), and let
(s ∈ [0, 1]), and let 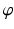 be either the Boltzmann–Shannon entropy, Fermi–Dirac entropy, or an L p norm with p ∈ (1, 2), ( 3)–( 5), respectively. Take
be either the Boltzmann–Shannon entropy, Fermi–Dirac entropy, or an L p norm with p ∈ (1, 2), ( 3)–( 5), respectively. Take ![$$b(s):=\int _{[0,1]}e^{-st}\overline{x}(t)dt$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq62.gif) for
for 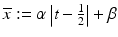 , a solution to ( 30). It can be shown that the restricted Laplace operator defines an injective linear operator from C([0, 1]) to C([0, 1]). However,
, a solution to ( 30). It can be shown that the restricted Laplace operator defines an injective linear operator from C([0, 1]) to C([0, 1]). However, 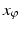 given by ( 32) is continuously differentiable and thus cannot match the known solution
given by ( 32) is continuously differentiable and thus cannot match the known solution 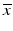 which is not differentiable. Indeed, in the case of the Boltzmann–Shannon entropy, the conjugate function and
which is not differentiable. Indeed, in the case of the Boltzmann–Shannon entropy, the conjugate function and 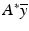 are entire hence the ostensible solution
are entire hence the ostensible solution 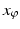 must be infinitely differentiable on [0, 1]. One could guarantee that the solution to the primal problem ( 30) is attained by replacing C([0, 1]) with L p ([0, 1]), but this does not resolve the problem of attainment in the dual problem.
must be infinitely differentiable on [0, 1]. One could guarantee that the solution to the primal problem ( 30) is attained by replacing C([0, 1]) with L p ([0, 1]), but this does not resolve the problem of attainment in the dual problem.
(s ∈ [0, 1]), and let be either the Boltzmann–Shannon entropy, Fermi–Dirac entropy, or an L p norm with p ∈ (1, 2), ( 3)–( 5), respectively. Take for , a solution to ( 30). It can be shown that the restricted Laplace operator defines an injective linear operator from C([0, 1]) to C([0, 1]). However, given by ( 32) is continuously differentiable and thus cannot match the known solution which is not differentiable. Indeed, in the case of the Boltzmann–Shannon entropy, the conjugate function and are entire hence the ostensible solution must be infinitely differentiable on [0, 1]. One could guarantee that the solution to the primal problem ( 30) is attained by replacing C([0, 1]) with L p ([0, 1]), but this does not resolve the problem of attainment in the dual problem.To recapture the correspondence between primal and dual problems it is necessary to regularize or, alternatively, relax the problem, or to require the constraint qualification 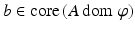 . Such conditions usually require A to be surjective, or at least to have closed range.
. Such conditions usually require A to be surjective, or at least to have closed range.
. Such conditions usually require A to be surjective, or at least to have closed range. 2 Background
As this is meant to be a survey of some of the more useful milestones in convex analysis, the focus is more on the connections between ideas than their proofs. The reader will find the proofs in a variety of sources. The presentation is by default in a normed space X with dual X ∗, though if statements become too technical, the Euclidean space variants will suffice. E denotes a finite-dimensional real vector space 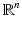 for some
for some 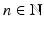 endowed with the usual norm. Typically, X will be reserved for a real infinite-dimensional Banach space. A common convention in convex analysis is to include one or both of −∞ and + ∞ in the range of functions (typically only + ∞). This is denoted by the (semi-) closed interval
endowed with the usual norm. Typically, X will be reserved for a real infinite-dimensional Banach space. A common convention in convex analysis is to include one or both of −∞ and + ∞ in the range of functions (typically only + ∞). This is denoted by the (semi-) closed interval ![$$(-\infty,+\infty ]$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq71.gif) or
or ![$$[-\infty,+\infty ]$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq72.gif) .
.
for some endowed with the usual norm. Typically, X will be reserved for a real infinite-dimensional Banach space. A common convention in convex analysis is to include one or both of −∞ and + ∞ in the range of functions (typically only + ∞). This is denoted by the (semi-) closed interval or .A set C ⊂ X is said to be convex if it contains all line segments between any two points in C: 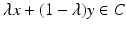 for all λ ∈ [0, 1] and x, y ∈ C. Much of the theory of convexity is centered on the analysis of convex sets, however, sets and functions are treated interchangeably through the use of level sets, epigraphs, and indicator functions. The lower-level sets of a function
for all λ ∈ [0, 1] and x, y ∈ C. Much of the theory of convexity is centered on the analysis of convex sets, however, sets and functions are treated interchangeably through the use of level sets, epigraphs, and indicator functions. The lower-level sets of a function ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq74.gif) are denoted lev ≤ α f and defined by
are denoted lev ≤ α f and defined by 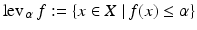 where
where 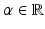 . The epigraph of a function
. The epigraph of a function ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq77.gif) is defined by
is defined by
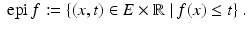 This leads to the very natural definition of a convex function as one whose epigraph is a convex set. More directly, a convex function is defined as a mapping
This leads to the very natural definition of a convex function as one whose epigraph is a convex set. More directly, a convex function is defined as a mapping ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq78.gif) with convex domain and
with convex domain and
![$$\displaystyle{f(\lambda x + (1-\lambda )y) \leq \lambda f(x) + (1-\lambda )f(y)\quad \mbox{ for any }x,y \in \mathop{\mathrm{dom\,}}\nolimits f\mbox{ and }\lambda \in [0,1].}$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_Equs.gif) A proper convex function
A proper convex function ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq79.gif) is strictly convex if the above inequality is strict for all distinct x and y in the domain of f and all 0 < λ < 1. A function is said to be closed if its epigraph is closed; whereas a lower semi-continuous (lsc) function f satisfies
is strictly convex if the above inequality is strict for all distinct x and y in the domain of f and all 0 < λ < 1. A function is said to be closed if its epigraph is closed; whereas a lower semi-continuous (lsc) function f satisfies 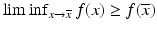 for all
for all 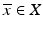 . These properties are in fact equivalent:
. These properties are in fact equivalent:
for all λ ∈ [0, 1] and x, y ∈ C. Much of the theory of convexity is centered on the analysis of convex sets, however, sets and functions are treated interchangeably through the use of level sets, epigraphs, and indicator functions. The lower-level sets of a function are denoted lev ≤ α f and defined by where . The epigraph of a function is defined by with convex domain and is strictly convex if the above inequality is strict for all distinct x and y in the domain of f and all 0 < λ < 1. A function is said to be closed if its epigraph is closed; whereas a lower semi-continuous (lsc) function f satisfies for all . These properties are in fact equivalent:Proposition 1.
The following properties of a function ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq82.gif) are equivalent:
are equivalent:
are equivalent:(i)
f is lsc.
(ii)
epi f is closed in 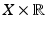 .
.
.(iii)
The level sets lev ≤α f are closed on X for each 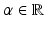 .
.
.Guide.
A principal focus is on proper functions, that is, ![$$f:\, E \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq85.gif) with nonempty domain. The indicator function is often used to pass from sets to functions
with nonempty domain. The indicator function is often used to pass from sets to functions
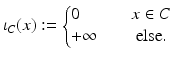 For C ⊂ X convex,
For C ⊂ X convex, ![$$f:\, C \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq86.gif) will be referred to as a convex function if the extended function
will be referred to as a convex function if the extended function
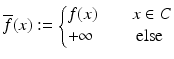 is convex.
is convex.
with nonempty domain. The indicator function is often used to pass from sets to functions will be referred to as a convex function if the extended functionLipschitzian Properties
Convex functions have the remarkable, yet elementary, property that local boundedness and local Lipschitz properties are equivalent without any additional assumptions on the function. In the following statement of this fact, the unit ball is denoted by 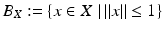 .
.
.Lemma 1.
Let ![$$f:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq88.gif) be a convex function and suppose that C ⊂ X is a bounded convex set. If f is bounded on C + δB X for some δ > 0, then f is Lipschitz on C.
be a convex function and suppose that C ⊂ X is a bounded convex set. If f is bounded on C + δB X for some δ > 0, then f is Lipschitz on C.
be a convex function and suppose that C ⊂ X is a bounded convex set. If f is bounded on C + δB X for some δ > 0, then f is Lipschitz on C. With this fact, one can easily establish the following.
Proposition 2 (Convexity and Continuity in Normed Spaces).
Let ![$$f:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq89.gif) be proper and convex, and let x ∈ dom f. The following are equivalent:
be proper and convex, and let x ∈ dom f. The following are equivalent:
be proper and convex, and let x ∈ dom f. The following are equivalent:(i)
f is Lipschitz on some neighborhood of x.
(ii)
f is continuous at x.
(iii)
f is bounded on a neighborhood of x.
(iv)
f is bounded above on a neighborhood of x.
In finite dimensions, convexity and continuity are much more tightly connected.
Proposition 3 (Convexity and Continuity in Euclidean Spaces).
Let ![$$f:\, E \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq90.gif) be convex. Then f is locally Lipschitz, and hence continuous, on the interior of its domain.
be convex. Then f is locally Lipschitz, and hence continuous, on the interior of its domain.
be convex. Then f is locally Lipschitz, and hence continuous, on the interior of its domain. Unlike finite dimensions, in infinite dimensions a convex function need not be continuous. A Hamel basis, for instance, an algebraic basis for the vector space can be used to define discontinuous linear functionals [24, Exercise 4.1.21]. For lsc convex functions, however, the correspondence follows through. The following statement uses the notion of the core of a set given by Definition 1.
Example 1 (A Discontinuous Linear Functional).
Let c 00 denote the normed subspace of all finitely supported sequences in c 0, the vector space of sequences in X converging to 0; obviously c 00 is open. Define 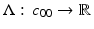 by
by 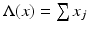 where x = (x j ) ∈ c 00. This is clearly a linear functional and discontinuous at 0. Now extend
where x = (x j ) ∈ c 00. This is clearly a linear functional and discontinuous at 0. Now extend 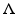 to a functional
to a functional 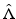 on the Banach space c 0 by taking a basis for c 0 considered as a vector space over c 00. In particular,
on the Banach space c 0 by taking a basis for c 0 considered as a vector space over c 00. In particular, ![$$C:= \hat{\Lambda }^{-1}([-1,1])$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq95.gif) is a convex set with empty interior for which 0 is a core point. Moreover,
is a convex set with empty interior for which 0 is a core point. Moreover,  and
and 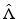 is certainly discontinuous. ■
is certainly discontinuous. ■
by where x = (x j ) ∈ c 00. This is clearly a linear functional and discontinuous at 0. Now extend to a functional on the Banach space c 0 by taking a basis for c 0 considered as a vector space over c 00. In particular, is a convex set with empty interior for which 0 is a core point. Moreover, and is certainly discontinuous. ■Proposition 4 (Convexity and Continuity in Banach Spaces).
Suppose X is a Banach space and ![$$f:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq98.gif) is lsc, proper, and convex. Then the following are equivalent:
is lsc, proper, and convex. Then the following are equivalent:
is lsc, proper, and convex. Then the following are equivalent:(i)
f is continuous at x.
(ii)
x ∈ int dom f.
(iii)
x ∈ core dom f.
The above result is helpful since it is often easier to verify that a point is in the core of the domain of a convex function than in the interior.
Subdifferentials
The analog to the linear function in classical analysis is the sublinear function in convex analysis. A function ![$$f:\, X \rightarrow [-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq99.gif) is said to be sublinear if
is said to be sublinear if
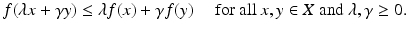 By convention,
By convention, 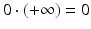 . Sometimes sublinearity is defined as a function f that is positively homogeneous (of degree 1) – i.e., 0 ∈ dom f and f(λ x) = λ f(x) for all x and all λ > 0 – and is subadditive
. Sometimes sublinearity is defined as a function f that is positively homogeneous (of degree 1) – i.e., 0 ∈ dom f and f(λ x) = λ f(x) for all x and all λ > 0 – and is subadditive
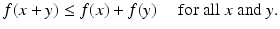
is said to be sublinear if. Sometimes sublinearity is defined as a function f that is positively homogeneous (of degree 1) – i.e., 0 ∈ dom f and f(λ x) = λ f(x) for all x and all λ > 0 – and is subadditiveExample 2 (Norms).
A norm on a vector space is a sublinear function. Recall that a nonnegative function 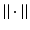 on a vector space X is a norm if
on a vector space X is a norm if
on a vector space X is a norm if(i)
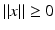 for each x ∈ X.
for each x ∈ X.
for each x ∈ X.(ii)
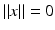 if and only if x = 0.
if and only if x = 0.
if and only if x = 0.(iii)
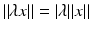 for every x ∈ X and scalar λ.
for every x ∈ X and scalar λ.
for every x ∈ X and scalar λ.(iv)
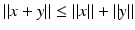 for every x, y ∈ X.
for every x, y ∈ X.
for every x, y ∈ X.A normed space is a vector space endowed with such a norm and is called a Banach space if it is complete which is to say that all Cauchy sequences converge. ■
Another important sublinear function is the directional derivative of the function f at x in the direction d defined by
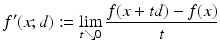 whenever this limit exists.
whenever this limit exists.
Proposition 5 (Sublinearity of the Directional Derivative).
Let X be a Banach space and let ![$$f:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq106.gif) be a convex function. Suppose that
be a convex function. Suppose that 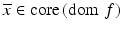 . Then the directional derivative
. Then the directional derivative 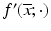 is everywhere finite and sublinear.
is everywhere finite and sublinear.
be a convex function. Suppose that . Then the directional derivative is everywhere finite and sublinear. Guide.
Another important instance of sublinear functions are support functions of convex sets, which, in turn permit local first-order approximations to convex functions. A support function of a nonempty subset S of the dual space X ∗, usually denoted σ S , is defined by 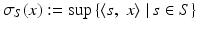 . The support function is convex, proper (not everywhere infinite), and 0 ∈ dom σ S .
. The support function is convex, proper (not everywhere infinite), and 0 ∈ dom σ S .
. The support function is convex, proper (not everywhere infinite), and 0 ∈ dom σ S .Example 3 (Support Functions and Fenchel Conjugation).
From the definition of the support function it follows immediately that, for a closed convex set C,
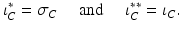 ■
■
A powerful observation is that any closed sublinear function can be viewed as a support function. This can be seen by the representation of closed convex functions via affine minorants. This is the content of the Hahn–Banach theorem, which is stated in infinite dimensions as this setting will be needed below.
Theorem 3 (Hahn–Banach: Analytic Form).
Let X be a normed space and 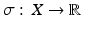 be a continuous sublinear function with dom σ = X. Suppose that L is a linear subspace of X and that the linear function
be a continuous sublinear function with dom σ = X. Suppose that L is a linear subspace of X and that the linear function 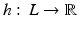 is dominated by σ on L, that is σ ≥ h on L. Then there is a linear function minorizing σ on X, that is, there exists a x ∗ ∈ X ∗ dominated by σ such that
is dominated by σ on L, that is σ ≥ h on L. Then there is a linear function minorizing σ on X, that is, there exists a x ∗ ∈ X ∗ dominated by σ such that 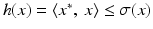 for all x ∈ L.
for all x ∈ L.
be a continuous sublinear function with dom σ = X. Suppose that L is a linear subspace of X and that the linear function is dominated by σ on L, that is σ ≥ h on L. Then there is a linear function minorizing σ on X, that is, there exists a x ∗ ∈ X ∗ dominated by σ such that for all x ∈ L. Guide.
The proof can be carried out in finite dimensions with elementary tools, constructing x ∗ from h sequentially by one-dimensional extensions from L. See [72, Theorem C.3.1.1] and [24, Proposition 2.1.18]. The technique can be extended to Banach spaces using Zorn’s lemma and a verification that the linear functionals so constructed are continuous (guaranteed by the domination property) [24, Theorem 4.1.7]. See also [110, Theorem 1.11]. ■
An important point in the Hahn–Banach extension theorem is the existence of a minorizing linear function, and hence the existence of the set of linear minorants. In fact, σ is the supremum of the linear functions minorizing it. In other words, σ is the support function of the nonempty set
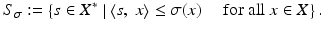 A number of facts follow from Theorem 3, in particular the nonemptiness of the subdifferential, a sandwich theorem and, thence, Fenchel Duality (respectively, Theorems 5, 7, and 12). It turns out that the converse also holds, and thus these facts are actually equivalent to nonemptiness of the subdifferential. This is the so-called Hahn–Banach/Fenchel duality circle.
A number of facts follow from Theorem 3, in particular the nonemptiness of the subdifferential, a sandwich theorem and, thence, Fenchel Duality (respectively, Theorems 5, 7, and 12). It turns out that the converse also holds, and thus these facts are actually equivalent to nonemptiness of the subdifferential. This is the so-called Hahn–Banach/Fenchel duality circle.
As stated in Proposition 5, the directional derivative is everywhere finite and sublinear for a convex function f at points in the core of its domain. In light of the Hahn–Banach theorem, then 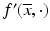 can be expressed for all d ∈ X in terms of its minorizing function:
can be expressed for all d ∈ X in terms of its minorizing function:
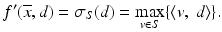 The set S for which
The set S for which 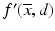 is the support function has a special name: the subdifferential of f at
is the support function has a special name: the subdifferential of f at 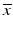 . It is tempting to define the subdifferential this way, however, there is a more elemental definition that does not rely on directional derivatives or support functions, or indeed even the convexity of f. The correspondence between directional derivatives of convex functions and the subdifferential below is a consequence of the Hahn–Banach theorem.
. It is tempting to define the subdifferential this way, however, there is a more elemental definition that does not rely on directional derivatives or support functions, or indeed even the convexity of f. The correspondence between directional derivatives of convex functions and the subdifferential below is a consequence of the Hahn–Banach theorem.
can be expressed for all d ∈ X in terms of its minorizing function: is the support function has a special name: the subdifferential of f at . It is tempting to define the subdifferential this way, however, there is a more elemental definition that does not rely on directional derivatives or support functions, or indeed even the convexity of f. The correspondence between directional derivatives of convex functions and the subdifferential below is a consequence of the Hahn–Banach theorem. Definition 2 (Subdifferential).
For a function ![$$f:\, X \rightarrow (-\infty,+\infty ]\,$$](/wp-content/uploads/2016/04/A183156_2_En_7_Chapter_IEq116.gif)




Related posts:

Stay updated, free articles. Join our Telegram channel
Full access? Get Clinical Tree